webrequest data loss 2018-11-05 on upload partition
Description
Description
Details
Details
| Subject | Repo | Branch | Lines +/- | |
|---|---|---|---|---|
| profile::cache::kafka::webrequest: filter out Timestamp:Restart logs | operations/puppet | production | +9 -1 |
Event Timeline
Comment Actions
Looking at data loss :
hive (wmf_raw)> select * from webrequest_sequence_stats_hourly where webrequest_source="upload" and year=2018 and month=11 and day=5 and hour in (13,14,15) ;
returns data loss starting at hour 13
hive (wmf_raw)> select percent_lost from webrequest_sequence_stats_hourly where webrequest_source= "upload" and year=2018 and month=11 and day=5 and hour in (13,14,15) ;
OK
percent_lost
2.73796091
7.1342838
7.46537815
Comment Actions
More precise counts per host:
select hostname, count_different, percent_different from webrequest_sequence_stats where webrequest_source= "upload" and year=2018 and month=11 and day=5 and hour in (13) order by count_different limit 10000000 ;
Checking records on webrequest (wmf_raw) without dt we get:
select * from webrequest where year=2018 and month=11 and day=5 and hour=13 and dt="-" and webrequest_source='upload' limit 10;
These returns a bunch of records with accept header WebP
Comment Actions
Ping @Gilles and @BBlack the change for webP might not be working as expected. There are several issues:
- webrequest_upload is getting more requests that it has for a while:
https://grafana.wikimedia.org/dashboard/db/kafka-by-topic?refresh=5m&orgId=1&from=now-30d&to=now
But some of those requests are defective, seems we are double logging some requests
Comment Actions
This is preventing us from refining pageviews (due to alarms of data loss, which seem to be false positives but alert as to something not going as expected up in the pipeline)
Comment Actions
@BBlack: could it be possible that the extra fetch for the .webp variant (when not there) adds a log in the Varnish shared memory log that gets picked up by Varnishkafka? In this case it might not have a timestamp field, generating errors for us (every time that a hot image is fetched and its .webp variant is not there).
Comment Actions
So I confirmed with
sudo varnishlog -n frontend -q 'ReqUrl ~ .*webp' (on cp3035)
that the .webp fetch that fails logs Timestamp:Restart and not Timestamp:End.
Example that I followed:
- Request for /wikipedia/commons/thumb/b/b4/Flag_of_Turkey.svg/22px-Flag_of_Turkey.svg.png, that doesn't have the .webp variant. Ends with Timestamp:Restart
- Right after, same request for 22px-Flag_of_Turkey.svg.png but correctly ending with Timestamp:End.
So my solution would be to filter out requests with Timestamp:Restart at varnishkafka level.
Comment Actions
Change 471786 had a related patch set uploaded (by Elukey; owner: Elukey):
[operations/puppet@production] profile::cache::kafka::webrequest: filter out Timestamp:Restart logs
Comment Actions
Change 471786 merged by Elukey:
[operations/puppet@production] profile::cache::kafka::webrequest: filter out Timestamp:Restart logs
Comment Actions
Exactly, the way the webp support works if that it restarts the Varnish transaction after rewriting the request URL. This is a Varnish feature that hasn't been used much in production before. Sorry for the mess it created in the kafka pipeline, I had not anticipated that it could cause something like this. We can easily turn the feature off if you guys have some fixing to do, and turn it back on later.
Comment Actions
We can easily turn the feature off if you guys have some fixing to do, and turn it back on later.
Thank you. We are going to try to see if our fix (which is ignoring some requests) fixes issue, we just deployed it and will monitor fleet for the next hour. If it were not to work we will ping you.
Comment Actions
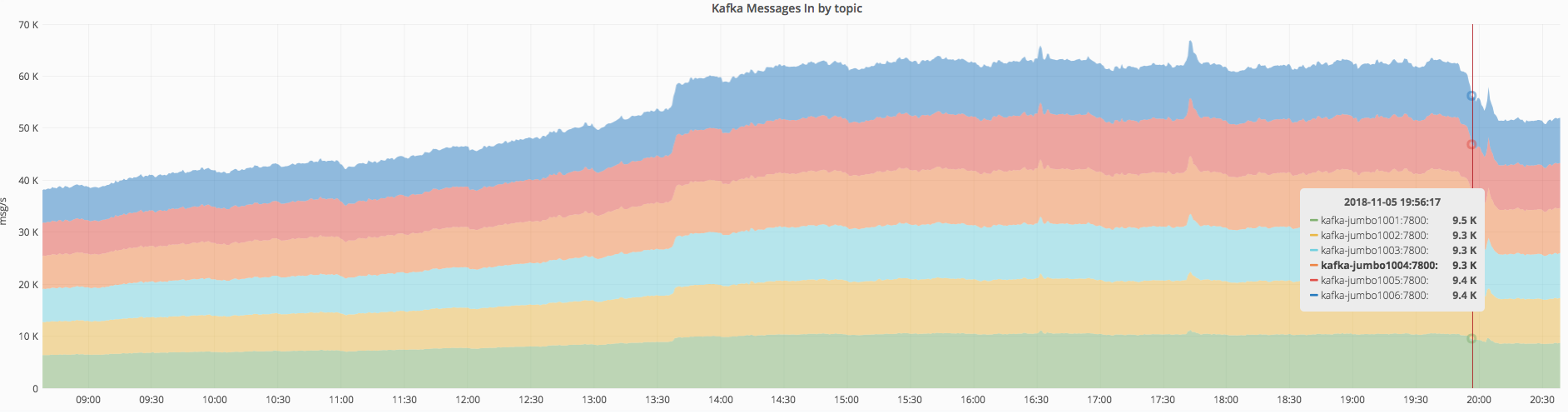
All varnishkafka requests restarted, it seems that the Kafka events volume decreased by the amount that Nuria spotted as anomalous. All good from what I can see!
Comment Actions
To keep archive happy: Failed refinement hours were 13->19 (included) on webrequest_source = 'upload', 2018-11-05.
I refined them manually 2018-11-06 and marked them as done manually as well.