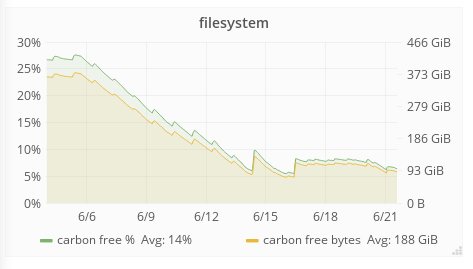
I noticed eventstreams using a significant amount of disk space on graphite, with ~half of rdkafka metrics being more than 10d old and not updated. @Ottomata anything we could do here like aggregating in a different way or purge old metrics?
root@graphite1001:/var/lib/carbon/whisper/eventstreams# find rdkafka/ -type f -mtime +10 | wc -l 239220 root@graphite1001:/var/lib/carbon/whisper/eventstreams# find rdkafka/ -type f | wc -l 518155
161G eventstreams