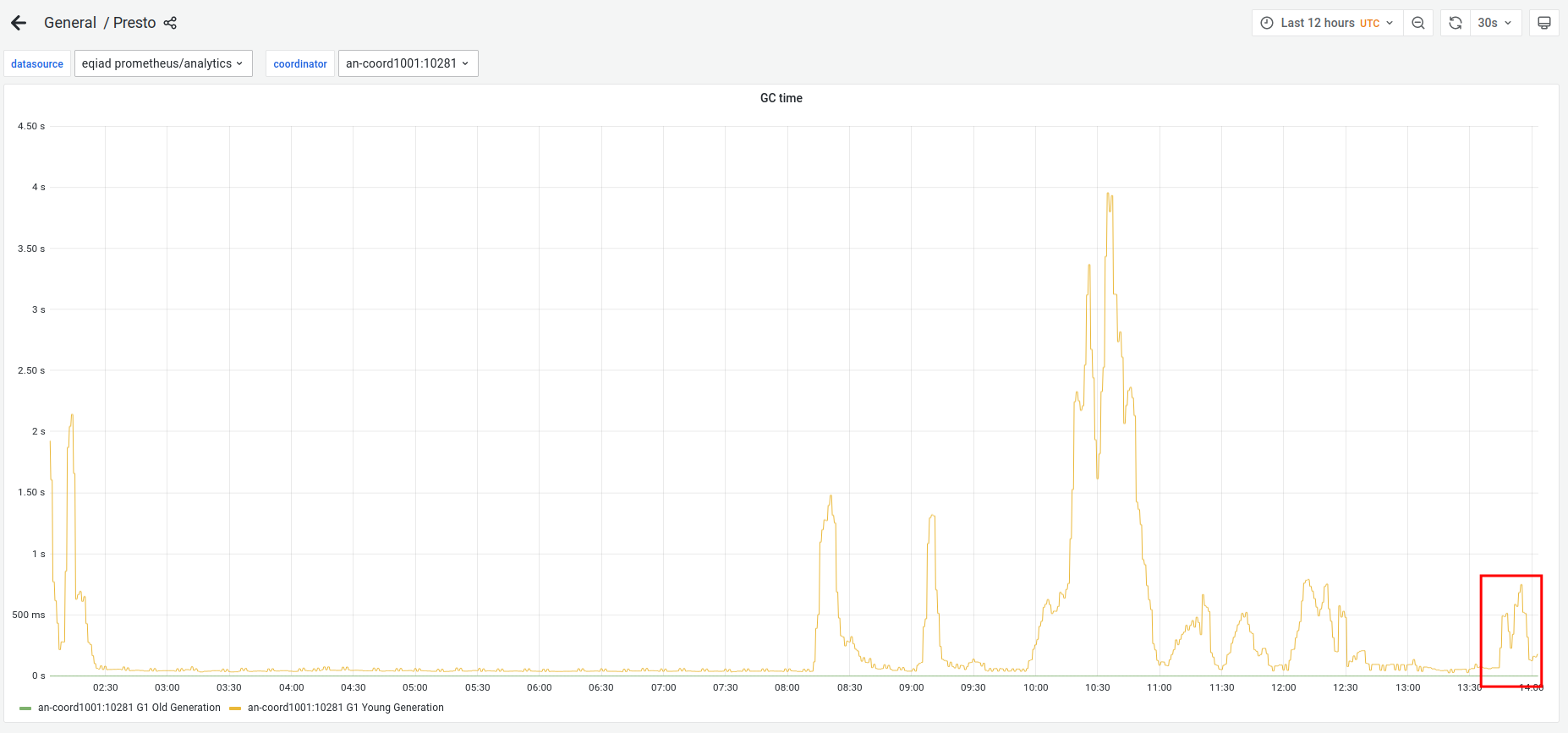
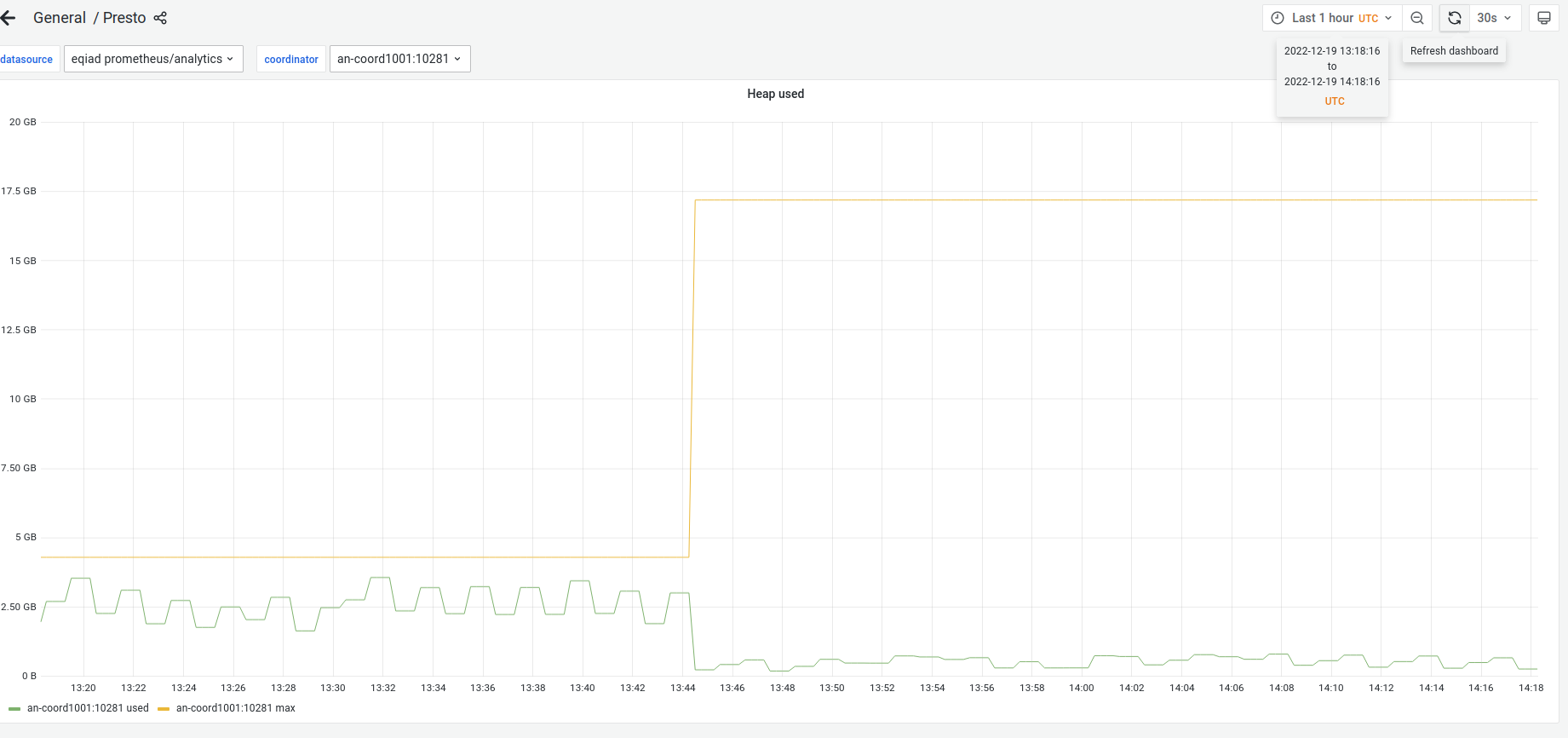
Linked Slack thread: https://wikimedia.slack.com/archives/CSV483812/p1671212018121909
Multiple dashboards are exhibiting errors from Presto data sources.
