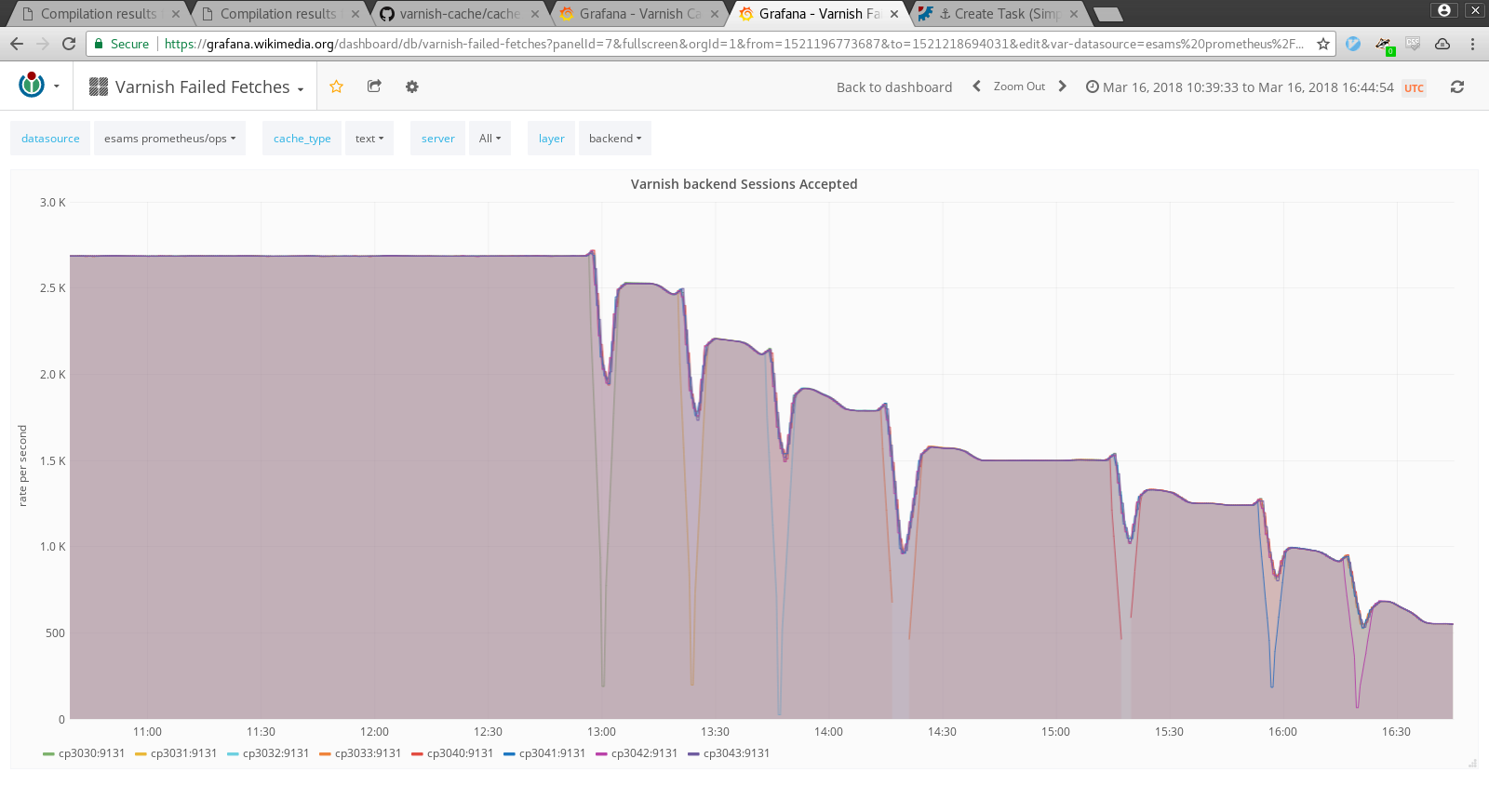
The rate of sessions accepted (MAIN.sess_conn) keeps on increasing on varnish backends, without any significant change in frontend traffic patterns, since the upgrade to varnish 5:
rate(varnish_main_sessions{layer="$layer", type=~"conn", job="varnish-$cache_type",instance=~"($server):.*"}[5m])

The "steps" there happen when a varnish backend is restarted by cron.
