Figure out a useful tokenization strategy for CJK languages.
Description
Description
| Status | Subtype | Assigned | Task | ||
|---|---|---|---|---|---|
| Open | None | T227094 Update RC Filters for new ORES capacities (July, 2019) | |||
| Resolved | SBisson | T225561 Update ORES thresholds for nlwiki | |||
| Open | None | T223273 Update srwiki thresholds for goodfaith model | |||
| Resolved | SBisson | T225562 Deploy ORES filters for zhwiki | |||
| Open | None | T225563 Deploy ORES filters for jawiki | |||
| Resolved | Halfak | T224484 ORES deployment: Early June | |||
| Resolved | Halfak | T224481 Train/test zhwiki editquality models | |||
| Resolved | Halfak | T223382 Improvements to ORES localization and support | |||
| Resolved | Halfak | T109366 Chinese language utilities | |||
| Open | None | T111178 Generate stopwords for CJK languages | |||
| Resolved | Pavol86 | T111179 Tokenization of "word" things for CJK |
Event Timeline
Comment Actions
Perhaps considering a Hidden Markov Model implementation. I believe Lucene 3.0 uses this approach for its CJK Tokenization.
Comment Actions
Know where we could find one of those in python? I suppose we could also build our own if we had a sufficiently comprehensive set of words to learn the transition probabilities from.
Comment Actions
At first glance, I would say we could use some treebanks such as https://catalog.ldc.upenn.edu/LDC2013T21 for Chinese, not sure about the others. Alternatively, there's http://cjklib.org/0.3/ which may be worth looking into as a starting point.
Comment Actions
Although thinking about this more, you have to consider that ambiguity of meaning when segmenting "words" can lead to poor information retrieval issues.
https://www.hathitrust.org/blogs/large-scale-search/multilingual-issues-part-1-word-segmentation
That being said, I came across an article about using Wikipedia as a resource for doing n-gram mutual information for word segmenting on Chinese. This method could potentially be applied to other languages.
http://www.cs.otago.ac.nz/homepages/andrew/papers/2009-9.pdf
Comment Actions
Slightly unrelated but I thought this was interesting:
http://batterseapower.github.io/pinyin-toolkit/
And it leverages cjklib :)
Comment Actions
We can probably use ngrams in hashing vectorization to capture this type of signal. That might be easier than explicitly splitting words. See T128087
Then again, splitting words would be good for dictionary lookups.
Comment Actions
See related work here: https://www.mediawiki.org/wiki/User:TJones_(WMF)/Notes/Nori_Analyzer_Analysis
Comment Actions
I can see that this thread is quite old, so first of all only couple of notes that we can talk about with Aaron on Thursday call..
NOTES:
- this post nicely summarizes approaches for CJK tokenization I found in papers/posts/blogs etc. : http://www.solutions.asia/2016/10/japanese-tokenization.html
- as mentioned previously Apache Lucene has a CJK tokenization strategy that could be adapted; they use bigrams (N-Gram approach from previous post?): https://lucene.apache.org/core/8_5_2/analyzers-common/index.html
- we could use some ideas from this post (use of nltk + chargua) : https://stackoverflow.com/questions/43576136/how-can-i-use-python-nltk-to-identify-collocations-among-single-characters
- or ngram parameters minn/maxn from fasttext (if we want to implement it in python-mw) and extract ngrams ("idea in progress"), see links:
- https://fasttext.cc/docs/en/options.html
- here they mentione tokenization of some east asian languages : https://fasttext.cc/docs/en/crawl-vectors.html
- from fasttext post I got to standford nlp projects:
- word segmenter for chinese and arabic implemented also in nltk : https://nlp.stanford.edu/software/segmenter.html
- and MY FAVOURITE Stanza project: https://github.com/stanfordnlp/stanza
I am not yet sure how to exatly we can use it, but what I like about Stanza is:
- it's recent (paper published 2020)
- it has nice documentation
- it's not only a wrapper for some other C#/Java/etc code(if I understand it correctly..)
- it has research/scientific background
- from spacy stanza github
The Stanford models achieved top accuracy in the CoNLL 2017 and 2018 shared task, which involves tokenization, part-of-speech tagging, morphological analysis, lemmatization and labelled dependency parsing in 58 languages.
- it always sounds better when you implement something tested at Stanford/MIT/Harwad/etc. then just some commonly used approach :)
Useful links:
- Github: https://github.com/stanfordnlp/stanza
- there is Spacy and Spacy STANZA - Spacy is main project Stanza is part of it (I think? not sure yet) https://github.com/explosion/spacy-stanza
- I do not understand yet how they do tokenization for east asian languages, but they have them listed in models : https://stanfordnlp.github.io/stanza/models.html
- arxiv paper related to Stanza : https://arxiv.org/pdf/2003.07082.pdf
Short summary
If the idea is to make only a slight change to code to improve python-mw and drafttopic then let's focus on extracting bigrams. If the idea is to test couple of approaches to create an "east asian languages tokenization strategy" then let's try both with focus on understanding how does Stanza work and how can we use it.
Comment Actions
@Pavol86 Stanza has poor performance compare to other Chinese word segmentation tool such as Jieba, pkuseg and THULAC. (I still cannot forget how horrible CoreNLP’s processing time is for CWS). HMM should also be the worst choice to be considered. There are significant difference between Chinese, Japanese and Korean tokenization strategy, and treating them as one "east asian languages tokenization strategy" will never work in my opinion.
I think we can start by focusing how pkuseg works on Chinese word segmentation and how Mecab works for Japanese word segmentation. (I am not sure about Korean, as I do not speak Korean, but Mecab-ko can be a good start)
Comment Actions
@VulpesVulpes825 thank you for your response. Do you know if there are any datasets/dictionaries that are used for benchmarking of tokenization methods?
