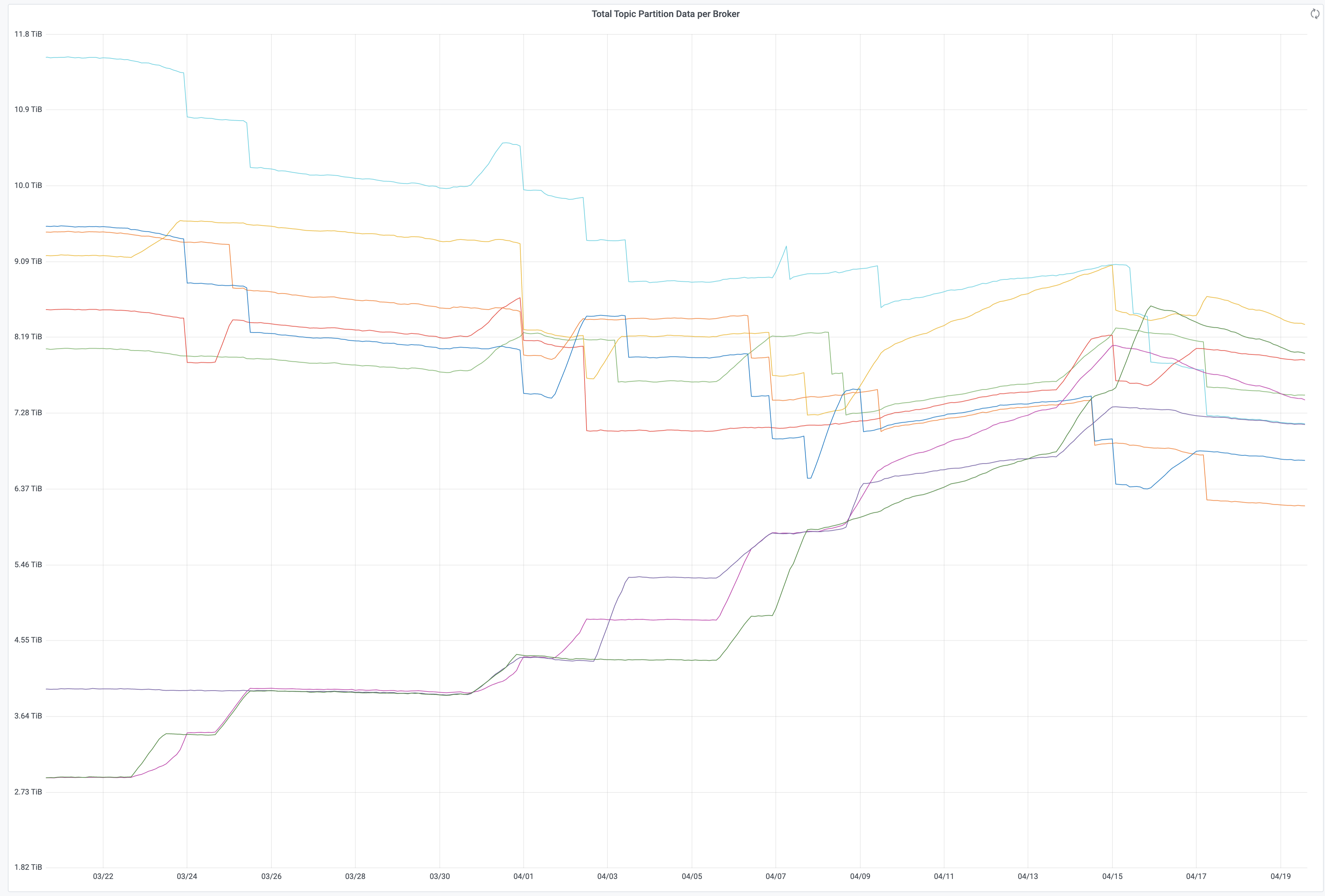
In T252675 we added 3 new Brokers to Kafka Jumbo, kafka-jumbo100[7,8,9]. In this task we should find a way to move topic partitions to the new brokers to better balance the cluster.