Sub-Saharan Africa Editors Superset Dashboard:
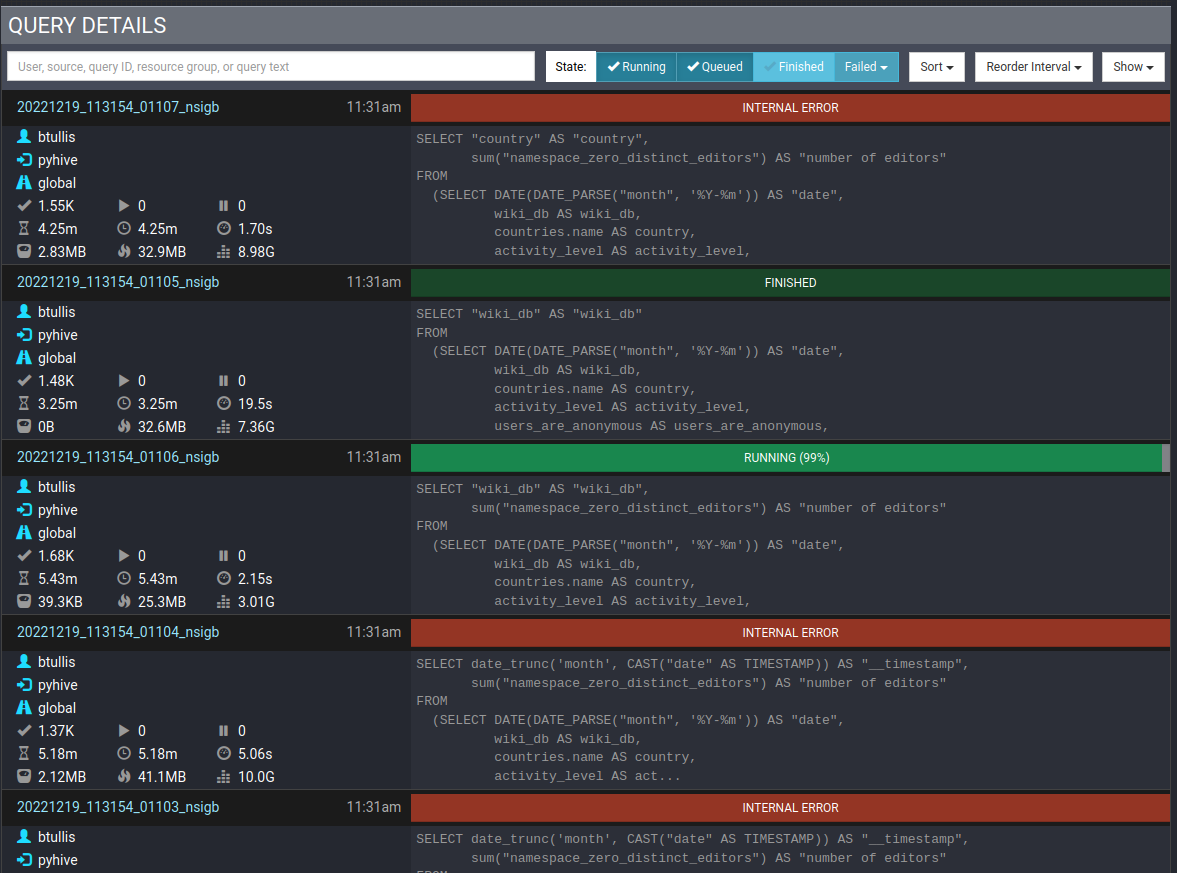
Some charts within two of the "tabs" within the Sub-Saharan Africa Editors Superset Dashboard are not loading as expected.
See "Behavior" below for more details...
Behavior
Chart: SSA Editors by Project and Country
- Navigate to https://superset.wikimedia.org/r/2208
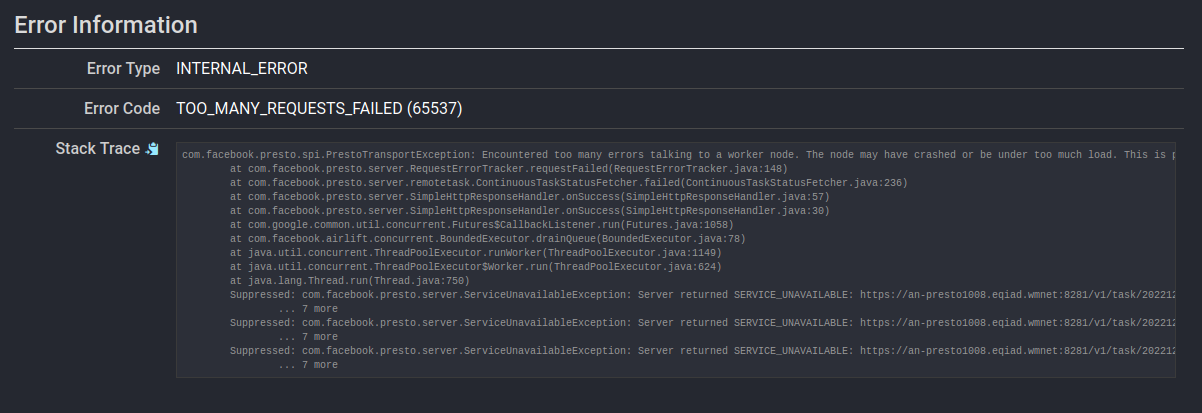
- ❗️ Notice the following errors:
| Chart | Error Message |
|---|---|
