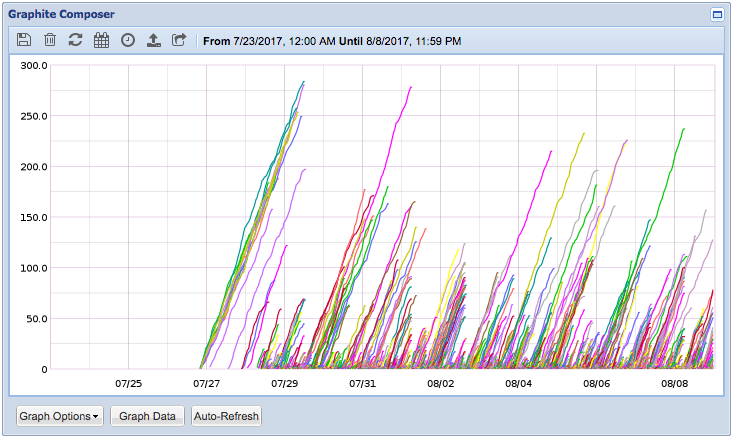
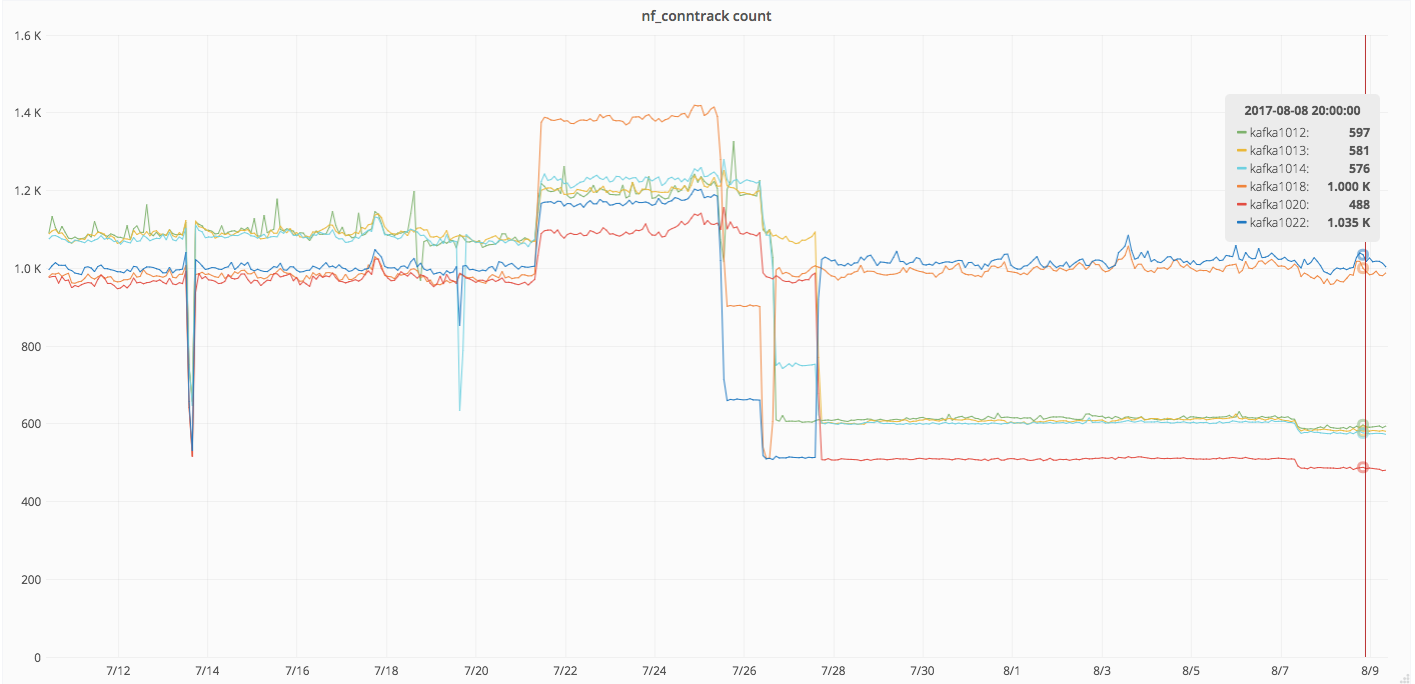
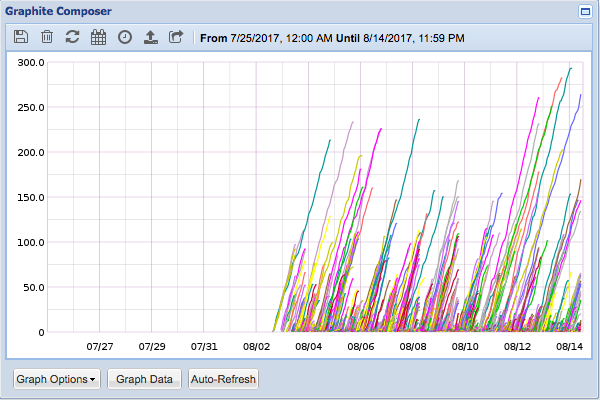
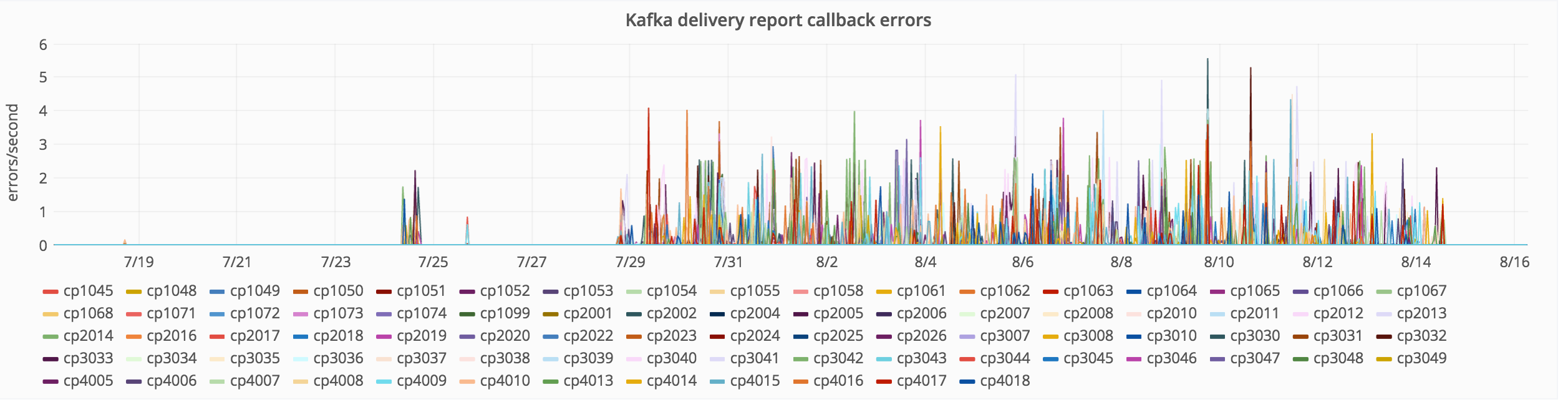
Varnishkafka seems reporting errors from July 28th ~18 UTC:
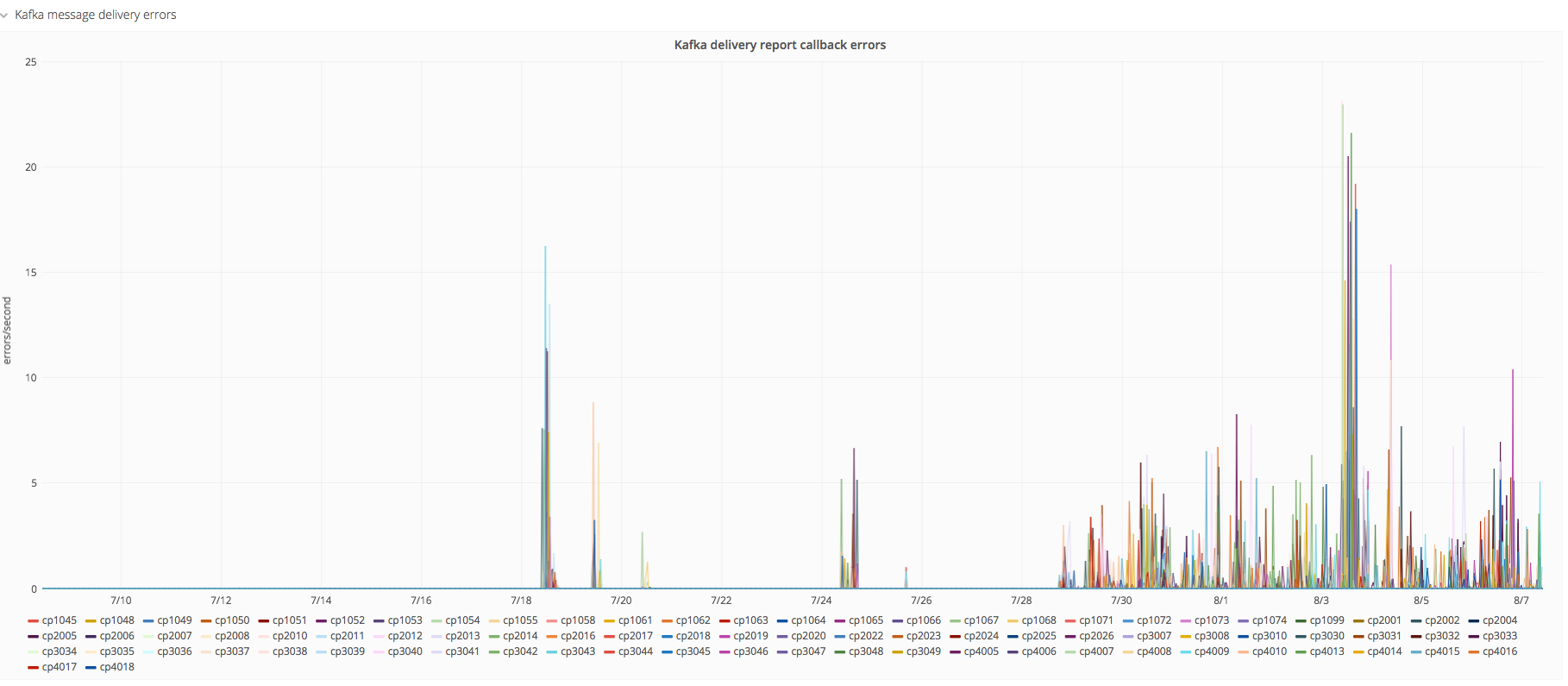
This seems to be related to the following error constantly being logged on all the brokers (note the timing):
[2017-07-28 17:39:53,099] INFO Rolled new log segment for 'webrequest_text-15' in 23 ms. (kafka.log.Log)
[2017-07-28 17:39:55,750] INFO Rolled new log segment for 'webrequest_text-8' in 1 ms. (kafka.log.Log)
[2017-07-28 17:40:30,308] INFO Rolled new log segment for 'mediawiki_ApiAction-9' in 1 ms. (kafka.log.Log)
[2017-07-28 17:41:01,705] ERROR Processor got uncaught exception. (kafka.network.Processor)
java.lang.ArrayIndexOutOfBoundsException: 18
at org.apache.kafka.common.protocol.ApiKeys.forId(ApiKeys.java:68)
at org.apache.kafka.common.requests.AbstractRequest.getRequest(AbstractRequest.java:39)
at kafka.network.RequestChannel$Request.<init>(RequestChannel.scala:79)
at kafka.network.Processor$$anonfun$run$11.apply(SocketServer.scala:426)
