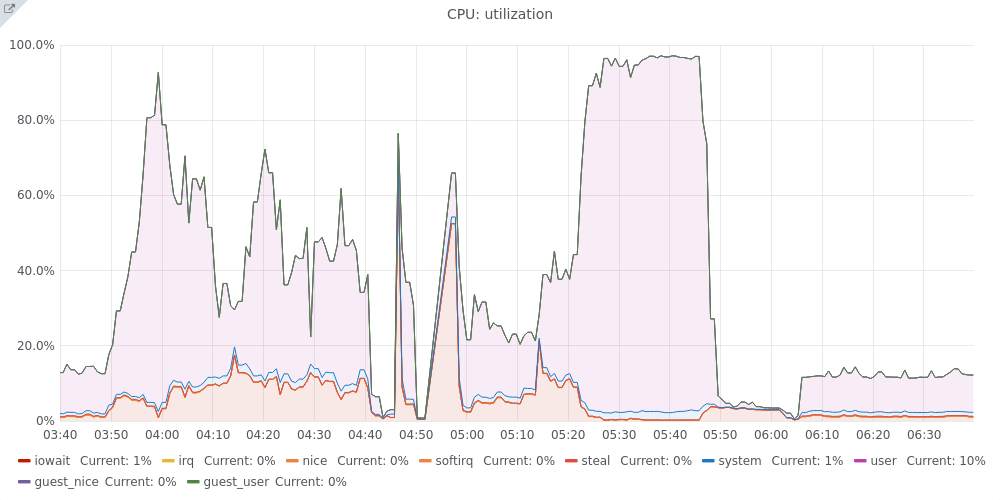
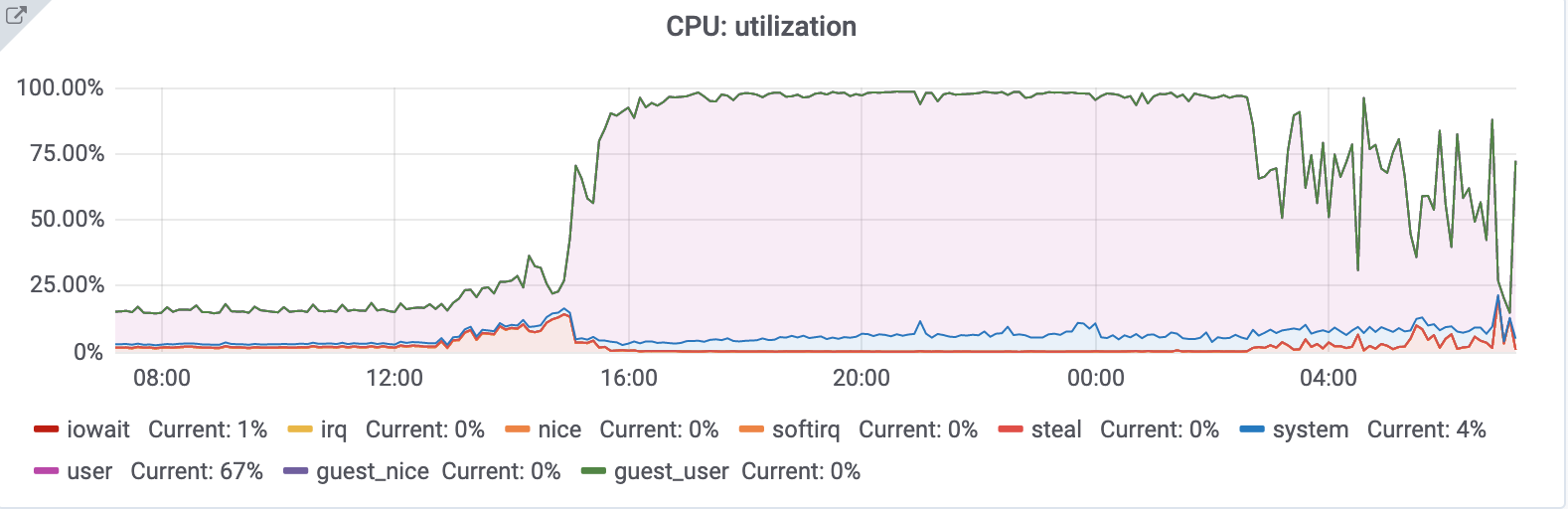
Tendril seems to be having an excessive amount of memory consumption that keeps growing over the time until it makes OOM to kick in and start killing some processes, typically MySQL or nagios, causing pages
Examples of some tasks:
T231165: db1115 (tendril) paged twice in 24h due to OOM
T196726: db1115 (tendril DB) had OOM for some processes and some hw (memory) issues
Some graphs that show this behavior:
