NOTE: This project has received fewer contributions and is actively seeking new contributors.
Wikimedia uses over 200 MariaDB instances to store content and metadata for Wikipedia and other free knowledge projects. While standard open source tools for both monitoring and automation are used when possible, there are some tasks that require custom development. There are 2 options for a project to choose here:
- Proof of concept of a web-based dashboard that will be used for inventory and/or summary of the status of the MariaDB fleet. While there is already an existing tool, Tendril also used for DBTree, it has degraded over time and doesn't take advantage of (or integrate with) modern technologies available at Wikimedia such as prometheus+grafana metrics monitoring, performance_schema, pt-heartbeat, or our database backup system. There is also the need of a d3-based (javascript) replacement for https://dbtree.wikimedia.org.
Mockups for inspiration: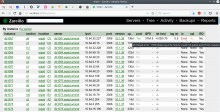

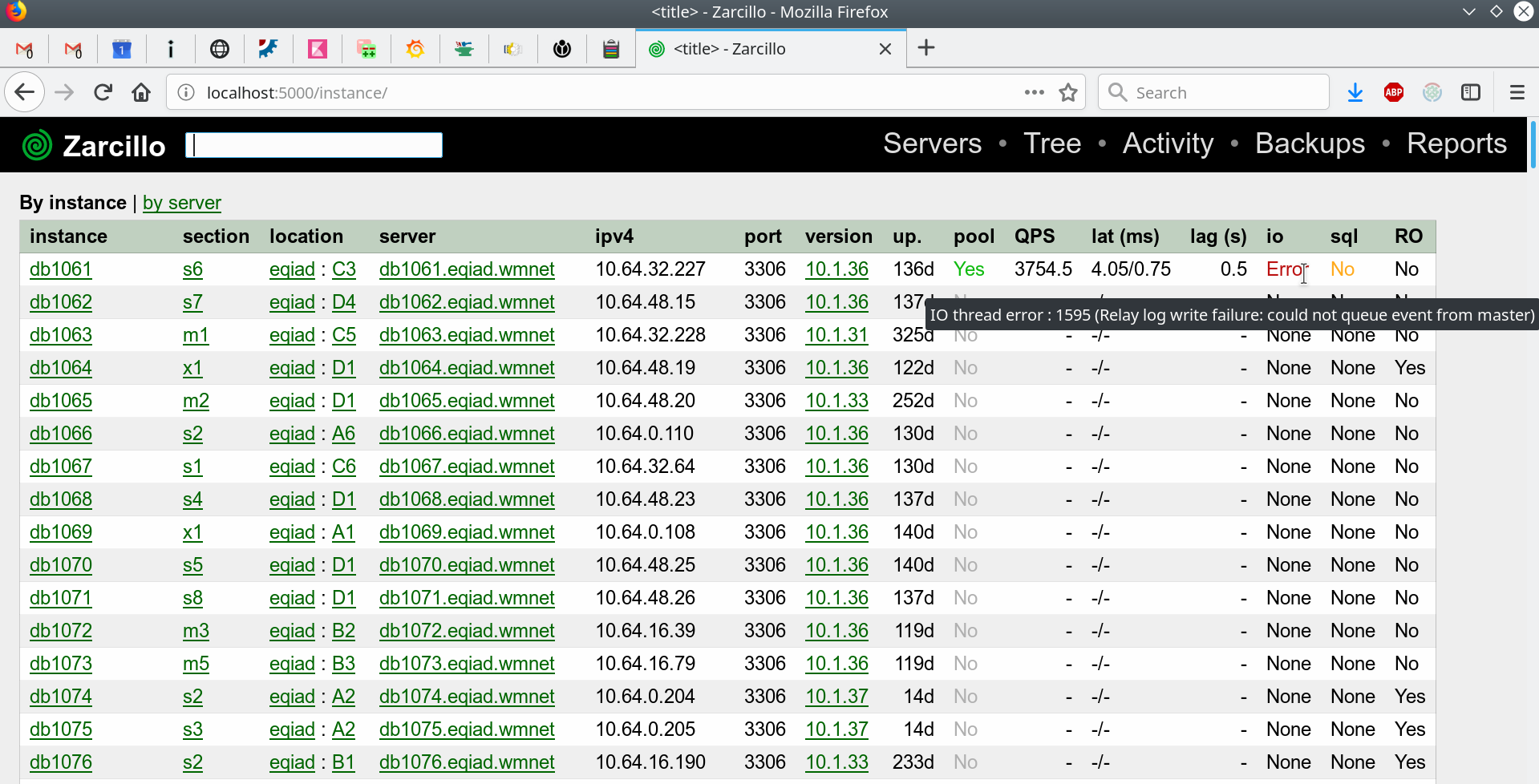
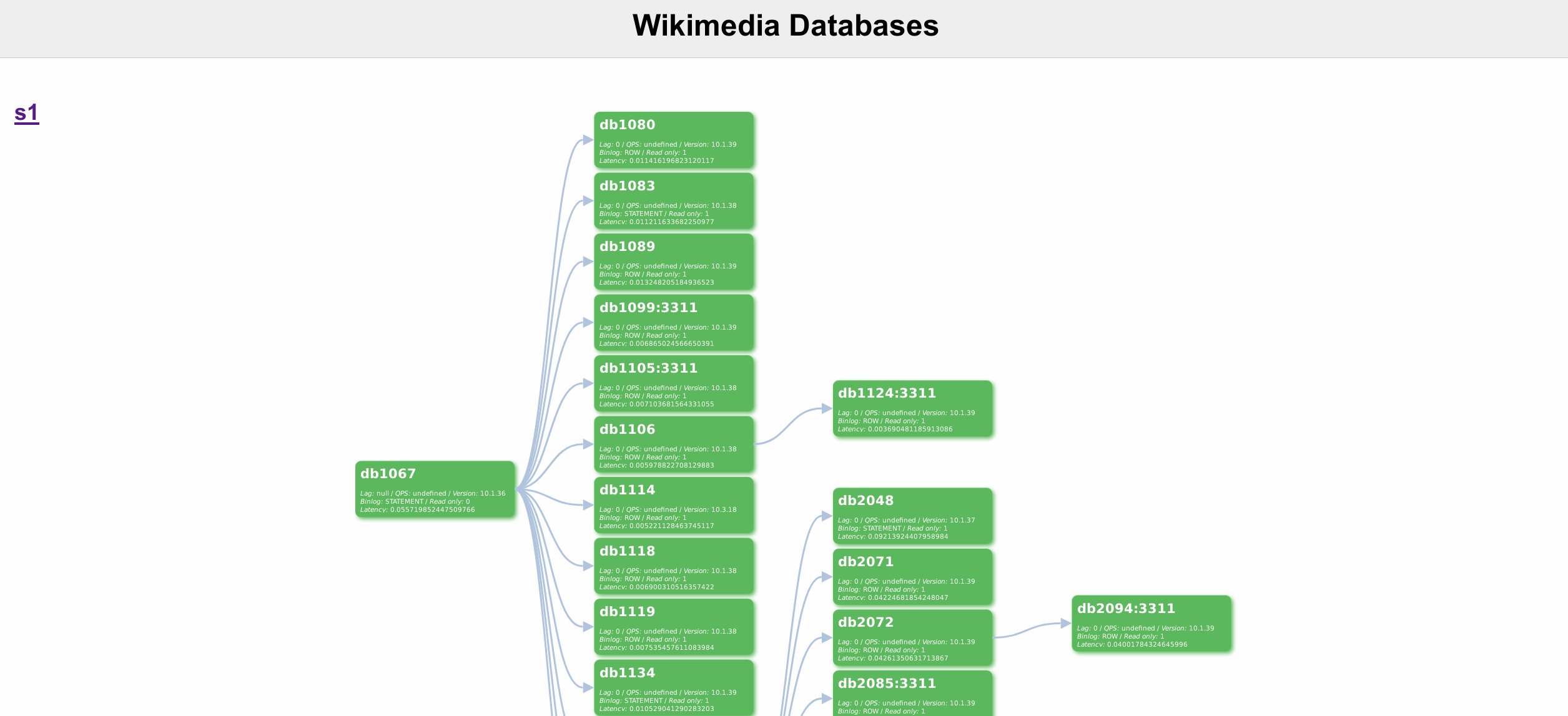
- Small-scope command line utilities to perform maintenance and monitoring tasks, such as: data checks between servers, data transfers, consistency checks between data and metadata, strange MariaDB process monitoring, and more.
Integration of existing libraries and tools should be preferred when possible, rather than custom solutions, as well as focusing on future extensibility and maintainability rather than a large scope.
- Skills required: Python (preferred) or PHP, SQL
- Mentors: Jaime Crespo aka #jynus [@jcrespo], Manuel Arostegui [@Marostegui]
There are a few tasks related to the above project with the details, they are listed below as subtasks. These are examples of task within the scope, others are possible too, but only 1 or 2 should be chosen to work on (not all).