When we have to do an unscheduled failover, we cannot use switchover, as that assumes the master is up and running.
Creating a failover.py will be a quite hard task, as we have to assume all possible ways in which servers can fail- it will likely be handled by orchestrator.
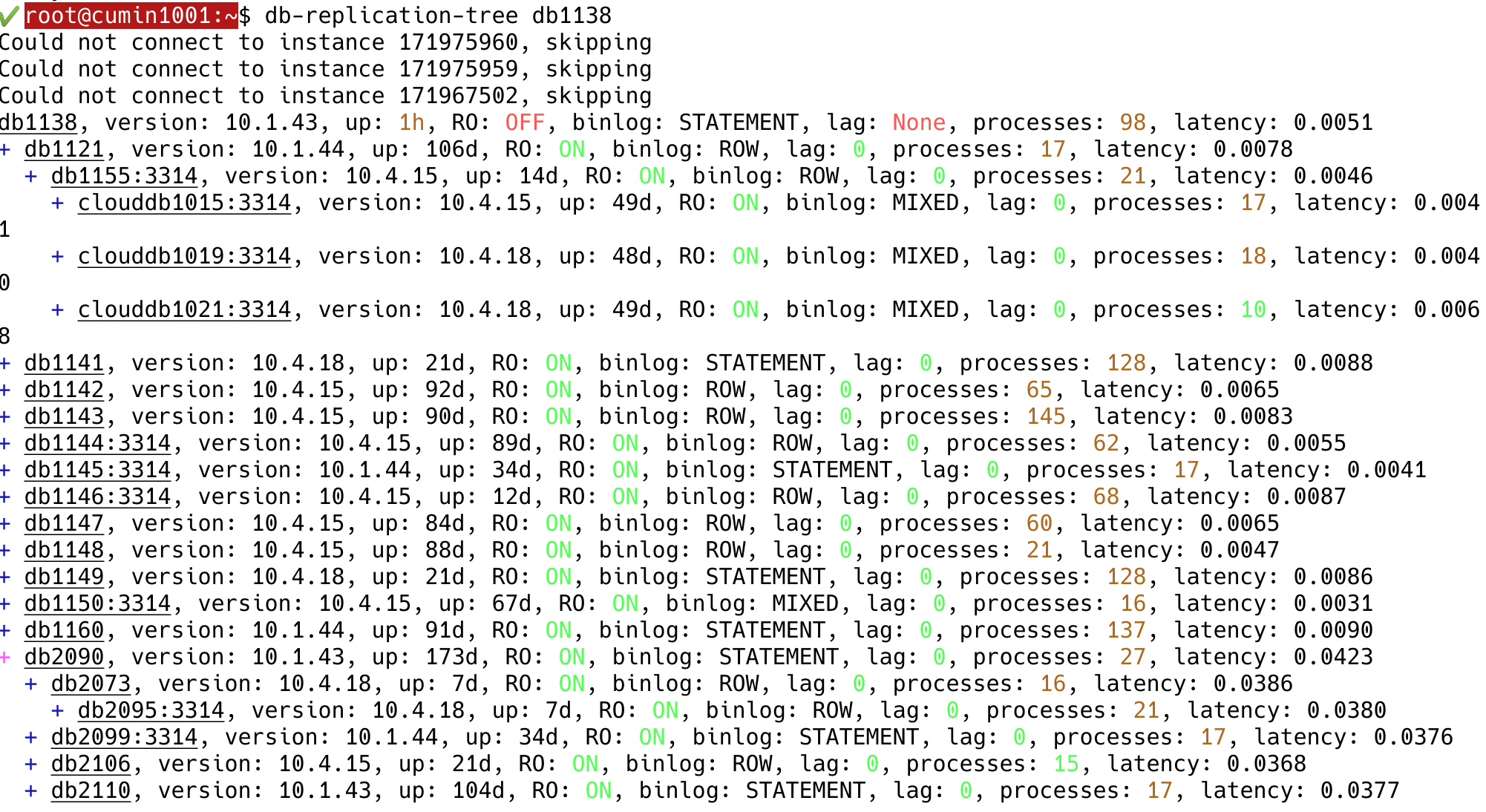
For now, it would be nice to have a simple way to check the replication status (up to what point a host has replicated to, using GTID or binlog position).
This was run last time: P15586, but:
- I don't want to think about how to use undeployed scripts and syntax problems under pressure
- I don't want to check which are direct and which are undirect replicas
- I don't care about non-core hosts (backups, dbstores, labsdbs, ...)
Maybe it could be integrated into db-replication-tree, but it won't work just by adding an additional field there, as it has to work even if the master cannot be connected to, and other host could be down. Maybe it could use zarcillo or other cached list (orchestrator?).
Ideally, it would show something like this, clearly:
db1111 master => (unavailable) or "1123456778 / GTID: 12345678"
db1112 candidate => "1123456778" (good, with color?
db1113 direct replica => "12345677" (bad, not up to date)