Japanese:
I found a common interface for 3 popular Japanese tokenizers:
https://github.com/Kensuke-Mitsuzawa/JapaneseTokenizers
It groups Mecab(mentioned by you and in FastText documentation), Juman and KyTea
I want to compare performance of the most popular Chinese and Japanese tokenizers, but I need some bechmarking dataset.
Chinese
I found this dataset from 2005 (quite old, but I guess for language dataset it should not matter that much):
http://sighan.cs.uchicago.edu/bakeoff2005/
I found pkuseg(mentioned also by you), THULAC, jieba and Stanford word segmeter(used in Fasttext documentation). The package authors in THULAC listed the dataset mentioned above.
- pkuseg https://github.com/lancopku/pkuseg-python
- THULAC https://github.com/thunlp/THULAC-Python
- jieba https://github.com/fxsjy/jieba
- Stanford word segmenter https://nlp.stanford.edu/software/segmenter.html
Korean
so far I only found KoNLPy https://konlpy.org/en/latest/
Vietnamese
vietseg https://github.com/manhtai/vietseg
pivi ? https://github.com/thangntt2/pivi
Summary:
Let's focus on Chinese and Japanese. Do you know of any Japanse dataset?
Comment Actions
Note
Export from jupyter notebook after I struggled with JapaneseTokenizers I decided to get at least 1 working - hardest part is to find some free segmented dataset, now I know why this task is still opened :) - I forgot that nothing is free in Japan and OpenSource is a very new concept.. (my exp. ...)
1. JAPANESE
1.1. mecab
popular and fastest, slightly worse accuracy than other state-of-the-art segmeters, but I was able to get it running...
- speed/installation comparissons :
- instructions from https://taku910.github.io/mecab/#install-unix
- MUST BE SU!!!
wget -O mecab-0.996.tar.gz "https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7cENtOXlicTFaRUE" tar zxvf mecab-0.996.tar.gz cd mecab-0.996 && ./configure && make && make check sudo make install
1.2. mecab ipadic dictionary
dictionary is not included in mecab, not sure what ipadic stands for (jippon/nippon dictionary?)
wget -O mecab-ipadic-2.7.0-20070801.tar.gz "https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7MWVlSDBCSXZMTXM" tar zxvf mecab-ipadic-2.7.0-20070801.tar.gz cd mecab-ipadic-2.7.0-20070801 &&./configure --with-charset=utf8 && make && make check sudo make install
1.3 testing corpus
fees for text corpuses, even those that look like free need some CD/DVD from some org. for which you have to register and request it etc.; BCCWJ seems popular but I spent my Sunday on trying to find a way to download it - no way, but I can request CD/DVD :D :D :D
https://www.jaist.ac.jp/project/NLP_Portal/doc/LR/lr-cat-e.html
https://lionbridge.ai/datasets/japanese-language-text-datasets/
Dataset
Universal Dependecy datasets
For studying the structure of sentences in languages? - structure/tree/hierarchy of words(I think), they use special notation - CoNLL-U
https://pypi.org/project/conllu/
conda install -c conda-forge conllu
- from spacy post https://github.com/explosion/spaCy/issues/3756 I got to https://github.com/UniversalDependencies/UD_Japanese-GSD
- from https://github.com/megagonlabs/ginza I got to https://github.com/UniversalDependencies/UD_Japanese-BCCWJ
import MeCab from conllu import parse_incr
jp_train_data_loc = "UD_Japanese-GSD/ja_gsd-ud-train.conllu" jp_train_data = open(jp_train_data_loc, "r", encoding="utf-8")
senteces_list = [] tokens = [] for tokenlist in parse_incr(jp_train_data): # sentences senteces_list.append(tokenlist.metadata['text']) # token list of lists temp = [] for token_id in range(len(tokenlist)): temp.append(tokenlist[token_id]["form"]) tokens.append(temp)
print(senteces_list[0])
ホッケーにはデンジャラスプレーの反則があるので、膝より上にボールを浮かすことは基本的に反則になるが、その例外の一つがこのスクープである。
print(tokens[0])
['ホッケー', 'に', 'は', 'デンジャラス', 'プレー', 'の', '反則', 'が', 'ある', 'の', 'で', '、', '膝', 'より', '上', 'に', 'ボール', 'を', '浮かす', 'こと', 'は', '基本', '的', 'に', '反則', 'に', 'なる', 'が', '、', 'その', '例外', 'の', '一', 'つ', 'が', 'この', 'スクープ', 'で', 'ある', '。']
#-Owakati (separate into words) #-Oyomi (Assign readings) #-Ochasen (ChaSen compatible) #-Odump (Full information dump) wakati = MeCab.Tagger("-Owakati") print(wakati.parse(senteces_list[0]).split())
['ホッケー', 'に', 'は', 'デンジャラスプレー', 'の', '反則', 'が', 'ある', 'ので', '、', '膝', 'より', '上', 'に', 'ボール', 'を', '浮かす', 'こと', 'は', '基本', '的', 'に', '反則', 'に', 'なる', 'が', '、', 'その', '例外', 'の', '一つ', 'が', 'この', 'スクープ', 'で', 'ある', '。']
2. Chinese
2.1. pkuseg
english documentation https://github.com/lancopku/pkuseg-python/blob/master/readme/readme_english.md
pip install pkuseg
2. Dataset
Dataset from Chinese word segmentation workshop http://sighan.cs.uchicago.edu/bakeoff2005/ , tar.bz2 is not available.