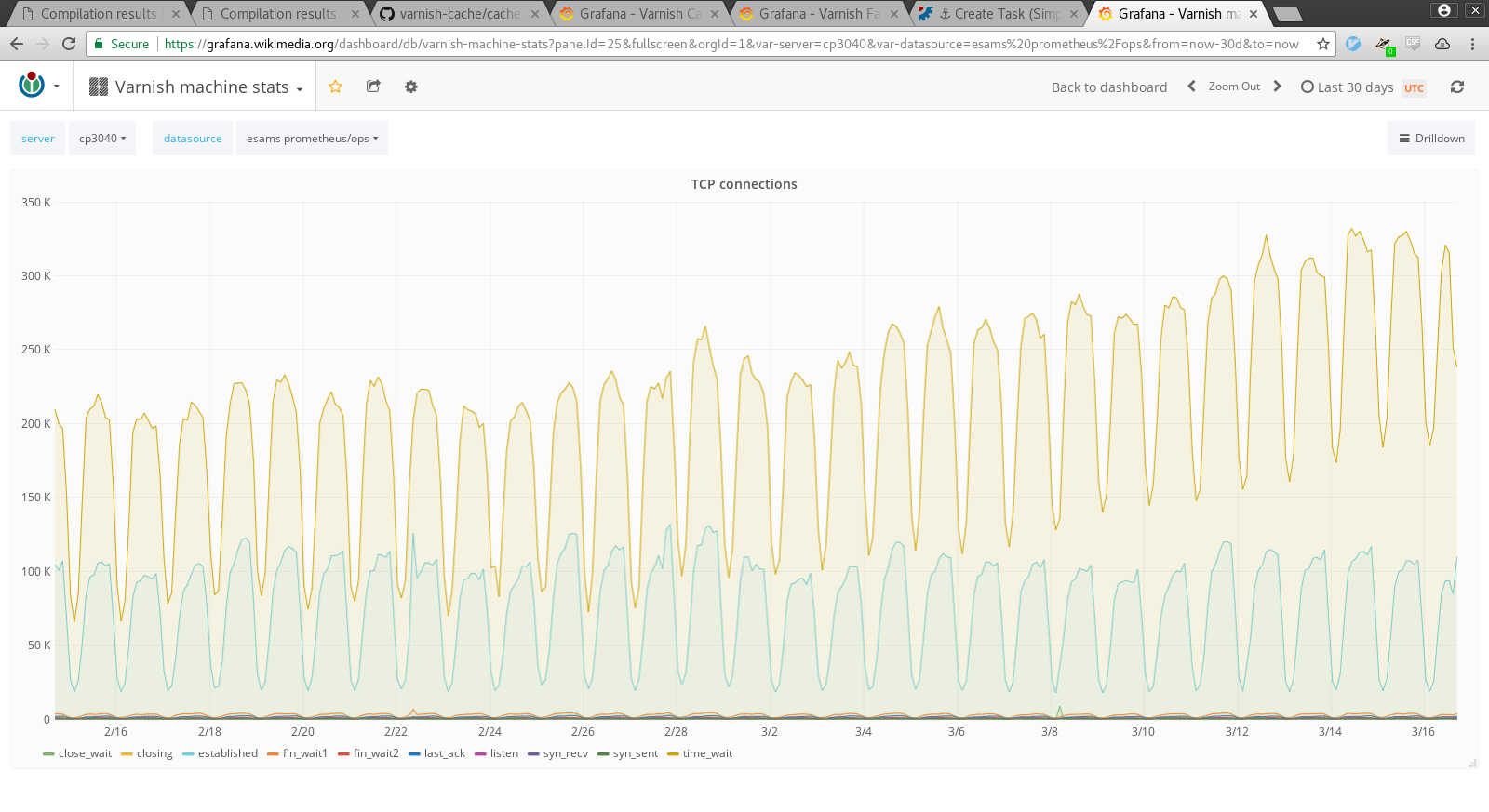
The increasing rate does not seem to correlate with the number of established connections on the host. There is, however, a significant increase in the number of connections in time-wait. See for example cp3040:
As an immediate mitigation in text-esams, I've rebooted all hosts (which had to be done anyways as part of T188092). That resulted in a decrease in fe<->be session rate as well as an increase in fe<->be session reuse rate.

Open questions:
What is causing the increase? Is this related to T181315 and T174932? Is the varnish-be-restart switch from weekly to twice a week going to cause harm in this context? Would upgrading to varnish 5.1.3-wm4 change anything?