It turns a collection of text documents into a scipy.sparse matrix holding token occurrence counts (or binary occurrence information), possibly normalized as token frequencies if norm=’l1’ or projected on the euclidean unit sphere if norm=’l2’.
Description
Description
| Status | Subtype | Assigned | Task | ||
|---|---|---|---|---|---|
| Open | None | T145812 Implement ~100 most important hash vector features in editquality models | |||
| Resolved | Spike | Sabya | T128087 [Spike] Investigate HashingVectorizer |
Event Timeline
Comment Actions
Just put together this example https://github.com/wiki-ai/revscoring/blob/master/ipython/hashing_vectorizer.ipynb
Comment Actions
I just worked with @Sabya to put together these notes about next steps for the work: https://etherpad.wikimedia.org/p/sparse_features
I also updated the ipython notebook to include a feature_importance histogram. See the bottom of https://github.com/wiki-ai/revscoring/blob/master/ipython/hashing_vectorizer.ipynb
It looks like there is obviously a step at 0.001. And that cuts out about 95% of the hashes. Essentially it's ~ 100 features that end up being useful in this toy example.
Comment Actions
For the record, the IRC log is here:
http://bots.wmflabs.org/~wm-bot/logs/%23wikimedia-ai/20160710.txt
Comment Actions
@Halfak I've plotted the histogram of the GBC (without other 77 features). Here is the exported version of the ipython output. I am exporting it and attaching here to capture the historical snapshot. Do you think there is an obvious step at 0.0005 (three zeros before five that is).
The notebook code can be found here:
https://github.com/wiki-ai/revscoring/blob/poc_hashing_vector/poc/hv/plot_gbc.ipynb
Comment Actions
@Sabya, it looks like setting a cutoff at 0.0005 would work to me. How many features are we left with if you set a threshold there? Eyeballing and ball-parking looks to me like 500 or so. That should work just fine for our purposes. I think it would be great to try building the full model (with the other 77) using the top 50, 100, 250, 500 features from this selection strategy to see what fitness tradeoffs we're making. Does that make sense?
BTW, I made some progress on T132580. I'm hoping to pick that up again this week. Once that is done, we should be able to quickly move your work into production :)
Comment Actions
I think I got it wrong about the threshold in my above comment. Now I get it as the threshold is to keep the features whose importance is >= threshold, right? 0.0005 yields 375 features. I updated the notebook to show these features.
https://github.com/wiki-ai/revscoring/blob/poc_hashing_vector/poc/hv/plot_gbc.ipynb
Now I will need to think about how to use these 375 features along with the original 77. Any idea about that?
Comment Actions
+1 for >= threshold.
I think we'll want to try training the GradientBoosting model again with 77 + 375 features. You'll likely need to flatten the vector. E.g. something like this (totally untested)
# ... original_features = # ... import the original 77 selected_hash_features = sfm.transform(hash_features) combined_features = numpy.column_stack(original_features, selected_hash_features) gbc = GradientBoostingClassifier(...) gbc.fit(combined_features, labels) # ... end then do testing again
Comment Actions
I'm getting pretty close with T132580. I'll likely want to use this work to generate a demo that the system works. I'll likely pick that up the next time that I get to sit down and work on this stuff. That'll likely be in a couple of days (8/26).
Comment Actions
I got a bit of a start here: http://paws-public.wmflabs.org/paws-public/User:EpochFail/projects/vectors_demo/damage_detection_test.ipynb
I'll be implementing the whole tfidf training process soon. It will be interesting to compare that feature selection strategy with the model-based selection.
Comment Actions
@Halfak: results are out. Here you go:
Length of get_support: 0
Correct Predictions: 3596 Total Predictions: 3728 Score: 96.45922746781116
average precision score: 0.41879268202 roc auc score: 0.919815796818
Length of get_support: 50
Correct Predictions: 3594 Total Predictions: 3728 Score: 96.40557939914163
average precision score: 0.382503808541 roc auc score: 0.915456129038
Length of get_support: 75
Correct Predictions: 3592 Total Predictions: 3728 Score: 96.35193133047211
average precision score: 0.364340987284 roc auc score: 0.913182942439
Length of get_support: 100
Correct Predictions: 3590 Total Predictions: 3728 Score: 96.29828326180258
average precision score: 0.355468310194 roc auc score: 0.91175570462
Length of get_support: 250
Correct Predictions: 3590 Total Predictions: 3728 Score: 96.29828326180258
average precision score: 0.349295840068 roc auc score: 0.910453578681
Length of get_support: 500
Correct Predictions: 3590 Total Predictions: 3728 Score: 96.29828326180258
average precision score: 0.362492718088 roc auc score: 0.908482585389
You can see the notebook here:
https://github.com/wiki-ai/revscoring/blob/332566fc4cd35749e390beea00540792177ba35c/poc/hv/poc_hashing_vectorizer.ipynb
Comment Actions
New results with below params:
gbc = GradientBoostingClassifier(n_estimators=700, max_depth=7, learning_rate=0.01) sample_weight=[18939 / (796 + 18939) if l == 'True' else 796 / (796 + 18939) for l in labels]
Length of get_support: 0
Correct Predictions: 3594 Total Predictions: 3728 Score: 96.40557939914163
average precision score: 0.397572508667 roc auc score: 0.910173520552
Length of get_support: 50
Correct Predictions: 3596 Total Predictions: 3728 Score: 96.45922746781116
average precision score: 0.371622175134 roc auc score: 0.906081399713
Length of get_support: 71
Correct Predictions: 3592 Total Predictions: 3728 Score: 96.35193133047211
average precision score: 0.355803409751 roc auc score: 0.904444358898
Length of get_support: 108
Correct Predictions: 3590 Total Predictions: 3728 Score: 96.29828326180258
average precision score: 0.363625583156 roc auc score: 0.902835227655
Length of get_support: 262
Correct Predictions: 3590 Total Predictions: 3728 Score: 96.29828326180258
average precision score: 0.331128436243 roc auc score: 0.895407431646
Length of get_support: 776
Correct Predictions: 3591 Total Predictions: 3728 Score: 96.32510729613733
average precision score: 0.351808104154 roc auc score: 0.893947472259
Comment Actions
Interesting. It could be that we're already getting all the signal that the new features can provide. I'm guessing that some tuning could help here. E.g. some different parameters for the estimator might work better when the hash vectors are included.
