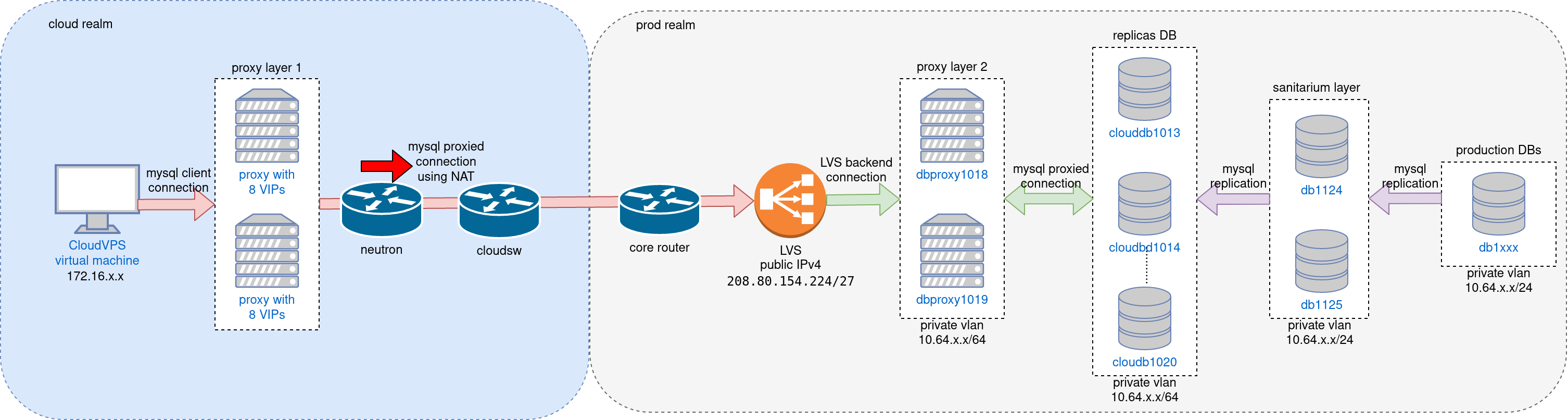
For the multi-instance wiki replicas, we will need to have one IP address per section assigned to the proxies (dbproxy101[89].eqiad.wmnet). That's 8 vips for each proxy type (2 proxies) that will only need to move when new proxy servers are put in play.
At this time, everything will connect via IPv4, but we would like these Cloud VMs to be IPv6 capable in the future.
The naming associated with these inside Cloud VPS will be:
s1.analytics.db.svc.wikimedia.cloud
s2.analytics.db.svc.wikimedia.cloud
s3.analytics.db.svc.wikimedia.cloud
s4.analytics.db.svc.wikimedia.cloud
s5.analytics.db.svc.wikimedia.cloud
s6.analytics.db.svc.wikimedia.cloud
s7.analytics.db.svc.wikimedia.cloud
s8.analytics.db.svc.wikimedia.cloud
s1.web.db.svc.wikimedia.cloud
s2.web.db.svc.wikimedia.cloud
s3.web.db.svc.wikimedia.cloud
s4.web.db.svc.wikimedia.cloud
s5.web.db.svc.wikimedia.cloud
s6.web.db.svc.wikimedia.cloud
s7.web.db.svc.wikimedia.cloud
s8.web.db.svc.wikimedia.cloud
The equivalent names are currently managed by Designate (using the eqiad.wmflabs domain). So we need to allocate 16 IPs (and possibly IPv6 IPs?) and have the name records somewhere sane.