Training dataset is separated by spaces, see ".. of course spaces will be removed." in http://sighan.cs.uchicago.edu/bakeoff2005/data/instructions.php.html.
wget -O icwb2-data.zip "http://sighan.cs.uchicago.edu/bakeoff2005/data/icwb2-data.zip" # sudo apt-get install unzip unzip icwb2-data.zip
import pkuseg seg = pkuseg.pkuseg() #load the default model text = seg.cut("我爱北京天安门") print(text)
['我', '爱', '北京', '天安门']
dataset_loc = "icwb2-data/training/msr_training.utf8"
f = open(dataset_loc, "r") tokenized_content = f.read().replace("\n","").split(" ") content = "".join(tokenized_content)
print(content[:50])
“人们常说生活是一部教科书,而血与火的战争更是不可多得的教科书,她确实是名副其实的‘我的大学’。“心
print(tokenized_content[:34])
['“', '人们', '常', '说', '生活', '是', '一', '部', '教科书', ',', '而', '血', '与', '火', '的', '战争', '更', '是', '不可多得', '的', '教科书', ',', '她', '确实', '是', '名副其实', '的', '‘', '我', '的', '大学', '’', '。“', '心']
print(seg.cut(content[:50]))
['“', '人们', '常', '说', '生活', '是', '一', '部', '教科书', ',', '而', '血', '与', '火', '的', '战争', '更', '是', '不可多得', '的', '教科书', ',', '她', '确实', '是', '名副其实', '的', '‘', '我', '的', '大学', '’', '。', '“', '心']
3. Korean
3.1. KoNLPy
includes following popular tokenizers : Hannanum, Kkma, Komoran, Mecab-ko, Okt
pip install konlpy
3.2. Dataset
Sejong corpus
National balanced corpus, ~2GB, used by many git repos and papers
git clone https://github.com/coolengineer/sejong-corpus make all make dict
KoNLPy built-in corpus
Documentation p.13-14:
https://konlpy.org/_/downloads/en/latest/pdf/
from konlpy.corpus import kolaw from konlpy.corpus import kobill
Mecab-ko dictionary
from https://konlpy.org/en/v0.3.0/install/:
wget https://bitbucket.org/eunjeon/mecab-ko-dic/downloads/mecab-ko-dic-1.6.1-20140814.tar.gz tar zxfv mecab-ko-dic-1.6.1-20140814.tar.gz cd mecab-ko-dic-1.6.1-20140814 ./configure sudo ldconfig make sudo sh -c 'echo "dicdir=/usr/local/lib/mecab/dic/mecab-ko-dic" > /usr/local/etc/mecabrc' sudo make install
Usefull note
From https://nlp.stanford.edu/fsnlp/korean.html :
There are two main components in Korean orthography: the eumjeol and the eojeol. The eumjeol can be thought of as a syllable, consisting of either a hanja (Chinese characters, now used only in Korea: North Korean orthography does not use them) or a hangul syllable (hangul being the name of the Korean alphabet: a hangul is composed of one to three jamo). An eojeol is sequence of one or more eumjeol, separated by spaces. A eojeol can represent a single inflected lexeme (Korean is quite agglutinative) or several lexemes. The placement of spaces in Korean is often a matter of style than morphology, and often appear where a pause in speech would be heard. The components of an eojeol, the Korean analog of "morphemes", are called hyung-tae-so.
from konlpy.corpus import kolaw c = kolaw.open('constitution.txt').read() print(c[:40])
대한민국헌법 유구한 역사와 전통에 빛나는 우리 대한국민은 3·1운동으로
from konlpy.tag import Mecab mecab = Mecab() print(mecab.morphs(c[:40])) print(mecab.nouns(c[:40]))
['대한민국', '헌법', '유구', '한', '역사', '와', '전통', '에', '빛나', '는', '우리', '대한', '국민', '은', '3', '·', '1', '운동', '으로'] ['대한민국', '헌법', '역사', '전통', '우리', '국민', '운동']
python
4. Evaluation
I do not yet know how to evaluate the word segemntation results (maybe this? https://segeval.readthedocs.io/en/latest/)
Comment Actions
@zhuyifei1999, I wonder if you'd be able to help us evaluate the quality of the Chinese word segmentation?
@jeena, would you be able to help us evaluate the quality of Japanese word segmentation?
@Pavol86, I think a next step we can do here is to look at our tokenizer (https://github.com/halfak/deltas/blob/master/deltas/tokenizers/wikitext_split.py) and consider how we can implement these word segmenters in an intelligent way. E.g. should we apply word segmentation generally across all wiki tokenization? If we run into chinese text in, say English Wikipedia, we might segment the words of it. If we do that how much will it slow down the tokenizer on latin text? Would it increase the memory footprint substantially? It might make more sense to have a context specific tokenizer that we apply based on the target language.
Comment Actions
@Pavol86, do you think you could create some samples of content that has been segmented? E.g., I'm imagining ~10 example paragraphs from relevant wikis presented next to the segmented/processed text? Maybe we could set up a good spreadsheet or a wiki page to allow people to make notes.
Comment Actions
@Pavol86, @Halfak. Sorry for the late reply. I am a little busy recently.
Chinese
I have done a Chinese CWS tool performance recently (two months ago) and I have pasted the result from my report. The database is bakeoff2005's Simplified Chinese PKU corpus.
| Package | Precision | Recall | F-Measure | Speed |
|---|---|---|---|---|
| pkuseg | 0.962 | 0.926 | 0.934 | 3.60s |
| THULAC | 0.917 | 0.815 | 0.923 | 0.39s |
| CoreNLP | 0.901 | 0.894 | 0.897 | 3s++ |
| jieba | 0.850 | 0.784 | 0.816 | 0.23s |
Conclusion
For accuracy, choose pkuseg or THULAC. If you want to choose long term support, choose jieba, as Chinese university project tend to not live and move on to a different CWS pakage for every few years. What I am worrying is because Chinese Wikimedia projects are using mixed characters, mixing Simplified and Traditional Chinese together, this may decrease CWS tool accuracy.
