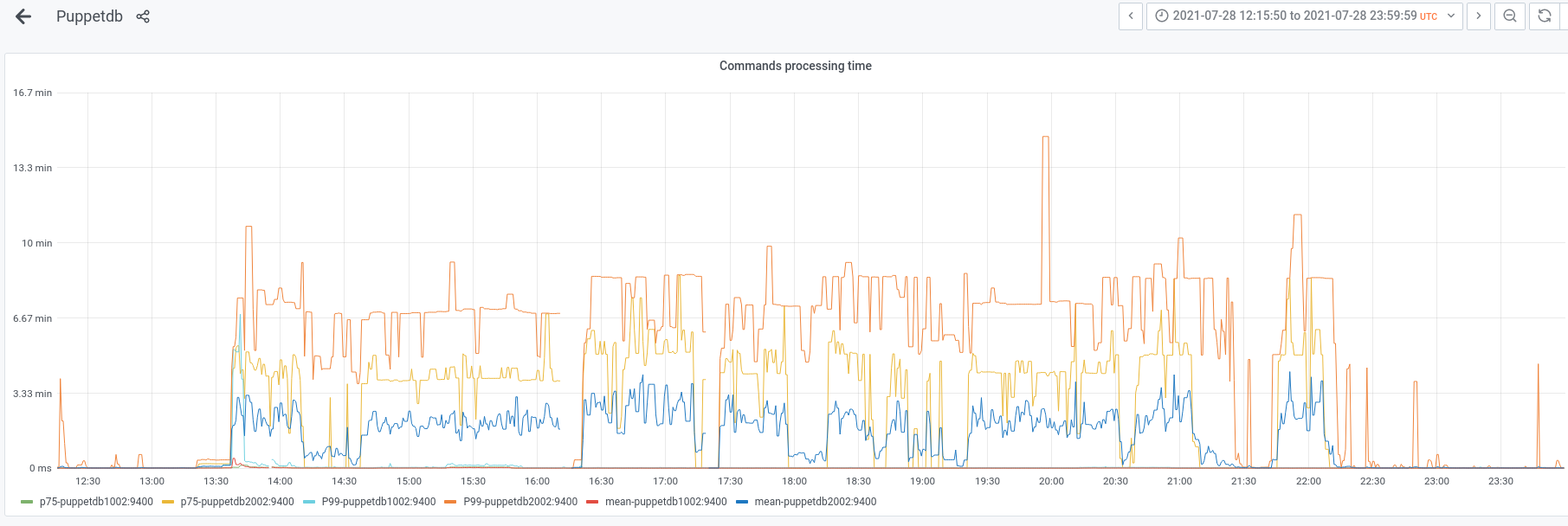
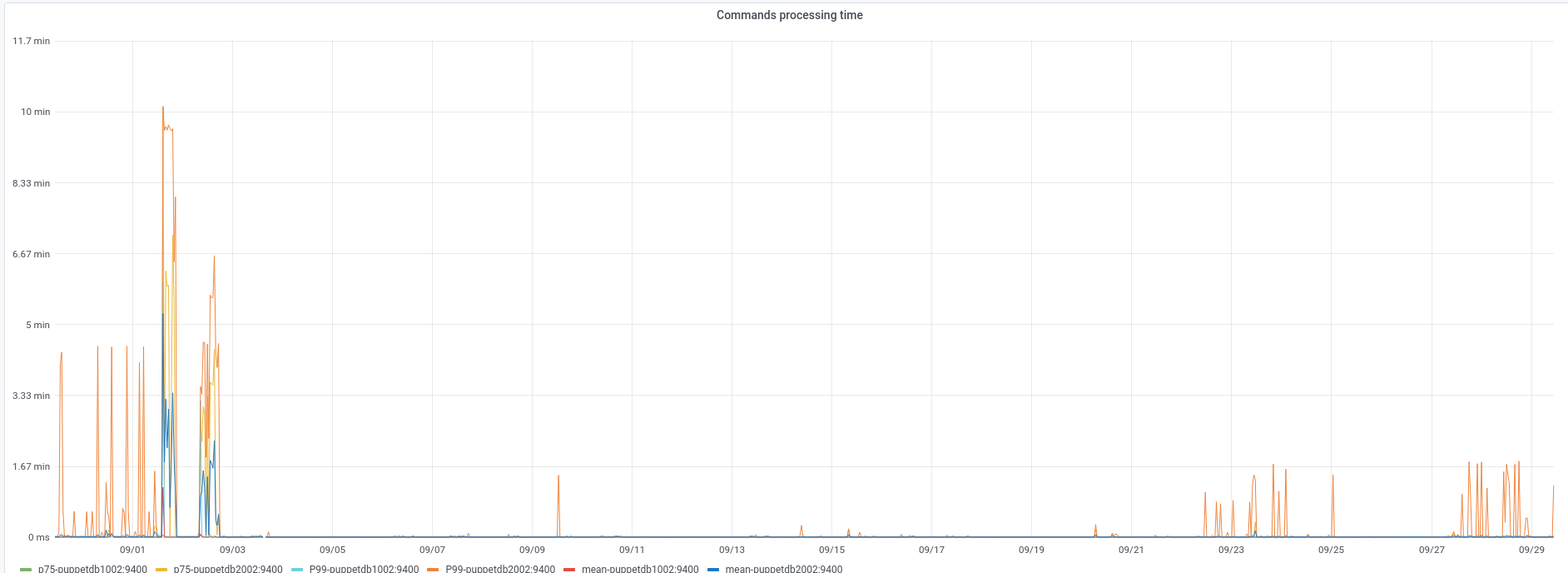
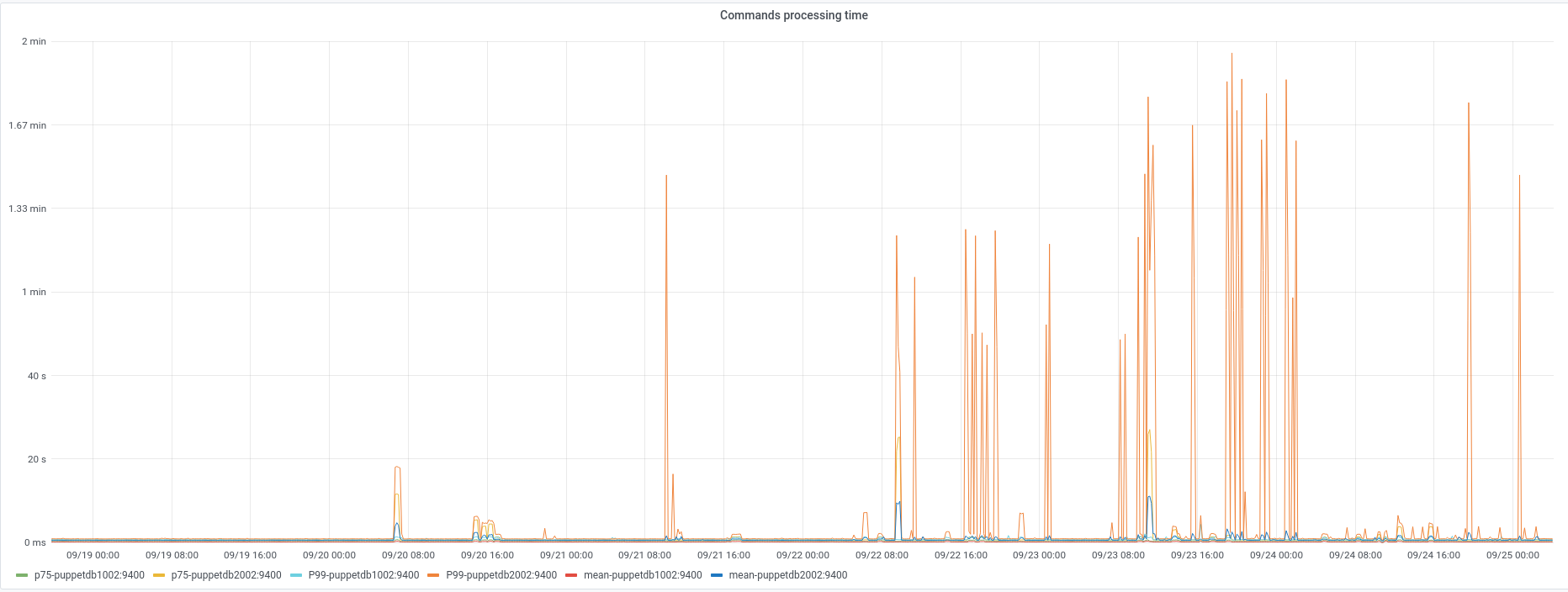
@Papaul has reported some failures in the reimages in codfw. In all cases cumin2001 is failing to reboot the host because of missing the host key in the known hosts files even after the reimage script runs puppet on cumin2001.
This seems due to some "slowness" in PuppetDB, apparently more pronounced when hitting the codfw endpoint given that it seems it doesn't happen in eqiad (yet?).
Looking at puppetboard is clear that the puppet run on cumin2001 didn't add the new key and it gets added at the next run.
I've noticed in puppetdb2002 logs that the newly reimage host requests are pretty slow while they return to normal speed after the first runs.