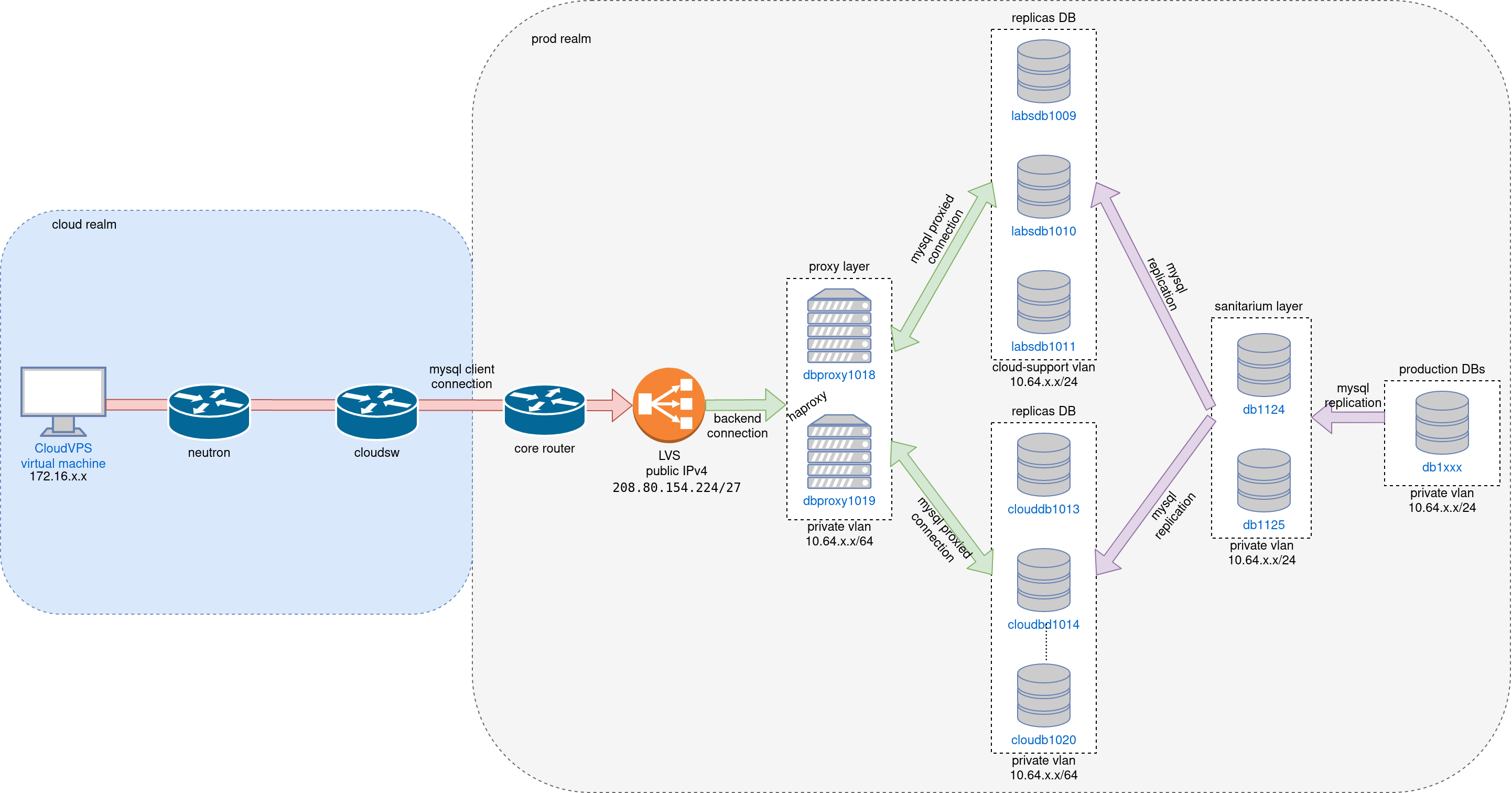
Currently, we do not have multi-instance replicas, so everything connects to a single IP for each proxy. The existing proxies are:
- dbproxy1018.eqiad.wmnet (10.64.37.27)
- dbproxy1019.eqiad.wmnet (10.64.37.28)
These are likely to remain the proxy machines after all this. Cloud instances connect to MariaDB via these hosts over port 3306. They will still do that, but the proxies will be routing to other ports and hosts than they do now on the backend.