Japanese
Corpus
There are two corpus that you can download for free from Kyoto University:
Result
I have copied result from RNN 言語モデルを用いた日本語形態素解析の実用化, an article from Kyoto University in 2016
| Package | Analys data F-measure | Precession data F-measure |
|---|---|---|
| MECAB | 97.89 | 97.91 |
| JUMAN | 97.99 | 98.00 |
And speed from one webpage that conduct an comparision between different Japanese CWS tool in 2019
| Package | Time |
|---|---|
| MeCab | 0.226s |
| JUMAN | 3.661s |
| JUMAN++(v2) | 6.706s |
| Sudachi | 4.119s |
| SudachiPy | 74.872s |
Conclusion
For speed, choose Mecab. For long term support, choose JUMAN++, as its F-measure is similar to Mecab and is in continous development, whereas Mecab's development stopped in 2018.
P.S
We should apply general tokenizer for all sites except CJK languages since CJK languages do not use space as word boundary. It is not necessary to have a Chinese CWS tool for only few sentences on Wikipedia, as sometimes they are there to original sentence reference or displaying what the object is called in Chinese. I think it may best to just treat Chinese in English Wikipedia as a whole word block.
Comment Actions
@Halfak
Looking at the Japanese result posted by @Pavol86
['ホッケー', 'に', 'は', 'デンジャラスプレー', 'の', '反則', 'が', 'ある', 'ので', '、', '膝', 'より', '上', 'に', 'ボール', 'を', '浮かす', 'こと', 'は', '基本', '的', 'に', '反則', 'に', 'なる', 'が', '、', 'その', '例外', 'の', '一つ', 'が', 'この', 'スクープ', 'で', 'ある', '。']
'に', 'は' (words 1, 2) could each stand alone as a separate word but in this context are one word, には
デンジャラスプレー' (word 3) are two foreign words, デンジャラス, and プレー. I haven't seen any dictionary that lumps them together as one word.
'基本', '的', 'に' (words 19, 20, 21) could each stand alone as a separate word but combined together they are one word, 基本的に.
Note that some punctuation has been included in the tokenized output.
Comment Actions
NOTE1: I have some issues with creating a pull request for delta package, we should be able to resolve it with Aaron...
NOTE2: this is the application + explanation of the code, I thank @jeena and @VulpesVulpes825 for their ideas, we will check the performance of other dictionaries/tools, but for now I wanted to have a working basic CJK tokenizer..
Tokenizer description as sent for a git pull request
Main changes:
- I added new type "cjk_word"
- I added hangul Unicode symbols (Korean alphabet)
- I added cjk=True/False value to regexp tokenizer
- False - text is tokenized "almost as before" - based on regexp, etc., but the CJK words are not tokenized to symbols, but they are kept as a continuous sequence of symbols (demarked by whitespace, etc. just like any other word) and are marked as "cjk_word", just as @VulpesVulpes825 suggested in a note in https://phabricator.wikimedia.org/T111179
- True - everything is done as for False + text is checked for a count of CJK, Japanese and Korean symbols; if there are at least 25% Japanese or Korean symbols then Jap/Kor tokenizer is used(depending which higher number of symbols) - otherwise Chinese tokenizer is used. This is due to the use of Chinese simplified and traditional symbols used in the Japan/Korean alphabet. Tokenizer goes through tokens previously marked as "cjk_word" (from the end to the beginning of the text), segments them, and replaces the original word.
Examples
To test cjk=False check results of mixed language articles - en wiki which includes ch, jp, ko language. Change only the title to eg.:
- "China" - Chinese
- "Haiku" - Japanese
- "Kimchi" - Korean
To test cjk=True tokenize same articles in Chinese(zh), Japanese(ja), Korean(ko) wikis. Adjust URL to each language and change title name to following symbols (same as above only in ch, jp, ko language):
- "김치" - Korean(ko)
- "中国" - Chinese(zh)
- "俳句" - Japanese(ja)
CJK = TRUE/FALSE test
You can see that when cjk=True long word at the beginning is segmented.
import mwapi import deltas import deltas.tokenizers import importlib importlib.reload(deltas.tokenizers) session = mwapi.Session("https://ja.wikipedia.org") doc = session.get(action="query", prop="revisions", titles="俳句", rvprop="content", rvslots="main", formatversion=2) text = doc['query']['pages'][0]['revisions'][0]['slots']['main']['content'] tokenized_text_cjk_false = deltas.tokenizers.wikitext_split.tokenize(text, cjk=False) tokenized_text_cjk_true = deltas.tokenizers.wikitext_split.tokenize(text, cjk=True)
Sending requests with default User-Agent. Set 'user_agent' on mwapi.Session to quiet this message.
tokenized_text_cjk_false[:20]
[Token('{{', type='dcurly_open'),
Token('Otheruses', type='word'),
Token('|', type='bar'),
Token('|', type='bar'),
Token('角川文化振興財団の俳句総合誌', type='cjk_word'),
Token('|', type='bar'),
Token('俳句', type='cjk_word'),
Token(' ', type='whitespace'),
Token('(', type='paren_open'),
Token('雑誌', type='cjk_word'),
Token(')', type='paren_close'),
Token('}}', type='dcurly_close'),
Token('\n', type='whitespace'),
Token('{{', type='dcurly_open'),
Token('複数の問題', type='cjk_word'),
Token('\n', type='whitespace'),
Token('|', type='bar'),
Token(' ', type='whitespace'),
Token('参照方法', type='cjk_word'),
Token(' ', type='whitespace')]tokenized_text_cjk_true[:20]
[Token('{{', type='dcurly_open'),
Token('Otheruses', type='word'),
Token('|', type='bar'),
Token('|', type='bar'),
Token('角川', type='cjk_word'),
Token('文化', type='cjk_word'),
Token('振興', type='cjk_word'),
Token('財団', type='cjk_word'),
Token('の', type='cjk_word'),
Token('俳句', type='cjk_word'),
Token('総合', type='cjk_word'),
Token('誌', type='cjk_word'),
Token('|', type='bar'),
Token('俳句', type='cjk_word'),
Token(' ', type='whitespace'),
Token('(', type='paren_open'),
Token('雑誌', type='cjk_word'),
Token(')', type='paren_close'),
Token('}}', type='dcurly_close'),
Token('\n', type='whitespace')]Walkthrough the process...