See http://scikit-learn.org/stable/modules/grid_search.html
Right now, we search these params:
GradientBoostingClassifier:
class: sklearn.ensemble.GradientBoostingClassifier
params:
n_estimators: [100, 300, 500, 700]
max_depth: [1, 3, 5, 7]
max_features: ["log2"]
learning_rate: [0.01, 0.1, 0.5, 1]But I think we should expand that to something like this:
GradientBoostingClassifier:
class: sklearn.ensemble.GradientBoostingClassifier
params:
n_estimators: [500, 700, 900, 1100]
max_depth: [5, 7, 9, 11]
max_features: ["log2"]
learning_rate: [0.001, 0.005, 0.01, 0.1]This shifts towards more estimators, more depth and slower learn rates. If we find that the extreme values tend to get selected, then we might want to shift more and try again.
Comment Actions
Here is the link to compare the results against:
https://ores.wmflabs.org/v2/scores/enwiki/damaging/?model_info=test_stats
Comment Actions
Here are the results from the grid search:
Best ROC AUC Score:
0.910445174634
Best Params:
{'max_depth': 5, 'n_estimators': 1100, 'learning_rate': 0.01, 'max_features': 'log2'}For reference, the search configuration was:
param_grid = dict(n_estimators = [500, 700, 900, 1100],
max_depth = [5, 7, 9, 11],
max_features = ["log2"],
learning_rate = [0.001, 0.005, 0.01, 0.1])
model = GradientBoostingClassifier()
sample_weight=[18939 / (796 + 18939) if l == 'True' else 796 / (796 + 18939) for l in labels]
grid = GridSearchCV(model, param_grid, scoring = 'roc_auc', fit_params = {'sample_weight': sample_weight}, cv = 2)
grid.fit(features.toarray(), labels)
print(grid.best_score_)
print(grid.best_params_)50 HV features were used along with 77 original features.
Threshold for selecting those 50 features was:0. 00435
Comment Actions
OK. I have a weird proposal that is going to be more work. It looks like we're solidly doing well with learn_rate=0.01, but that increasing the estimators gets us increases in fitness. This is what the docs for GradientBoostingClassifier suggest.
So, my goal is to find out (1) where the returns on increasing estimators falls off and (2) how the # of HV features affects this return.
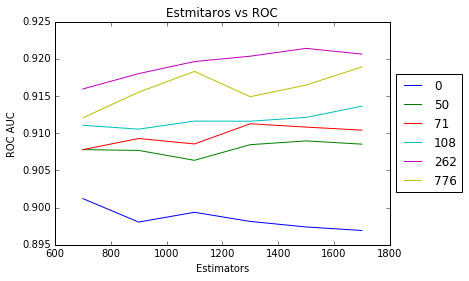
I propose making a graph of ROC AUC scores for the models you described above. (length of get_support = 0, 50, 71, 108, 262, 776) The y axis reports ROC AUC scores and the X axis reports the n_estimators value. I'm imagining that we'd want n_estimators values for 700, 900, 1100, 1300, 1500, 1700. Using this plot, we'll be able to visually identify whether or not the HV features are actually giving us an improvement in fitness. Does that make sense?
Comment Actions
Per our conversation in chat, I think that we should confirm that the ordering in the graph is right given that it seems to disagree with past discussion (T128087#2600696). Once the graph is confirmed good, let's call this resolved and get to work implementing it in the revscoring models! :)
Comment Actions
Plots with and without sample weights:
The plots below also include roc score for greater number of estimators to find where the return flattens.
Comment Actions
Looks good. Seems like a clear win here. I think that we're sure to see an ROC drop due to the increased weighting of fewer observations. But I wonder if we could avoid that. I created a task to explore that. See T145809
Comment Actions
Also, regarding ROC score difference between T128087#2600696 and current: current one is correct. GridSearchCV is calculating it. Earlier I was first calculating myself using roc_auc_score.
Something must have gone wrong there; which I'll figure out.
But I think for now we can close this and start making progress on next step.