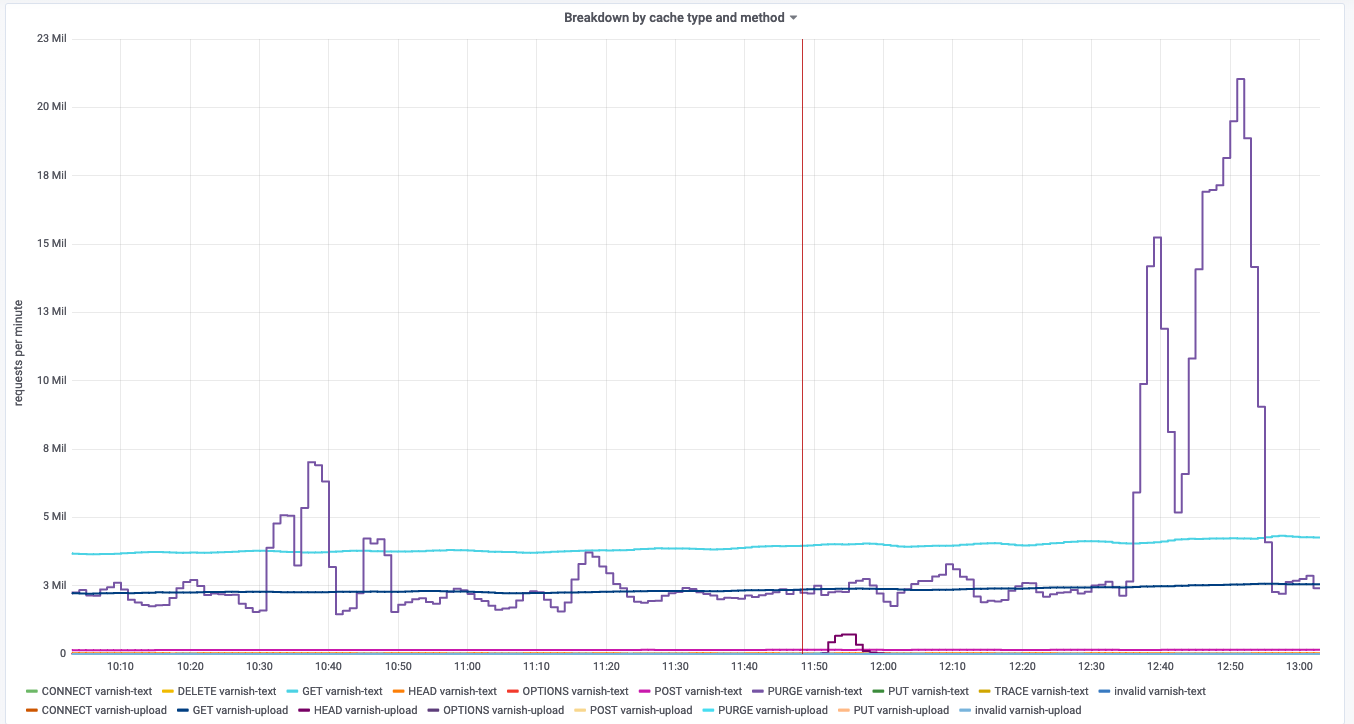
Increase in traffic, believed to be purges (those seem recurring and unrelated):
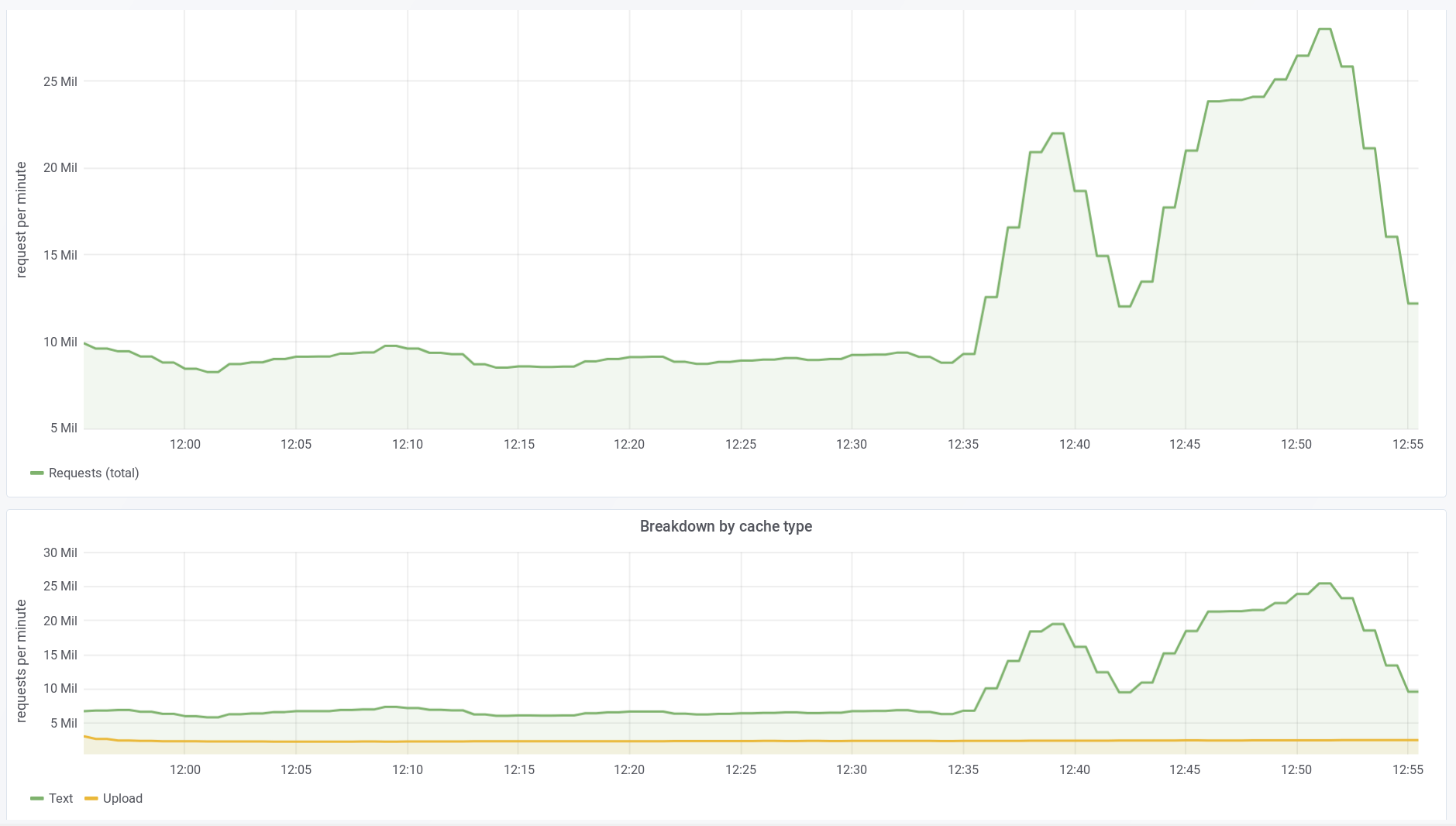
cp1077 was depooled just in case:
| • jcrespo | |
| Mar 8 2019, 12:54 PM |
| F28373209: Screenshot from 2019-03-12 10-01-00.png | |
| Mar 12 2019, 9:33 AM |
| F28372980: Screenshot from 2019-03-12 09-30-53.png | |
| Mar 12 2019, 8:40 AM |
| F28372982: Screenshot from 2019-03-12 09-30-29.png | |
| Mar 12 2019, 8:40 AM |
| F28347569: varnishPURGEspikes.png | |
| Mar 8 2019, 1:08 PM |
| F28347567: Screenshot 2019-03-08 at 14.05.19.png | |
| Mar 8 2019, 1:05 PM |
| F28347557: 5XX.png | |
| Mar 8 2019, 1:03 PM |
| F28347561: requests.png | |
| Mar 8 2019, 1:03 PM |
| F28347559: cp1077.png | |
| Mar 8 2019, 1:03 PM |
Increase in traffic, believed to be purges (those seem recurring and unrelated):
cp1077 was depooled just in case:
I updated the comment- Those seem recurring, there was another at 8 causing a traffic increase, but no errors then.
