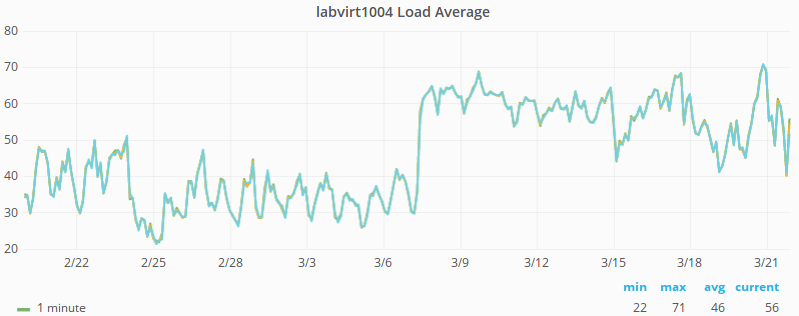
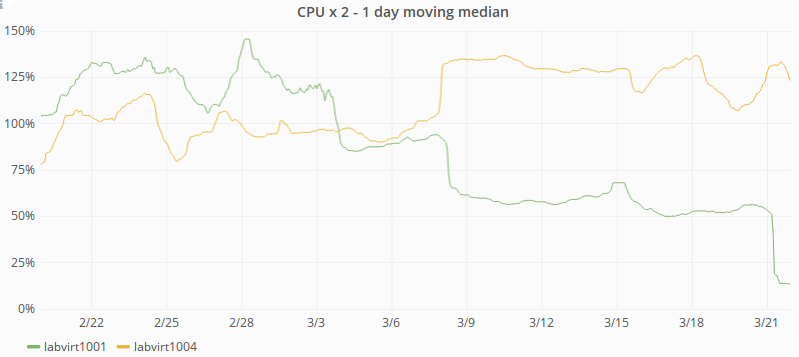
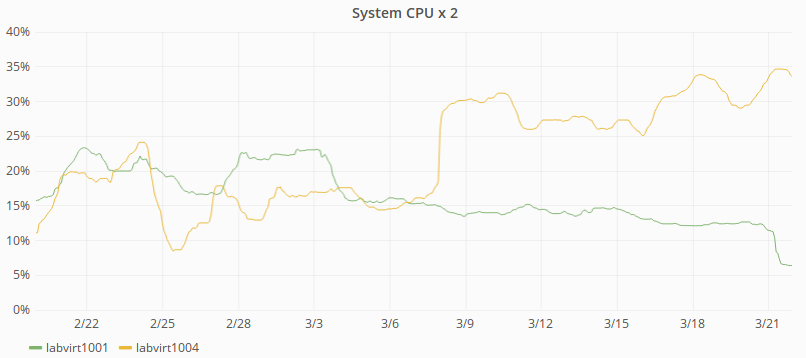
There's some reason to think that our metrics have been lying to us about CPU usage on labvirt hosts, as per
http://www.blueshiftblog.com/?p=3822
If that's true then a few of our virt nodes are probably CPU starved. For now it should be possible to shuffle around some exec nodes and get CPU usage under 50% for all hosts.