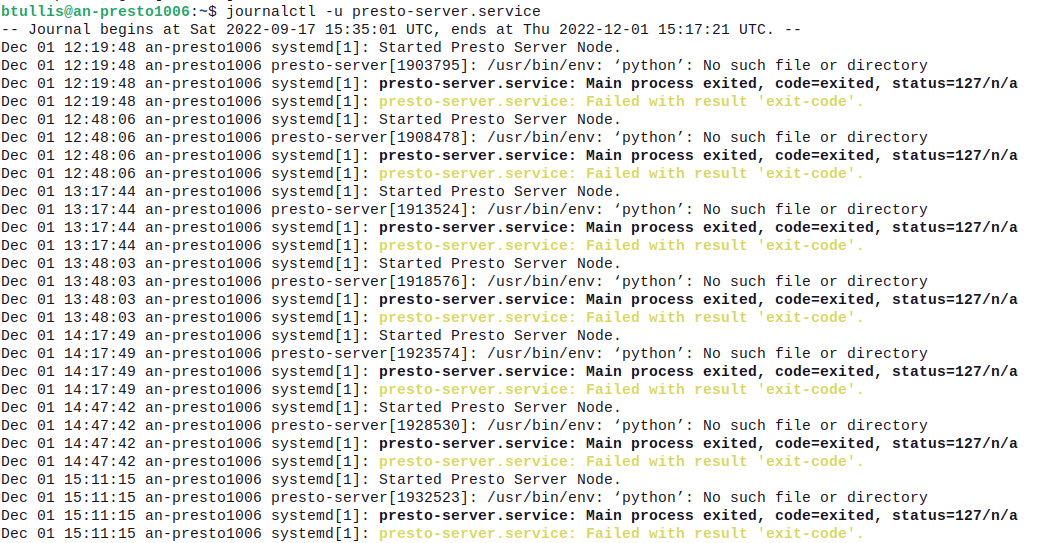
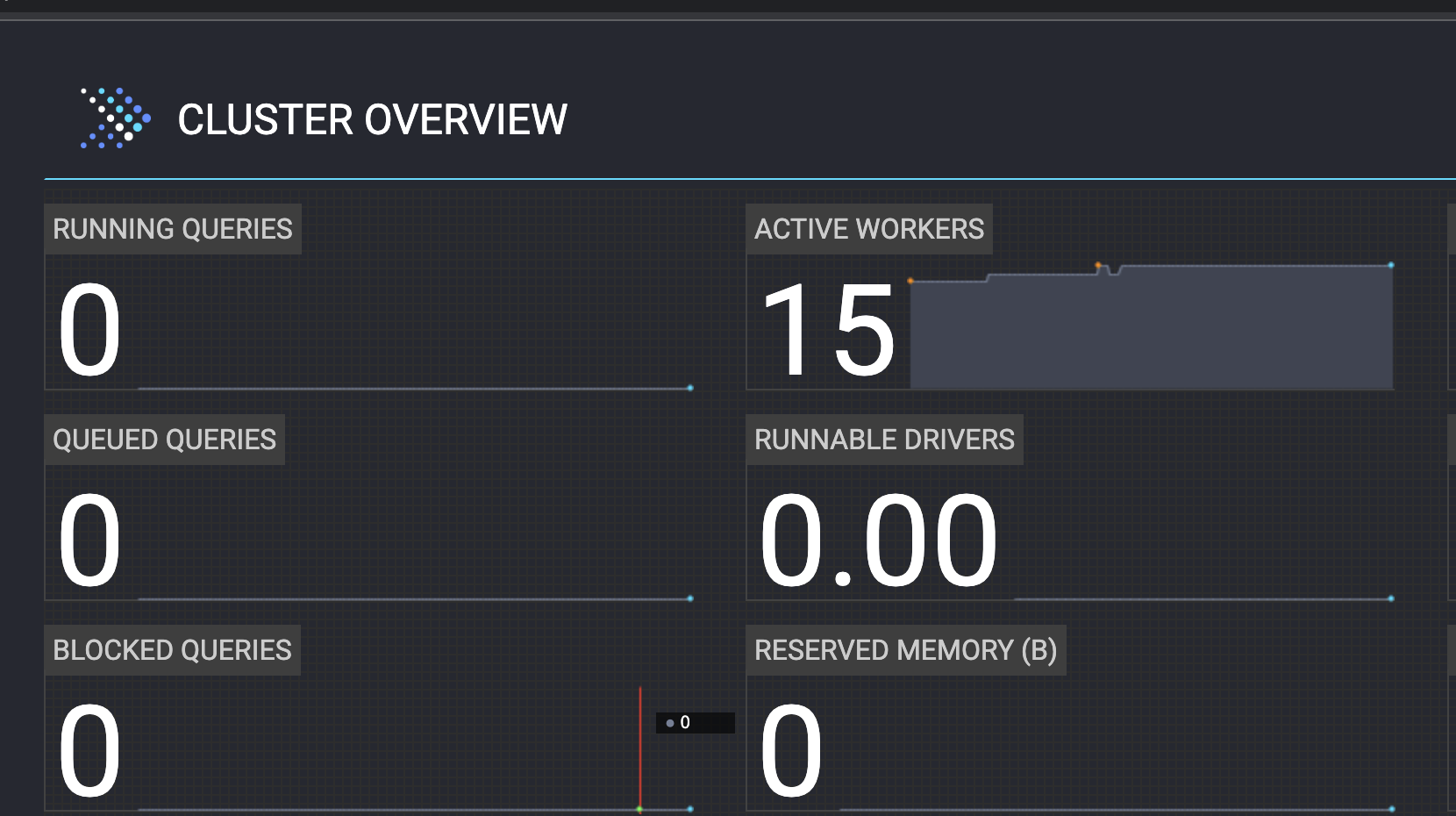
We have 10 presto servers that are ready to be added to the cluster. Their setup/racking task was: T306835
https://github.com/wikimedia/puppet/blob/production/manifests/site.pp#L173-L181
# Analytics Presto nodes.
node /^an-presto100[1-5]\.eqiad\.wmnet$/ {
role(analytics_cluster::presto::server)
}
# New an-presto nodes in eqiad T306835
node /^an-presto10(0[6-9]|1[0-5])\.eqiad\.wmnet/ {
role(insetup::data_engineering)There were a couple of delays caused by:
- a dependency on having Hadoop packages ready for bullseye T310643
- an issue regarding the H750 raid controller working properly
However, these have both been resolved so now adding these servers to the presto cluster should only be a matter of an update to the site.pp file linked above.
This will triple our current presto compute capacity.