The spike of PURGE requests to the Varnish text frontends seems to be recurring. A view over 24 hours from https://grafana.wikimedia.org/d/000000180/varnish-http-requests?panelId=7&fullscreen&orgId=1&from=now-24h&to=now
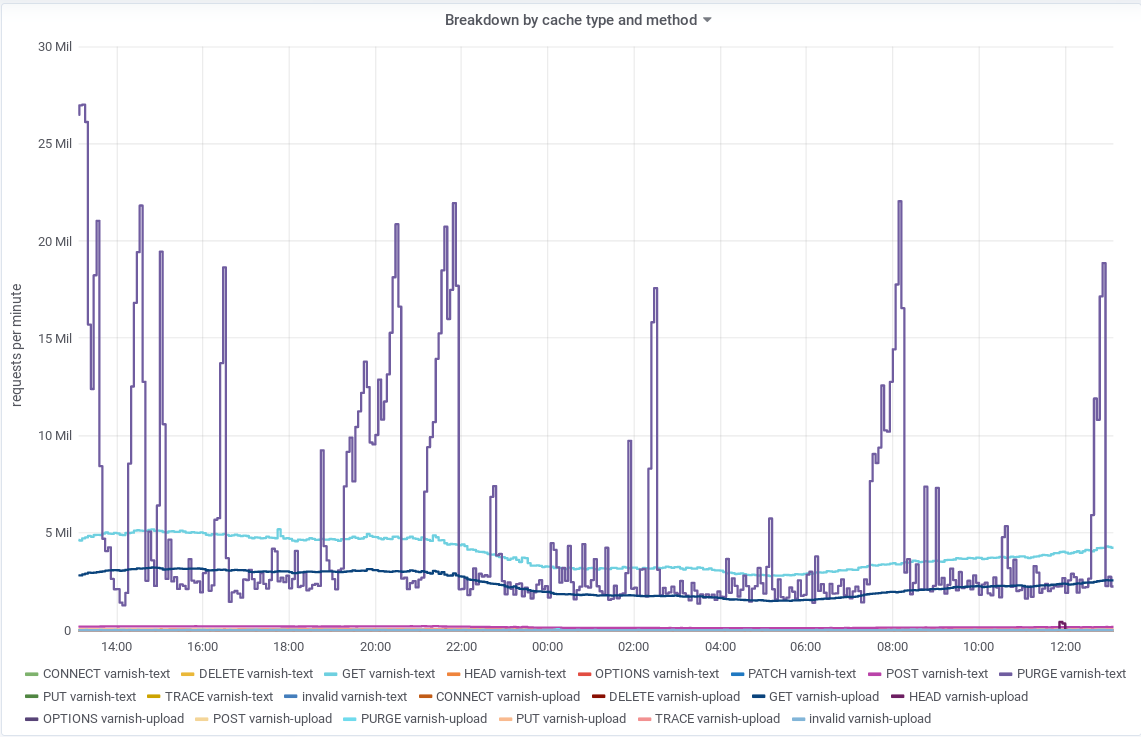
So I guess we can dismiss those PURGE as being the root cause.
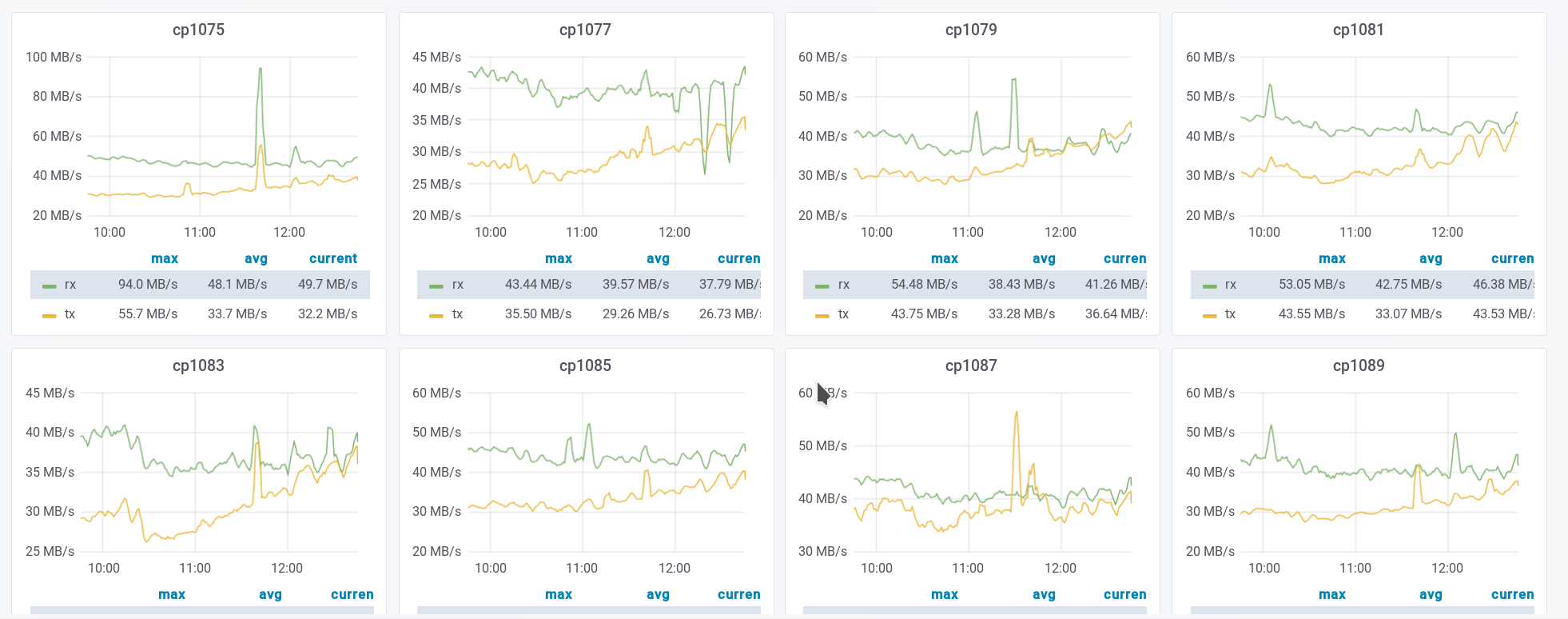
At the time of the issue, cp1077 was failing to fetch objects from its origin servers and was affected heavily by mbox lag.
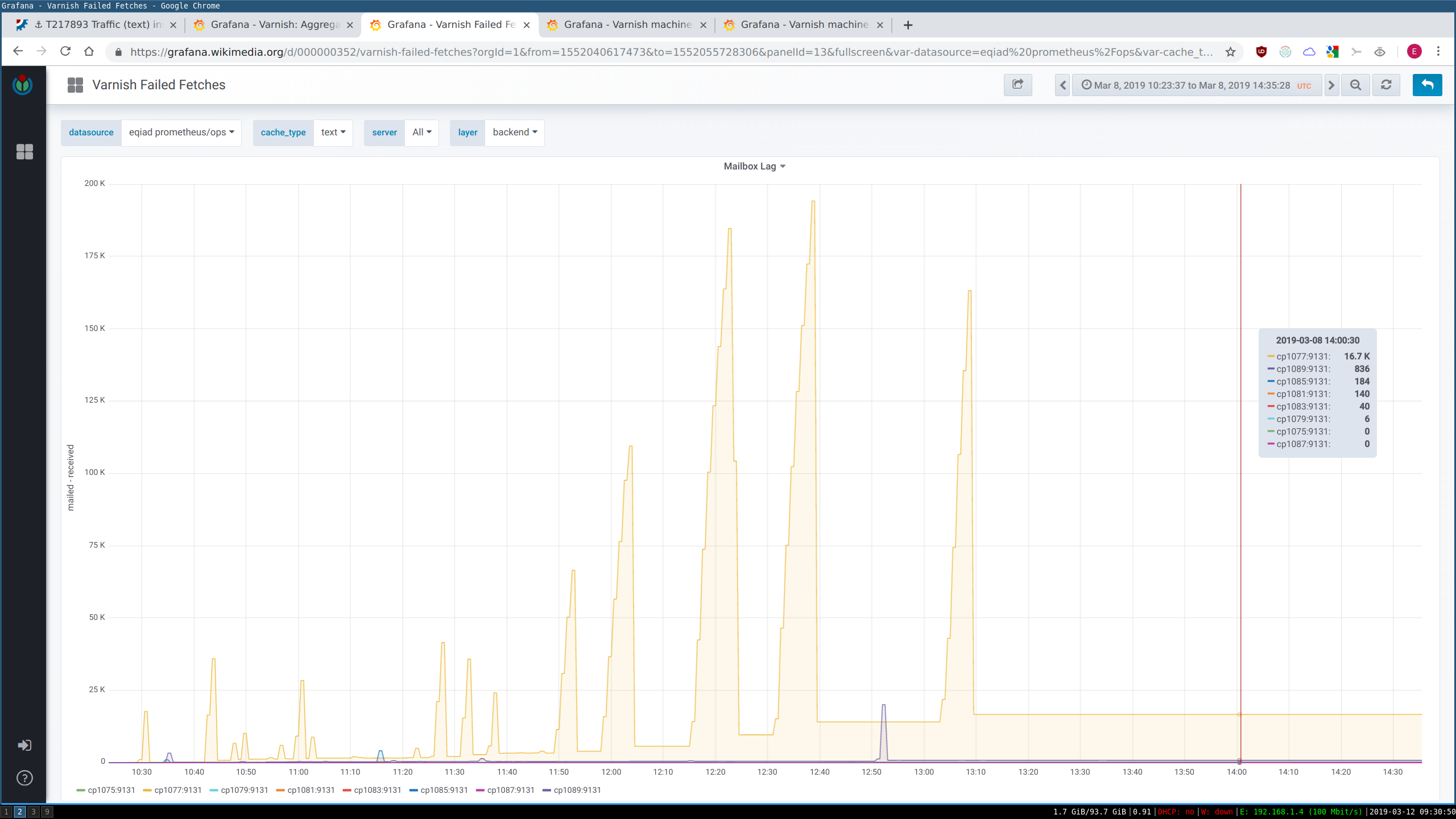
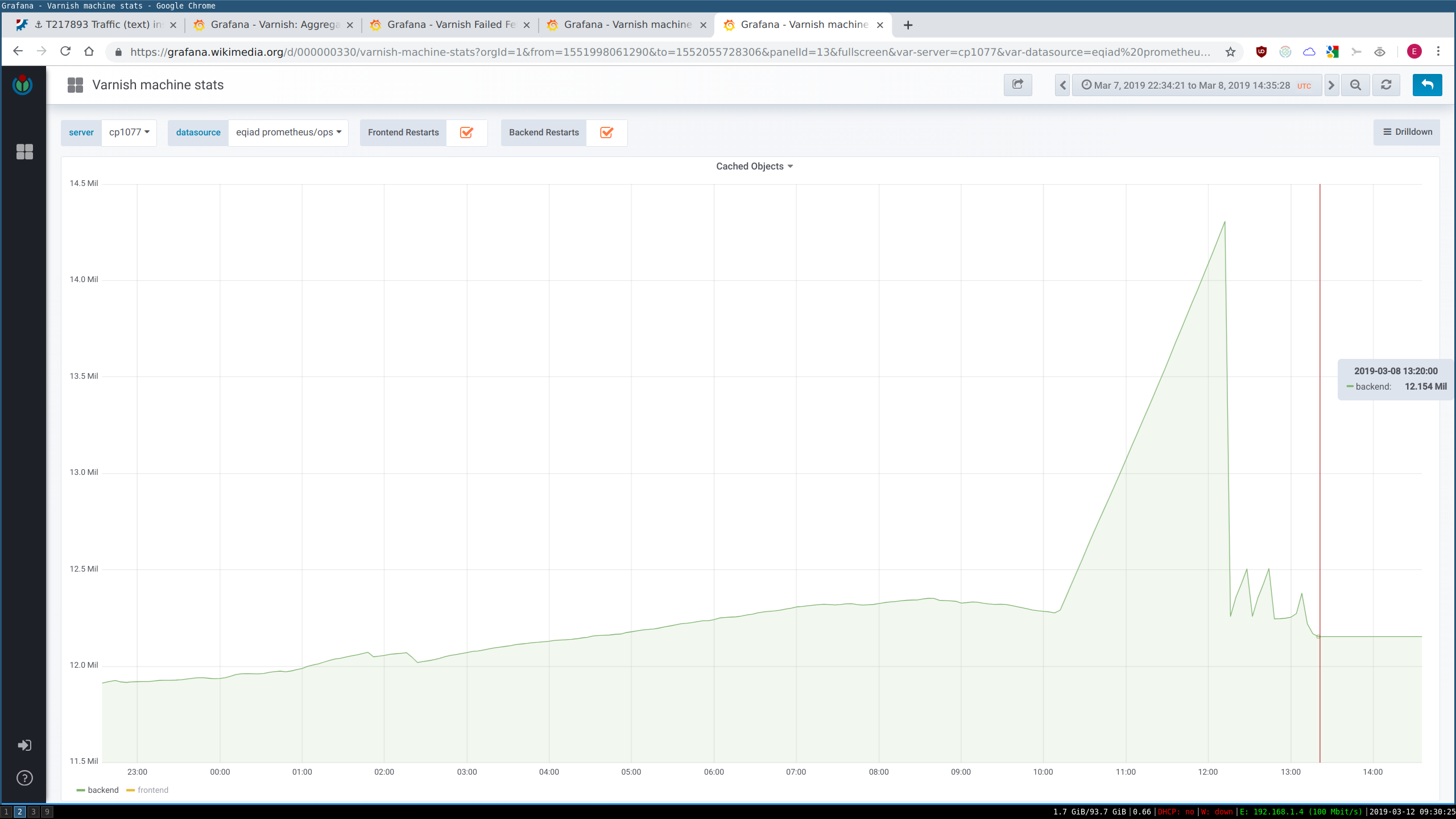
varnish-be was not really managing to evict objects at that time.
This looks very much like the known Varnish scalability issue we've been dealing with for some time and trying to work around by restarting varnish.service in cron. See, among