at kafka.network.Processor$$anonfun$run$11.apply(SocketServer.scala:421)
at scala.collection.Iterator$class.foreach(Iterator.scala:742)
at scala.collection.AbstractIterator.foreach(Iterator.scala:1194)
at scala.collection.IterableLike$class.foreach(IterableLike.scala:72)
at scala.collection.AbstractIterable.foreach(Iterable.scala:54)
at kafka.network.Processor.run(SocketServer.scala:421)
at java.lang.Thread.run(Thread.java:745)
[2017-07-28 17:41:31,700] WARN [ReplicaFetcherThread-1-20], Error in fetch kafka.server.ReplicaFetcherThread$FetchRequest@105e15b2. Possible cause: java.io.IOException: Connection to 20 was disconnected before the response was read (kafka.server.ReplicaFetcherThread)The corresponding Varnishkafka errors are the following (this one belongs to cp4015 that was one of the first to show it):
Jul 28 17:46:00 cp4015 varnishkafka[1655]: %3|1501263960.918|FAIL|varnishkafka#producer-1| [thrd:kafka1020.eqiad.wmnet:9092/bootstrap]: Jul 28 17:46:00 cp4015 varnishkafka[1655]: KAFKAERR: Kafka error (-192): kafka1020.eqiad.wmnet:9092/20: 1 request(s) timed out: disconn Jul 28 17:46:01 cp4015 varnishkafka[1655]: %3|1501263961.919|FAIL|varnishkafka#producer-1| [thrd:kafka1020.eqiad.wmnet:9092/bootstrap]: Jul 28 17:46:01 cp4015 varnishkafka[1655]: KAFKAERR: Kafka error (-192): kafka1020.eqiad.wmnet:9092/20: 5 request(s) timed out: disconn Jul 28 17:46:02 cp4015 varnishkafka[1655]: %3|1501263962.957|FAIL|varnishkafka#producer-1| [thrd:kafka1020.eqiad.wmnet:9092/bootstrap]: Jul 28 17:46:02 cp4015 varnishkafka[1655]: KAFKADR: Kafka message delivery error: Local: Timed out in queue Jul 28 17:46:02 cp4015 varnishkafka[1655]: KAFKADR: Kafka message delivery error: Local: Timed out in queue Jul 28 17:46:02 cp4015 varnishkafka[1655]: KAFKADR: Kafka message delivery error: Local: Timed out in queue Jul 28 17:46:02 cp4015 varnishkafka[1655]: KAFKADR: Kafka message delivery error: Local: Timed out in queue [.. repeated..]
https://issues.apache.org/jira/browse/KAFKA-3547 (and https://issues.apache.org/jira/browse/KAFKA-3593) seems possibly related, maybe a new producer/consumer is causing these timeouts? Event streams timings might correlate?
EDIT: the kafka jira might be a false lead since we investigated it in https://phabricator.wikimedia.org/T160886 too.