http://terrierteam.dcs.gla.ac.uk/publications/kharitonov-sigir2013.pdf
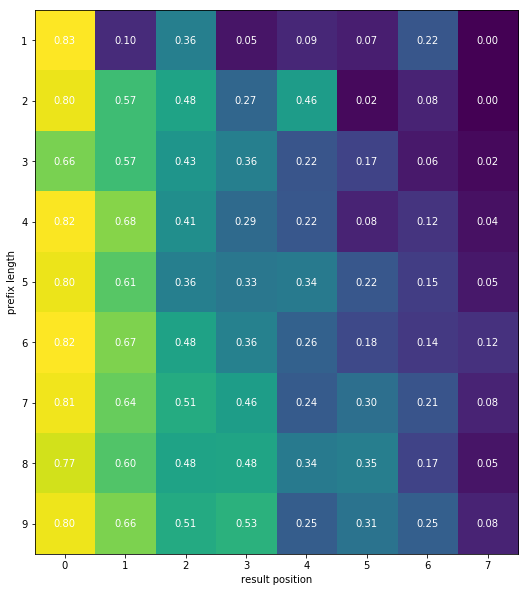
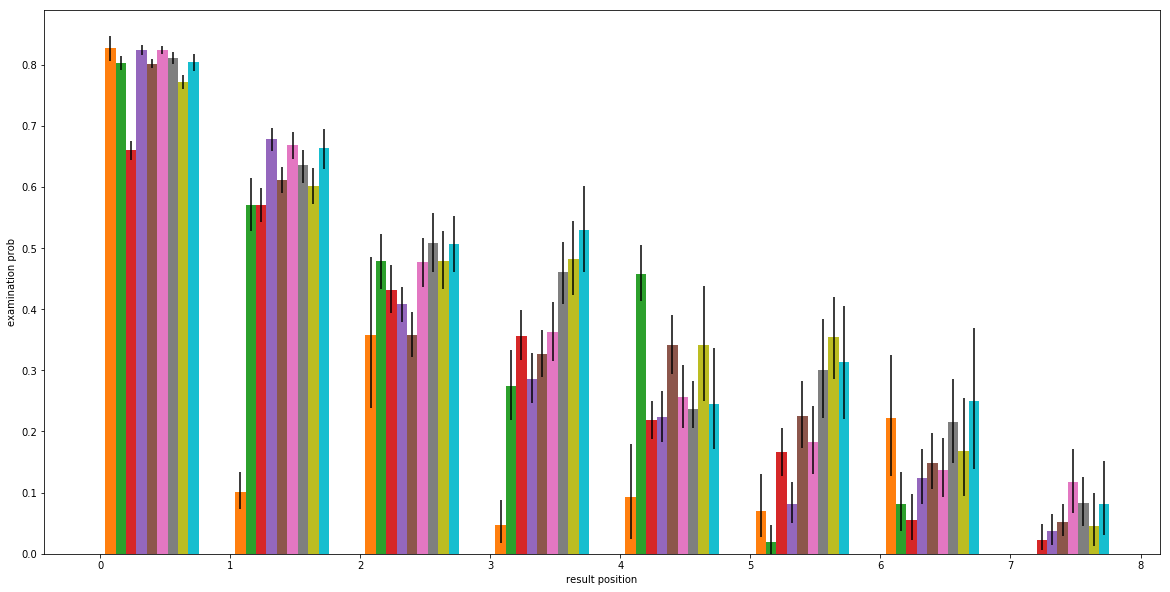
Algorithm 1: Learning the prefix length-independent Aⱼ and the prefix length-dependent Bᵢⱼ probabilities of examination of a query suggestion presented on position j for a prefix of length i.
The algorithm itself is a pretty simple count and ratio. It could be formulated a few ways, but here is a simple pseudocode example:
for session in sessions:
query = session.query
for i in range(len(query) - 1):
j = session.results(query[:i]).index(session.clicked)
if j is not None:
A[j].skipped += 1
B[i][j].skipped += 1
j = session.results(query).index(session.clicked)
A[j].clicked += 1
B[i][j].clicked += 1
A = [a_j.clicked / (a_j.clicked + a_j.skipped) for a_j in A]
B = [b_ij.clicked / (b_ij.clicked + b_ij.skipped) for b_ij in b_i] for b_i in B]Unfortunately we don't have enough data in our autocomplete logging (wikidata or search satisfaction) to calculate this because we don't have any link from eventlogging back to the result sets that were returned. These result sets are logged, but the associated searchToken does not make it into either set of logs. Search satisfaction autocomplete logs that do have a searchToken are erroneous, they all come from Special:Search and record the search token of the full text search and not the autocomplete. Wikidata autocomplete doesn't attempt to collect the searchToken (nor is it available in the api response).
Update eventlogging for wikidata and search satisfaction so we can track examination probabilities, and implement calculation of these values. It's not clear where the implementation goes, but the examination probabilities will be further used for offline evaluation so perhaps it would make sense in mjolnir, or perhaps we need a new repository for autocomplete?