others: T145661, T175803, and T181315. cp1077 was just a few hours away from the by-weekly varnish restart, which was scheduled at 18:52 UTC.
Mentioned in SAL (#wikimedia-operations) [2019-03-12T08:46:33Z] <ema> cp1077 repooled T217893
Mentioned in SAL (#wikimedia-operations) [2019-03-12T08:48:07Z] <ema> restart varnish-be on cp1077 T217893
Mentioned in SAL (#wikimedia-operations) [2019-03-12T08:50:20Z] <ema> cp1077 depooled again T217893
Re-pooling the service caused the issue to show up again. For some reason, the cron jobs restarting varnish.service do not seem to have worked. Although cron logged two restarts, one on Mar 08 and one on Mar 12:
Mar 08 18:52:01 cp1077 CRON[275180]: (root) CMD (/usr/local/sbin/run-no-puppet /usr/local/sbin/varnish-backend-restart > /dev/null) Mar 12 06:52:01 cp1077 CRON[7582]: (root) CMD (/usr/local/sbin/run-no-puppet /usr/local/sbin/varnish-backend-restart > /dev/null)
The number of cached backend objects did not decrease, indicating that the service was not actually restarted.

The journal confirms:
root@cp1077:~# journalctl --since='8 days ago' -u varnish.service | grep -B1 'Starting varnish' Mar 05 06:52:44 cp1077 systemd[1]: Stopped varnish (Varnish HTTP Accelerator). Mar 05 06:53:30 cp1077 systemd[1]: Starting varnish (Varnish HTTP Accelerator)... -- Mar 12 08:48:54 cp1077 systemd[1]: Stopped varnish (Varnish HTTP Accelerator). Mar 12 08:49:44 cp1077 systemd[1]: Starting varnish (Varnish HTTP Accelerator)...
Change 495862 had a related patch set uploaded (by Ema; owner: Ema):
[operations/puppet@production] varnish-backend-restart: log execution to syslog
The reason is that cp1077 was depooled on Mar 08 at 13:09, and varnish-backend-restart exits silently if the service is depooled. Hence, the 18:52 cron job did not restart varnish.
Mentioned in SAL (#wikimedia-operations) [2019-03-12T11:36:33Z] <ema> cp1077: repool varnish-be after service restart T217893
Change 495862 merged by Ema:
[operations/puppet@production] varnish-backend-restart: log execution to syslog
Change 495936 had a related patch set uploaded (by Ema; owner: Ema):
[operations/puppet@production] varnish-backend-restart: do not spam cron
Change 495936 merged by Ema:
[operations/puppet@production] varnish-backend-restart: do not spam cron
Closing this as cp1077 is fine and back in service. For the general Varnish scalability issue, the solution we've identified is moving to ATS (ongoing, see T213263).