From a private file upload by @Samat:
Dear Performance Team,
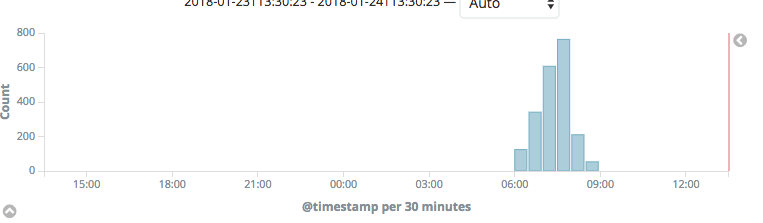
I uploaded a .har file was created by the network tool (part of devtools) in FF 57. The file shows a page load with about 160 seconds.
I have often problem with the performance of the new surfaces (VE, WikiTextEditor2017, Filters, Notifications etc.), and I would like to understand the reason(s): is it only my fault or we can improve the software to make it better for millions of people. I believe, that my computer is not very slow, probably large part of the users (readers, editors) has slower tools than mine.
Please, investigate the file, and let me know, which script or anything caused the huge loading time.
(I can provide other examples, too, where the loading time is between 20 and 50 second; and my first impression is, that it waits at different part of the process...)Please, handle the file confidentially, because it very likely contains sensitive data of mine (for example I have advanced administrative rights). If it is necessary, you can share the file at the WMF with other colleagues with the same clause. (From the results, it wasn't clear for me, which is the best developer team or group to assign to it.)
Please note, that I am not a developer, and I have to learn everything (small) step-by-step here. Be patient :)
Thank you,
Samat
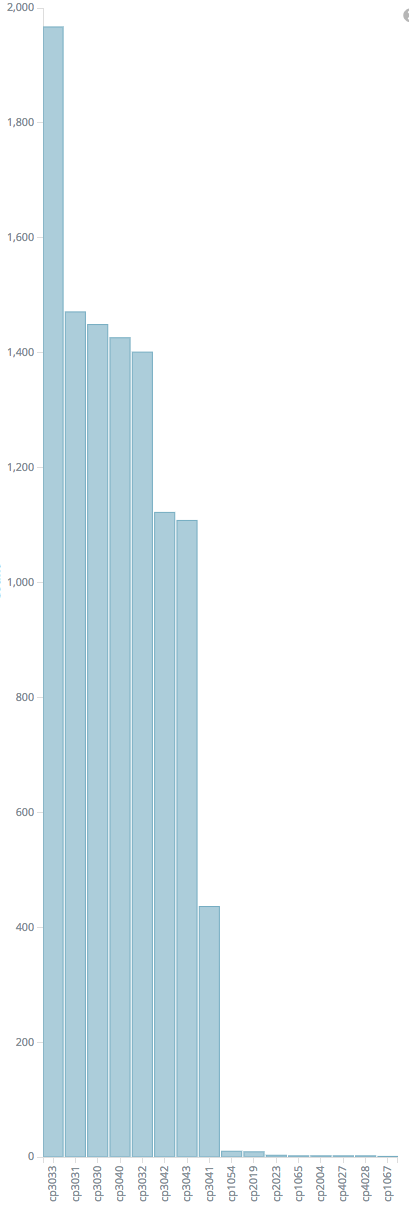
The HAR file shows a normal wiki page request, with https://hu.wikipedia.org/w/load.php?debug=false&lang=en&modules=site.styles&only=styles&skin=vector taking 160s to load (all the other ResourceLoader requests are in the 50-200ms range). The Backend-Timing header has D=30593 and the receiving timestamp matches the Date header in the request, so the time is not spent in ResourceLoader.
See also:
- September 2016: T145661: varnish backends start returning 503s after ~6 days uptime
- November 2016: T150269: EventLogging schema modules take >1s to build (max: 22s)
- May 2017: T164248: HTTP responses from app servers sometimes stall for >1s
- September 2017:
- March 2018: