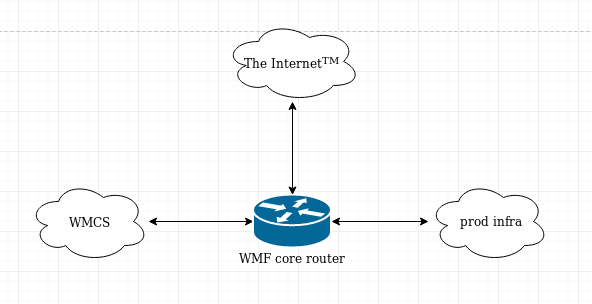
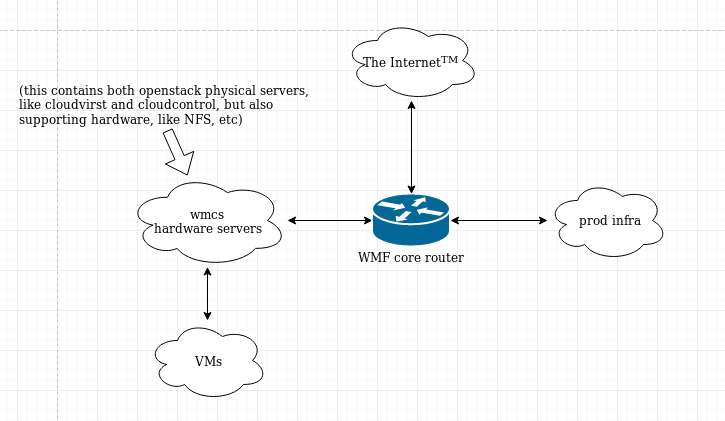
I assume the Nova API and Neutron themselves can't be moved. And obviously the virt servers can't be. And LDAP, though named for 'labs', has outgrown that and is trusted by prod for various things so that can't go anywhere.
Here are some potential ones to consider:
- OpenStack Designate (auth DNS)
OpenStack Keystone (OpenStack identity/auth)(see T207536#4735654)- OpenStack Glance (instance images)
OpenStack Horizon (dashboard)(see T207536#4735633)Wikimedia Striker (toolsadmin)(see T207536#4735633)DB replicas(see T207536#4735648)- NFS - there is a wmcs-nfs project already but that is for testing
- The new Elastic replicas (which haven't been set up yet, see T194186)
I'm not arguing in particular for any individual service on the list to be migrated, feel free to shoot any down that can't/shouldn't be moved in the comments and strikethrough it in the description. If you think one should be moved, open a subtask and edit it out of this description.