1. Get the text and regexp tokenize it
import mwapi import deltas import deltas.tokenizers import importlib importlib.reload(deltas.tokenizers) # example Titles for mixed language sites(en wiki which includes cj,jp,ko language): "Haiku" - Japanese; "Kimchi" - Korean; "China" - Chinese # same titles in ch,jp,ko wikis "김치" - Korean(ko), "中国" - Chinese(zh), "俳句" - Japanese(ja) session = mwapi.Session("https://ja.wikipedia.org") doc = session.get(action="query", prop="revisions", titles="俳句", rvprop="content", rvslots="main", formatversion=2) text = doc['query']['pages'][0]['revisions'][0]['slots']['main']['content'] tokenized_text = deltas.tokenizers.wikitext_split.tokenize(text, cjk=False)
Sending requests with default User-Agent. Set 'user_agent' on mwapi.Session to quiet this message.
text[::-1][:500]
"]]ルンャジの学文:yrogetaC[[\n]]形詩:yrogetaC[[\n]]詩:yrogetaC[[\n]]諧俳:yrogetaC[[\n]]くいは*|句俳:yrogetaC[[\n}}くいは:TROSTLUAFED{{\n\n}}能芸統伝の本日{{\n\n')句俳音(ukiaH-otO' ].baL dnuoS s'reenoiP lmth.xedni/baldnuos/pj.reenoip//:ptth[*\n]hcnerF dna nailatI ,hsilgnE ,esenapaJ ni 句俳 ukiaH /ti.iniccipinot.www//:ptth[*\n]ukiaH odraciR /moc.topsgolb.ukiah-odracir//:ptth[*\n]sukiaH hsinapS sukiah/moc.muirotircse.www//:ptth[*\n]ukiaH led onimaC úbmab ed euqsoB /ubmab_ed_euqsob/moc.seiticoeg.se//:ptth[*\n]aciremA fo yteicoS ukiaH ehT /gro.uk"tokenized_text[::-1][:20]
[Token(']]', type='dbrack_close'),
Token('文学のジャンル', type='cjk_word'),
Token(':', type='colon'),
Token('Category', type='word'),
Token('[[', type='dbrack_open'),
Token('\n', type='whitespace'),
Token(']]', type='dbrack_close'),
Token('詩形', type='cjk_word'),
Token(':', type='colon'),
Token('Category', type='word'),
Token('[[', type='dbrack_open'),
Token('\n', type='whitespace'),
Token(']]', type='dbrack_close'),
Token('詩', type='cjk_word'),
Token(':', type='colon'),
Token('Category', type='word'),
Token('[[', type='dbrack_open'),
Token('\n', type='whitespace'),
Token(']]', type='dbrack_close'),
Token('俳諧', type='cjk_word')]2. Find out which tokenizer you should use
cjk_char = ( r'[' + r'\uAC00-\uD7AF' + # hangul syllables r'\u1100-\u11FF' + # hangul jamo r'\u3130–\u318F' + # hangul r'\uA960–\uA97F' + # hangul r'\uD7B0–\uD7FF' + # hangul r'\u4E00-\u62FF' + # noqa Unified Ideographs r'\u6300-\u77FF' + r'\u7800-\u8CFF' + r'\u8D00-\u9FCC' + r'\u3400-\u4DFF' + # Unified Ideographs Ext A r'\U00020000-\U000215FF' + # Unified Ideographs Ext. B r'\U00021600-\U000230FF' + r'\U00023100-\U000245FF' + r'\U00024600-\U000260FF' + r'\U00026100-\U000275FF' + r'\U00027600-\U000290FF' + r'\U00029100-\U0002A6DF' + r'\uF900-\uFAFF' + # Compatibility Ideographs r'\U0002F800-\U0002FA1F' + # Compatibility Ideographs Suppl. r'\u3041-\u3096' + # Hiragana r'\u30A0-\u30FF' + # Katakana r'\u3400-\u4DB5' + # Kanji r'\u4E00-\u9FCB' + r'\uF900-\uFA6A' + r'\u2E80-\u2FD5' + # Kanji radicals r'\uFF5F-\uFF9F' + # Katakana and Punctuation (Half Width) r'\u31F0-\u31FF' + # Miscellaneous Japanese Symbols and Characters r'\u3220-\u3243' + r'\u3280-\u337F' + r']' ) jap_char = ( r'[' + r'\u3041-\u3096' + # Hiragana r'\u30A0-\u30FF' + # Katakana r'\u3400-\u4DB5' + # Kanji r'\u2E80-\u2FD5' + # Kanji radicals r'\uFF5F-\uFF9F' + # Katakana and Punctuation (Half Width) r'\u31F0-\u31FF' + # Miscellaneous Japanese Symbols and Characters r']' ) # https://en.wikipedia.org/wiki/Hangul # https://en.wikipedia.org/wiki/Hangul_Jamo_(Unicode_block) # https://en.wikipedia.org/wiki/Hangul_Syllables kor_char = ( r'[' + r'\uAC00-\uD7AF' + # hangul syllables r'\u1100-\u11FF' + # hangul jamo r'\u3130–\u318F' + # hangul r'\uA960–\uA97F' + # hangul r'\uD7B0–\uD7FF' + # hangul r']' ) CJK_LEXICON = { 'cjk': cjk_char, 'japanese': jap_char, 'korean': kor_char, }
import re regex_cjk = re.compile(CJK_LEXICON['cjk']) regex_japanese = re.compile(CJK_LEXICON['japanese']) regex_korean = re.compile(CJK_LEXICON['korean'])
# Haiku article had 49% of the characters japanese, rest were "cjk" so I decided to put "empirical rule of thumb" that at least 25% of the text must be korean/japanese # for Korean Kimchi article there was >90% of the symbols from Hangul char_lang_count = {'cjk': 1, 'japanese': 0.75 + len(regex_japanese.findall(text))/len(regex_cjk.findall(text)), 'korean': 0.75 + len(regex_korean.findall(text))/len(regex_cjk.findall(text))} char_lang = max(char_lang_count, key=char_lang_count.get)
char_lang_count{'cjk': 1, 'japanese': 1.241775763679087, 'korean': 0.75}3. Winner is Japanese
char_lang'japanese'