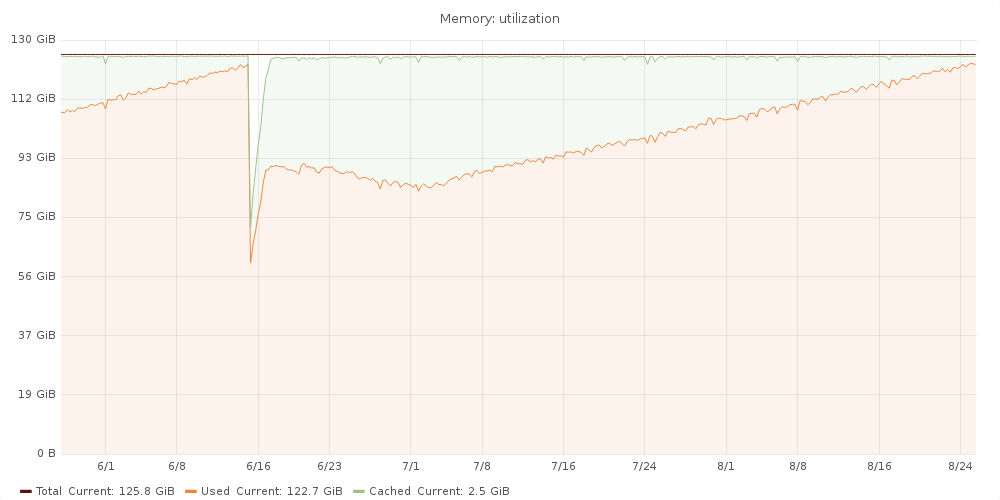
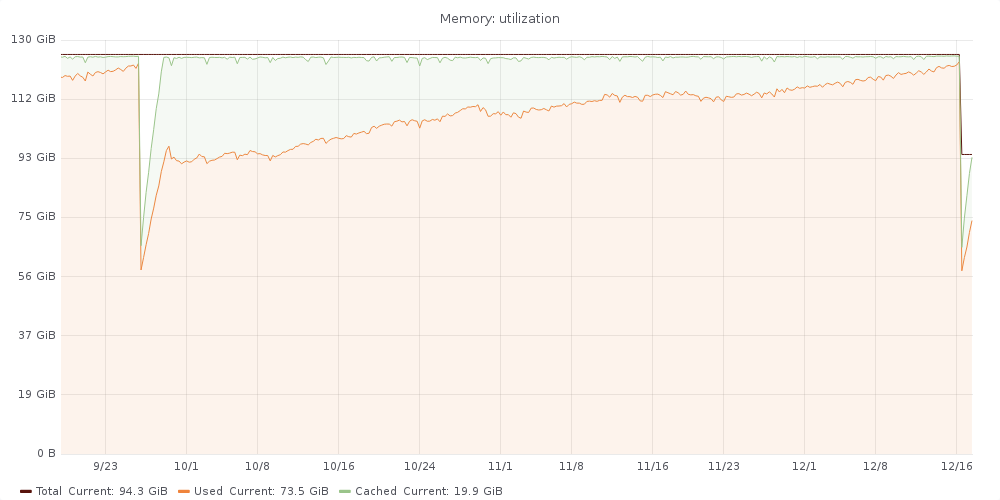
MySQL pool size is already quite low:
innodb_buffer_pool_size = 20G
Given that we don't really know at this point what can be causing that excessive and steady memory usage, let's disable/remove stuff that we don't currently use.
Tendril has lots of events, triggers, graphing and so forth, that we don't use anymore, and can probably be disabled without affecting anything on our current workflow.