In the interest of preserving history, I'm resurrecting this task and proposing at least part of the design.
NFS services provided by VMs on Ceph using an attached volume (cinder). The VMs would implement quotas per project and would have likely implement the current server layout of labstore1004/5. They would need to operate on quiet or dedicated-ish hardware and would merit some stress testing before migration of data and mounts. If cinder isn't used to provide Kubernetes volumes directly, such VMs could also provide that via NFS.
Original task description:
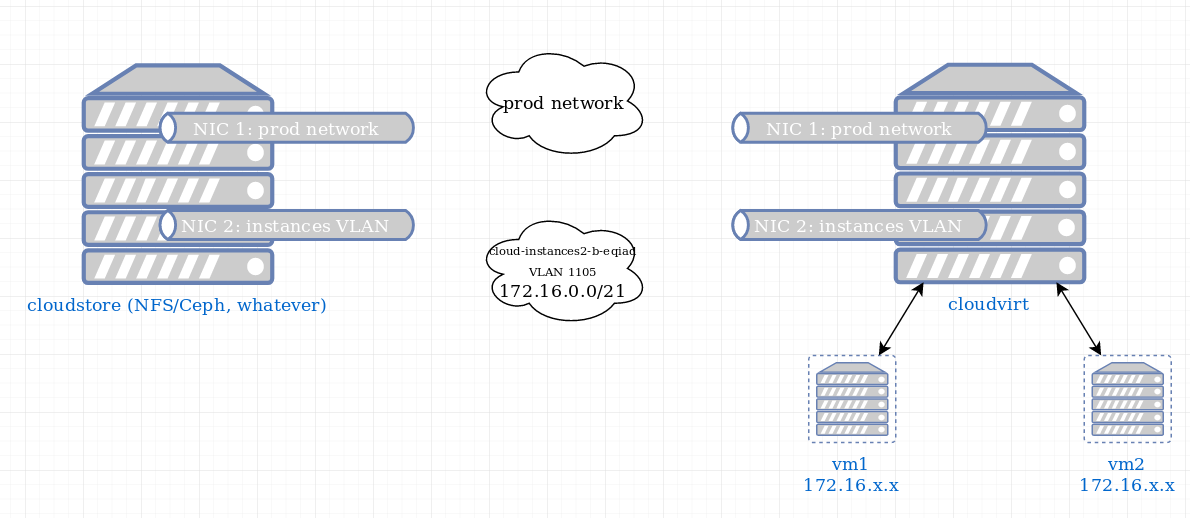
Consider virtualizing NFS servers by converting labstore servers into cloudvirt servers with a single giant VM instance running on them. This will bring the NFS servers themselves into the internal 172.16.x.x address space and increase isolation from Wikimedia production networks and servers.
- labstore1004 & labstore1005
- cloudstore1008 & cloudstore1009 (which are the planned replacements for labstore1003)