Progress: (topic: messages / second)
- eqiad.mediawiki.job.ChangeDeletionNotification: 7.9
- eventlogging_ExternalGuidance: 8.1
- codfw.mediawiki.page-properties-change
- eqiad.mediawiki.page-properties-change: 8.883333333333333
- eventlogging_FirstInputTiming: 10.35
- eventlogging_TemplateDataApi: 10.433333333333334
- eventlogging_CodeMirrorUsage: 11.016666666666667
- codfw.mediawiki.revision-tags-change
- eqiad.mediawiki.revision-tags-change: 11.633333333333333
- codfw.mediawiki.job.wikibase-InjectRCRecords
- eqiad.mediawiki.job.wikibase-InjectRCRecords: 11.8
- codfw.mediawiki.job.ORESFetchScoreJob
- eqiad.mediawiki.job.ORESFetchScoreJob: 12.766666666666667
- codfw.mediawiki.job.categoryMembershipChange
- eqiad.mediawiki.job.categoryMembershipChange: 12.983333333333333
- eventlogging_MobileWikiAppDailyStats: 13.316666666666666
- eventlogging_EditAttemptStep: 14.116666666666667
- eventlogging_QuickSurveyInitiation: 16.766666666666666
- codfw.mediawiki.page-links-change
- eqiad.mediawiki.page-links-change: 17.466666666666665
- eventlogging_CpuBenchmark: 17.9
- codfw.mediawiki.revision-score
- eqiad.mediawiki.revision-score: 17.933333333333334
- eventlogging_ResourceTiming: 18.866666666666667
- eventlogging_RUMSpeedIndex: 18.933333333333334
- codfw.mediawiki.revision-create
- eqiad.mediawiki.revision-create: 21.033333333333335
- eventlogging_NavigationTiming: 26.816666666666666
- codfw.resource_change
- eqiad.resource_change: 31.53333333333333
- codfw.mediawiki.recentchange
- eqiad.mediawiki.recentchange: 32.93333333333333
- codfw.mediawiki.job.recentChangesUpdate
- eqiad.mediawiki.job.recentChangesUpdate: 36.05
- eventlogging_LayoutShift: 37.1
- eventlogging_DesktopWebUIActionsTracking: 39.28333333333333
- eventlogging_PaintTiming: 39.75
- codfw.mediawiki.job.cdnPurge
- eqiad.mediawiki.job.cdnPurge: 46.266666666666666
- eventlogging_InukaPageView: 49.63333333333333
- statsv: 54.9
- eventlogging_CentralNoticeImpression: 58.86666666666667
- codfw.wdqs-external.sparql-query
- eqiad.wdqs-external.sparql-query: 73.2
- codfw.mediawiki.job.htmlCacheUpdate
- eqiad.mediawiki.job.htmlCacheUpdate: 76.65
- __consumer_offsets: 94.89999999999999
- codfw.wdqs-internal.sparql-query
- eqiad.wdqs-internal.sparql-query: 105.98333333333333
- codfw.mediawiki.job.refreshLinks
- eqiad.mediawiki.job.refreshLinks: 112.6
- codfw.mediawiki.job.RecordLintJob
- eqiad.mediawiki.job.RecordLintJob: 113.61666666666666
- eventlogging_MobileWikiAppLinkPreview: 117.36666666666666
- codfw.mediawiki.job.wikibase-addUsagesForPage
- eqiad.mediawiki.job.wikibase-addUsagesForPage: 130.48333333333332
- eventlogging_MobileWikiAppSessions: 166.25
- eqiad.resource_change
- codfw.resource_change: 252.06666666666666
- codfw.mediawiki.client.session_tick
- eqiad.mediawiki.client.session_tick: 451.6666666666667
- eventlogging_SearchSatisfaction: 529.0166666666667
- eventlogging_VirtualPageView: 1206.0666666666666
- codfw.resource-purge
- eqiad.resource-purge: 1877.0166666666669
- eventlogging-client-side: 1952.9166666666665
- codfw.mediawiki.cirrussearch-request
- eqiad.mediawiki.cirrussearch-request: 3334.116666666667
- atskafka_test_webrequest_text: 3818.0333333333333
- netflow: 4522.383333333333
- codfw.mediawiki.api-request
- eqiad.mediawiki.api-request: 8553.283333333333
- webrequest_upload (24 partitions): 24/24: 73291.51666666666
- webrequest_text (24 partitions): 5/24: 122753.08333333334