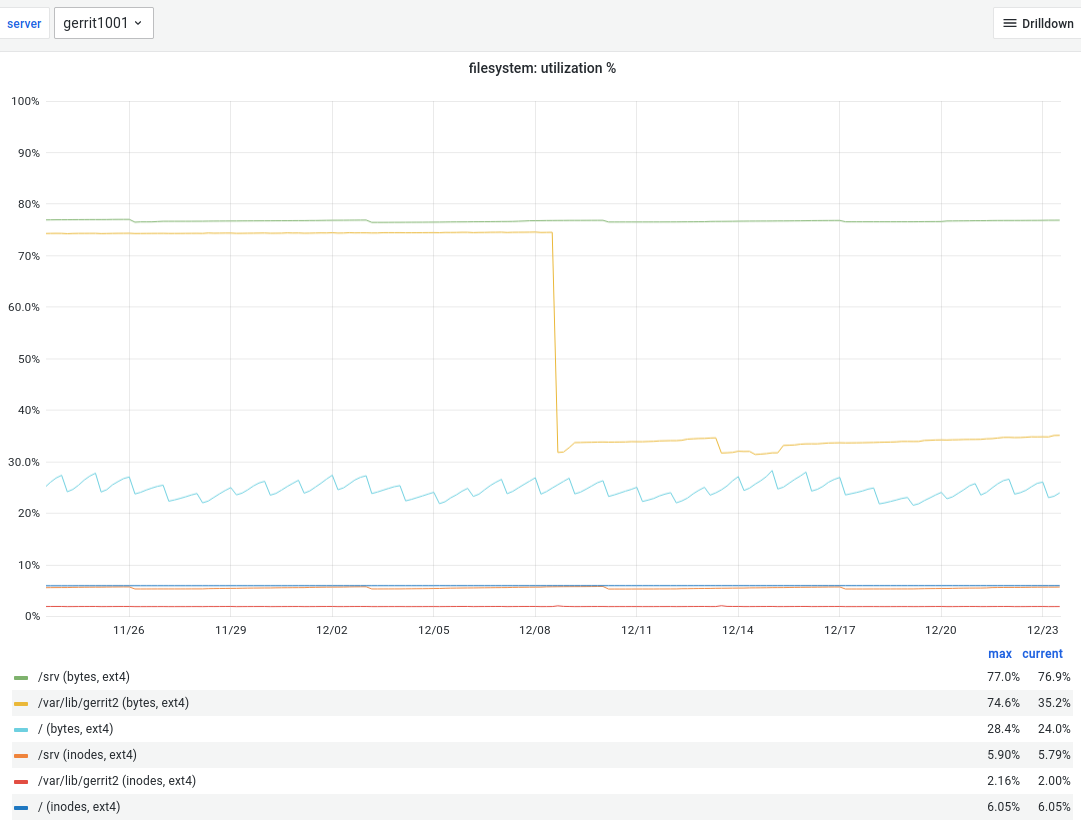
Following the Gerrit upgrade (T307334) gerrit1001 ran out of space on /. This resulted in any write action (submit +2, rebase, remove +2 vote) resulting in a modal error 500 Internal Server Error.
To mitigate, a new volume was created, /var/lib/gerrit2 was copied to it and mounted.
Follow up actions:
RelEng
- Clean up the h2 cache (RelEng) - T323754
- And drop obsolete h2 cache files (RelEng) - T324771
- Clean up /srv/ on gerrit1001 (lot of copy of repositories)
- Add a step to the Gerrit upgrade procedure to check for disk space (RelEng)
- Adjust upgrade documentation to no more disable all monitoring probes (RelEng)
- Write incident report https://wikitech.wikimedia.org/wiki/Incidents/2022-11-17_Gerrit_3.5_upgrade (Antoine, RelEng)
- Prepare a Gerrit overview presentation for SRE (Antoine)
SRE:
- Bring primary and replica in sync configuration-wise (SRE)
- summarize disk stuff (Partman recipe etc.) on the task
- Verify alerting to see if we should have been warned in advance (SRE)
Together?
- Introduce regular cache clean-up
- Test failover (and plan regular failovers)