4. We find indices of cjk_words
cjk_word_indices = list(filter(lambda x: tokenized_text[x].type == 'cjk_word', range(len(tokenized_text))))
5. check the output of the tokenizer
# japanese import MeCab as jp_mecab seg = jp_mecab.Tagger("-Owakati") for i in cjk_word_indices[::-1][:20]: temp=seg.parse(tokenized_text[i]).split() print(temp)
['文学', 'の', 'ジャンル'] ['詩形'] ['詩'] ['俳諧'] ['は', 'いく'] ['俳句'] ['は', 'いく'] ['日本', 'の', '伝統', '芸能'] ['音', '俳句'] ['俳句'] ['日本', '漢', '俳', '学会'] ['国際', '俳句', '交流', '協会'] ['ジャック', 'たけし', 'の', '英語', '俳句'] ['世界', '俳句', '協会'] ['滑稽', '俳句', '協会'] ['新', '俳句', '人', '連盟'] ['俳人', '協会'] ['現代', '俳句', '協会'] ['日本', '伝統', '俳句', '協会'] ['外部', 'リンク']
6. Apply the Token class (as in deltas package) on new segmented cjk_words and replace the previous sequences
class Token(str): """ Constructs a typed sub-string extracted from a text. """ __slots__ = ("type") def __new__(cls, content, *args, **kwargs): if isinstance(content, cls): return content else: return super().__new__(cls, content) def tokens(self): """ Returns an iterator of *self*. This method reflects the behavior of :meth:`deltas.Segment.tokens` """ yield self def __init__(self, content, type=None): self.type = str(type) if type is not None else None """ An optional value describing the type of token. """ def __repr__(self): return "{0}({1}, type={2})" \ .format(self.__class__.__name__, super().__repr__(), repr(self.type)) token_class = Token
# japanese with tokenization for i in cjk_word_indices[::-1]: segmented_cjk_token = seg.parse(tokenized_text[i]).split() tokenized_text[i:i+1] = [token_class(word, type="cjk_word") for word in segmented_cjk_token]
tokenized_text[::-1][:20]
[Token(']]', type='dbrack_close'),
Token('ジャンル', type='cjk_word'),
Token('の', type='cjk_word'),
Token('文学', type='cjk_word'),
Token(':', type='colon'),
Token('Category', type='word'),
Token('[[', type='dbrack_open'),
Token('\n', type='whitespace'),
Token(']]', type='dbrack_close'),
Token('詩形', type='cjk_word'),
Token(':', type='colon'),
Token('Category', type='word'),
Token('[[', type='dbrack_open'),
Token('\n', type='whitespace'),
Token(']]', type='dbrack_close'),
Token('詩', type='cjk_word'),
Token(':', type='colon'),
Token('Category', type='word'),
Token('[[', type='dbrack_open'),
Token('\n', type='whitespace')]APPENDIX - Chinese and Korean tokenizers
Chinese
import pkuseg seg = pkuseg.pkuseg() #load the default model for i in cjk_word_indices[::-1][:2]: print(seg.cut(tokenized_text[i]))
['亞洲', '分裂', '地', '區'] ['分類']
Korean
In Korean some symbol combinations result in empty list, I guess this is beacause they are not nouns. They can be still separated to morphs - see result below, but this is too high granularity for our purpose so if the result is empty I just keep previous Token.
from konlpy.tag import Mecab as ko_mecab seg = ko_mecab()
seg.nouns("있다")
seg.morphs("있다")
['있', '다']
for i in cjk_word_indices[::-1][:20]: temp=seg.nouns(tokenized_text[i]) if temp == []: temp = tokenized_text[i] print(temp)
['식품'] ['발효'] ['분류'] ['요리'] ['한국'] ['분류'] ['김치'] ['분류'] ['통제'] ['전거'] ['글로벌', '세계', '대백', '사전'] ['김치'] ['한국', '김치', '절임', '식품', '공업', '협동조합'] ['과학'] ['김치'] 농익은 ['캐스트'] ['네이버'] ['김치'] ['김치']
Comment Actions
Talking with @Pavol86, it looks like we need to be able to install mecab and the related dictionaries in order to process Japanese and Korean.
These are Pavol's notes:
- CHINESE
- install pkuseg
pip install pkuseg
- JAPANESE
- install mecab
wget -O mecab-0.996.tar.gz "https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7cENtOXlicTFaRUE" tar zxvf mecab-0.996.tar.gz cd mecab-0.996 && ./configure && make && make check sudo make install
- install mecab ipadic dictionary
wget -O mecab-ipadic-2.7.0-20070801.tar.gz "https://drive.google.com/uc?export=download&id=0B4y35FiV1wh7MWVlSDBCSXZMTXM" tar zxvf mecab-ipadic-2.7.0-20070801.tar.gz cd mecab-ipadic-2.7.0-20070801 &&./configure --with-charset=utf8 && make && make check sudo make install
- KOREAN
- install konlpy
pip install konlpy
- install Mecab-ko dictionary
wget https://bitbucket.org/eunjeon/mecab-ko-dic/downloads/mecab-ko-dic-1.6.1-20140814.tar.gz tar zxfv mecab-ko-dic-1.6.1-20140814.tar.gz cd mecab-ko-dic-1.6.1-20140814 ./configure sudo ldconfig make sudo sh -c 'echo "dicdir=/usr/local/lib/mecab/dic/mecab-ko-dic" > /usr/local/etc/mecabrc' sudo make install
We're going to need to get these from apt repos somehow rather than compiling them ourselves.
