- Collect fundamental statistics from the external sources for the Wikidata Languages Landscape.
- Develop reports, visualizations, and dashboards for the languages project.
Description
Description
| Status | Subtype | Assigned | Task | ||
|---|---|---|---|---|---|
| Resolved | GoranSMilovanovic | T221965 Wikidata Languages Landscape | |||
| Resolved | GoranSMilovanovic | T223119 WD Languages Landscape: statistics + dashboards |
Event Timeline
Comment Actions
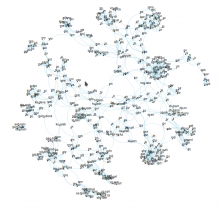
Something to begin with:
- each node is a language (Wikimedia language codes are used);
- each language points towards the three most similar languages to it,
- in terms of the overlap in the respective language labels across >57M Wikidata items:
- (explanation: for each language we search what WD items have a label in it,
- then: similarity between two languages == Jaccard distance between two binary vectors of length approx. 57M each).

Mapping WDCM item re-use statistics onto languages now.
Comment Actions
@Lydia_Pintscher
You can take a look at our WikidataCon2019 shared doc and see if you can make use of anything from the Wikidata Languages Landscape: Statistics and Visualizations section.