$ grep maps2007 /var/log/puppetdb/puppetdb.log 2020-09-22T16:49:07.163Z INFO [p.p.command] [6920576-1600793314103] [33053 ms] 'replace facts' command processed for maps2007.codfw.wmnet 2020-09-22T16:52:39.061Z INFO [p.p.command] [6920581-1600793319454] [211865 ms] 'replace catalog' command processed for maps2007.codfw.wmnet 2020-09-22T16:52:56.040Z INFO [p.p.command] [6920730-1600793510925] [65067 ms] 'store report' puppet v5.5.10 command processed for maps2007.codfw.wmnet 2020-09-22T16:57:51.132Z INFO [p.p.command] [6921001-1600793864301] [6776 ms] 'replace catalog' command processed for maps2007.codfw.wmnet 2020-09-22T16:58:00.829Z INFO [p.p.command] [6921011-1600793879724] [1096 ms] 'store report' puppet v5.5.10 command processed for maps2007.codfw.wmnet 2020-09-22T16:58:12.900Z INFO [p.p.command] [6920998-1600793859260] [33633 ms] 'replace facts' command processed for maps2007.codfw.wmnet 2020-09-22T17:09:49.713Z INFO [p.p.command] [6921542-1600794589093] [614 ms] 'replace facts' command processed for maps2007.codfw.wmnet 2020-09-22T17:09:55.388Z INFO [p.p.command] [6921546-1600794594102] [1230 ms] 'replace catalog' command processed for maps2007.codfw.wmnet 2020-09-22T17:10:07.579Z INFO [p.p.command] [6921561-1600794607019] [535 ms] 'store report' puppet v5.5.10 command processed for maps2007.codfw.wmnet 2020-09-22T17:39:47.507Z INFO [p.p.command] [6922899-1600796386980] [519 ms] 'replace facts' command processed for maps2007.codfw.wmnet 2020-09-22T17:39:53.468Z INFO [p.p.command] [6922905-1600796392117] [1271 ms] 'replace catalog' command processed for maps2007.codfw.wmnet
While I don't see the same pattern in a host reimaged in eqiad:
2020-09-22T17:02:07.653Z INFO [p.p.command] [9294140-1600794127628] [15 ms] 'deactivate node' command processed for an-worker1101.eqiad.wmnet 2020-09-22T17:23:25.746Z INFO [p.p.command] [9295662-1600795405509] [227 ms] 'replace facts' command processed for an-worker1101.eqiad.wmnet 2020-09-22T17:23:33.735Z INFO [p.p.command] [9295670-1600795410672] [2995 ms] 'replace catalog' command processed for an-worker1101.eqiad.wmnet 2020-09-22T17:33:25.822Z INFO [p.p.command] [9296433-1600796004907] [867 ms] 'store report' puppet v5.5.10 command processed for an-worker1101.eqiad.wmnet 2020-09-22T17:41:30.269Z INFO [p.p.command] [9296963-1600796489912] [348 ms] 'replace facts' command processed for an-worker1101.eqiad.wmnet 2020-09-22T17:41:36.086Z INFO [p.p.command] [9296975-1600796495402] [622 ms] 'replace catalog' command processed for an-worker1101.eqiad.wmnet 2020-09-22T17:41:57.488Z INFO [p.p.command] [9297003-1600796517405] [72 ms] 'store report' puppet v5.5.10 command processed for an-worker1101.eqiad.wmnet 2020-09-22T17:50:09.042Z INFO [p.p.command] [9297592-1600797008966] [65 ms] 'replace facts' command processed for an-worker1101.eqiad.wmnet
I think we should look at why puppetdb2002 is so slow in certain requests.
That said I also looked briefly at the postgres DB and I'm wondering if we could improve our configuration, in particular regarding vacuum because it seems too big to me for the data it should hold, but maybe it's all normal.
On Grafana the filesystem utilization on puppetdb1002 is growing but slowly, maybe related to the normal grow of the catalogs and hosts.
For what is worth I'm reporting here some data, might be useful if we start looking at it or even if just to compare back in few weeks.
Total size of the DB
name | owner | size -----------+----------+--------- puppetdb | puppetdb | 16 GB
Biggest relations:
relation | size -----------------------------------------------------+--------- public.idx_factsets_jsonb_merged | 4999 MB public.edges_certname_source_target_type_unique_key | 3352 MB public.catalog_resources | 1473 MB public.edges | 1100 MB public.fact_paths_path_trgm | 673 MB public.catalog_resources_encode_idx | 568 MB public.resource_params_hash_expr_idx | 516 MB
Total size of biggest tables:
relation | total_size ------------------------------+------------ public.factsets | 5040 MB public.edges | 4454 MB public.catalog_resources | 3419 MB public.resource_params | 1933 MB public.fact_paths | 867 MB public.resource_params_cache | 363 MB
With more detailed info:
table_schema | table_name | row_estimate | total | index | toast | table --------------------+-------------------------+--------------+------------+------------+------------+------------ public | factsets | 1623 | 5040 MB | 5002 MB | 35 MB | 2696 kB public | edges | 8.3642e+06 | 4454 MB | 3353 MB | 8192 bytes | 1101 MB public | catalog_resources | 3.2955e+06 | 3419 MB | 1946 MB | 8192 bytes | 1474 MB public | resource_params | 3.37787e+06 | 1933 MB | 1479 MB | 46 MB | 408 MB public | fact_paths | 239540 | 867 MB | 788 MB | 8192 bytes | 79 MB public | resource_params_cache | 271284 | 363 MB | 100 MB | 51 MB | 212 MB public | reports | 72713 | 270 MB | 61 MB | 27 MB | 182 MB public | resource_events | 15140 | 168 MB | 154 MB | 216 kB | 14 MB public | catalogs | 1623 | 3096 kB | 2256 kB | 8192 bytes | 832 kB public | certnames | 1623 | 1944 kB | 1512 kB | 8192 bytes | 424 kB `