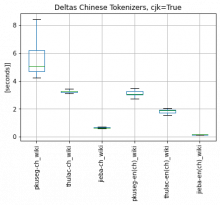
Comment Actions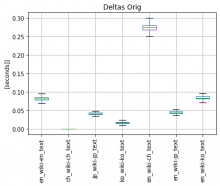
3.2 I found out that the loading of the Chinese tokenizer model is a bottleneck, so I tested pkuseg, thulac, jieba on Chinese wiki with Chinese text. Jieba is the only tokenizer that needs to be initialized only once and then it is kept in memory. Pkuseseg and Thulac take 2-3s to initialize. Model load of each tokenizer (including jap and kor)
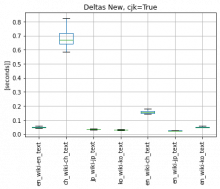
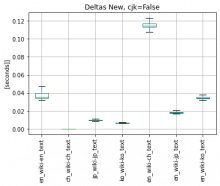
3.2 I tested the performance of New Deltas tokenizer (that has CJK tokenization) with new Jieba Chinese tokenizer and cjk flag set to True/False:
@Halfak I need your feedback on following. According to our call last week I did following :
- make the ch, jp, ko tokenizer decision more explicit in the code
- add "# noqa" to lines that should have >85 chars - as a workaround for flake8/pep8 test
- performance tests : run the code 100-1000x times on the same article and compare performance between prev/new version, cjk tokenization True/False
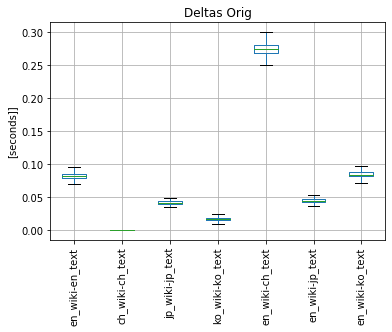
3.1 I tested the performance of original deltas tokenizer, see following boxplots - y-axis marks the type of wiki and type of text (EN wiki with EN text, Chinese wiki with Chinese text,... EN wiki with Chinese text, etc..)
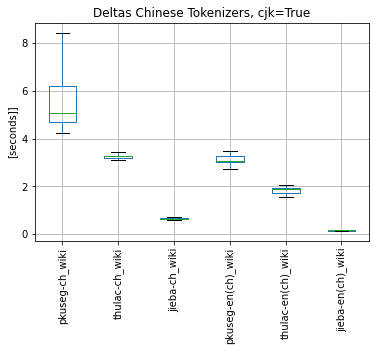
3.2 I found out that the loading of the Chinese tokenizer model is a bottleneck, so I tested pkuseg, thulac, jieba on Chinese wiki with Chinese text. Jieba is the only tokenizer that needs to be initialized only once and then it is kept in memory. Pkuseseg and Thulac take 2-3s to initialize. Model load of each tokenizer (including jap and kor)
| language | model | load time | additional installation needed? |
| ch | pkuseg | 2.687344551086426 | yes |
| ch | thulac | 1.8775367736816406 | no |
| ch | jieba | 1.3582587242126465 | no |
| jp | mecab | 0.0023169517517089844 | yes |
| ko | hannanum | 0.0010521411895751953 | no |
| ko | kkma | 0.0013973712921142578 | no |
| ko | komoran | 1.694901943206787 | no |
| ko | mecab | 0.0013427734375 | yes |
| ko | okt | 0.0007483959197998047 | no |
Chinese text tokenization with each tokenizer (on Chinese wiki with Chinese text and EN wiki with some Chinese text):
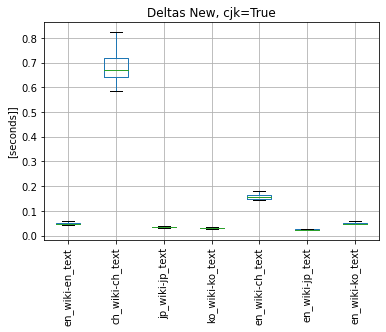
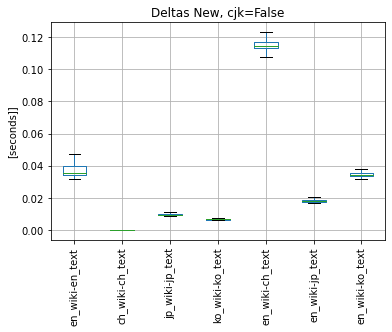
3.2 I tested the performance of New Deltas tokenizer (that has CJK tokenization) with new Jieba Chinese tokenizer and cjk flag set to True/False:
NOTES:
- Please consider scale on y-axis, I did not unite the scale as the test of Chinese tokenizers is from 1s to 8s - this would make other plots pointless
- Jieba is has worse accuracy but is much faster + it does not need additional Mecab dictionary installation - pip install is enough
- We also talked about packaging/deployment of the solution
3.1 Chinese - Jieba needs only pip install, no additional dictionary
3.2 Japanese - every package I found needed additional installation, i.e. thwy were wrapper methods for - Mecab, JUMAN, JUMAN++, KyTea,... , and the tokenizer had to be installed separately
3.3 Korean - we can use builtin methods like hannanum and kkma that does not need any additional installation (see page 33 https://konlpy.org/_/downloads/en/latest/pdf/) - you may see the load time in the table under point 2.2
@Halfak , please send me a feedback : what approach do you want to take? Chinese/Korean are no longer issue, is it possible to get the Mecab or any other JP tokenizer installed in production?
Comment Actions
Given that we are likely trying to use these segmenters in order to get *signal* and not to translate or do something more exact, I'm a fan of faster, lower accuracy, and easier to install methods. It looks like Japanese will be the most difficult.
Comment Actions
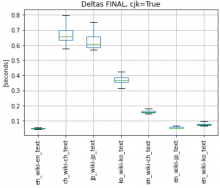
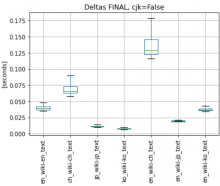
FINAL NOTES (hopefully :) ):
Japanese:
- I did haven't tried SudachiPy as I saw poor performance stats, It is the only JP tokenizer that I was able to get running just by "pip install" without any additional instructions
- SudachiPy model loads quickly:
jp_sudachi model load time: 0.03719305992126465
- SudachiPy has 3 splitting modes A|B|C (https://github.com/WorksApplications/Sudachi ):
Sudachi provides three modes of splitting. In A mode, texts are divided into the shortest units equivalent to the UniDic short unit. In C mode, it extracts named entities. In B mode, into the middle units.
- I decided to use "mode A" - after checking splitting results
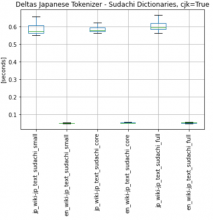
- SudachiPy has 3 possibilities for dictionary small | core[default] | full (https://github.com/WorksApplications/SudachiDict):
Small: includes only the vocabulary of UniDic Core: includes basic vocabulary (default) Full: includes miscellaneous proper nouns
- there is only a slight difference in the performance of tokenizer with each dict. (small slightly faster than core, etc.), see:
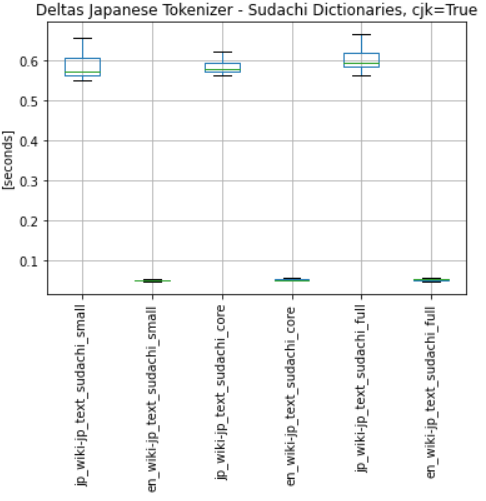
- I recommend use of full dict with split mode A, to download/use full dict:
pip install sudachidict_full sudachipy link -t full
Korean:
- I decided to go with Okt (Tweeter tokenizer) : (i) fastest model load time, (ii) 2nd best performance after Mecab(which needs additional installation), for performance comparison see: https://github.com/open-korean-text/open-korean-text
Chinese:
- I decided to use Jieba, see previous post in the thread
PERFORMANCE:
- no additional install needed, "pip install" is enough!
- as I previously mentioned I ran the test 100x on following wiki pages:
"https://en.wikipedia.org" : ["The_Doors", "China", "Haiku", "Kimchi"]
"https://zh.wikipedia.org" : "中國" ("China" in Chinese)
"https://ja.wikipedia.org" : "俳句" ("Haiku" in Japanse)
"https://ko.wikipedia.org" : "김치" ("Kimchi" in Korean)- cjk tokenization turned on (cjk = True)
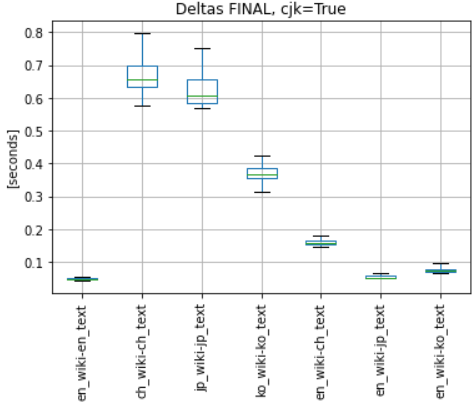
- cjk tokenization turned off (cjk = False)
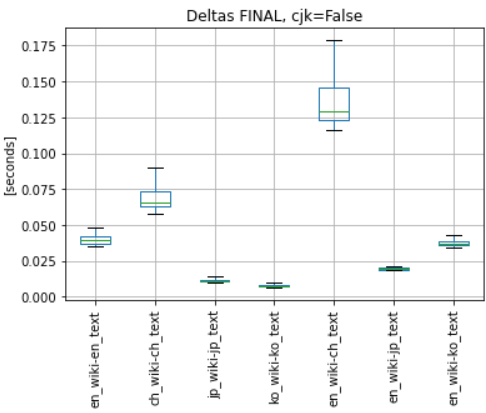
I believe we can move forward, do final adjustment to the code and get it into production...
side notes:
- maybe some strategies from FB research library LASER could be utilized for wiki:
https://github.com/facebookresearch/LASER
- just when I stopped searching I found free Japanse corpus for testing :
Comment Actions
@Pavol86. Congratulation on finding a Japanese word segmentation package that does not require additional compiling. After my own testing, I believe SudachiPy's word segmentation performance is good enough. However, I believe going with the full dictionary option and the B mode is a better choice, as the A mode segment too much. The A mode basically segments "basic" and "lly" apart. In the Chinese word segmentation guidelines, this is not acceptable.
Also, Is it possible for you to guide me to the source code of your tokenization tool? I believe this tokenization tool, with modification, can be used in other projects such as Content Translation.
Comment Actions
@VulpesVulpes825 thank you for the recommendation! I do not speak any of the languages so I am "best guessing" all the way :). The CJK tokenization should be part of the deltas library at the end - https://github.com/halfak/deltas . I prepared the code to be merged(pull request) with deltas and I have a call with @Halfak today. I will keep you updated..