| Monthly distinct editors - Sub-Saharan Africa | 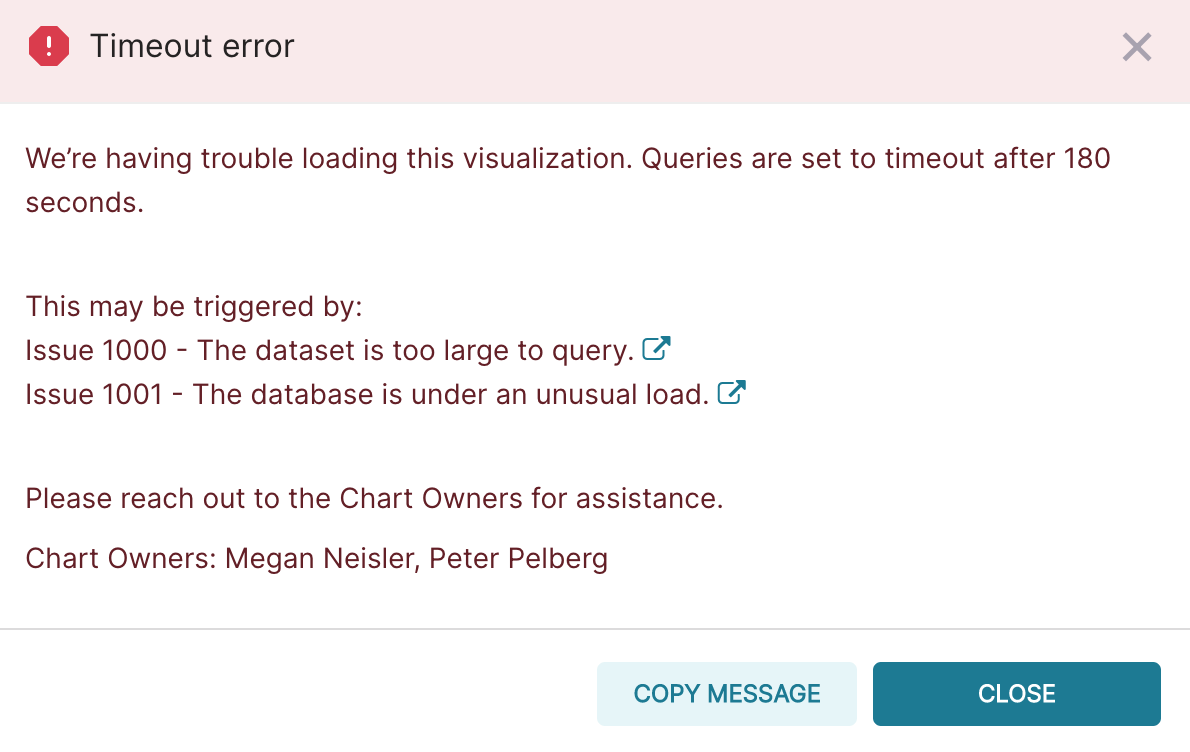 |
| Monthly distinct editors year over year changes - Sub-Saharan Africa | 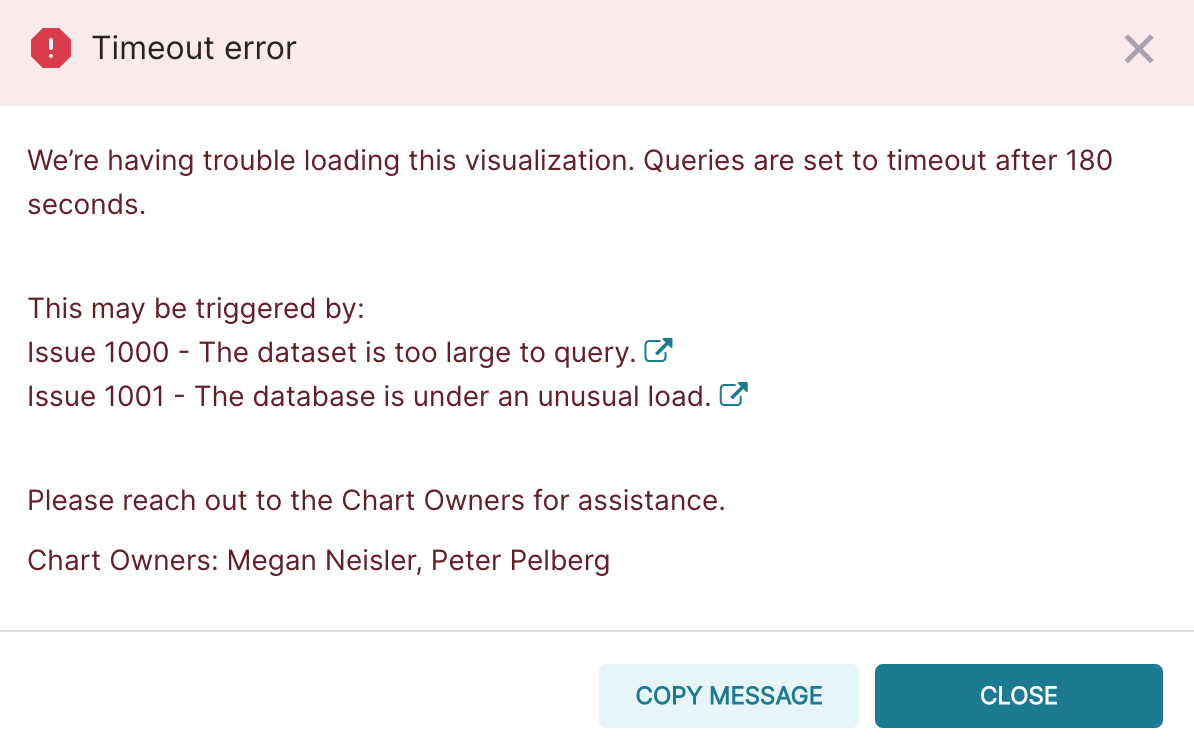 |
| Monthly distinct editors by country - Sub-Saharan Africa | 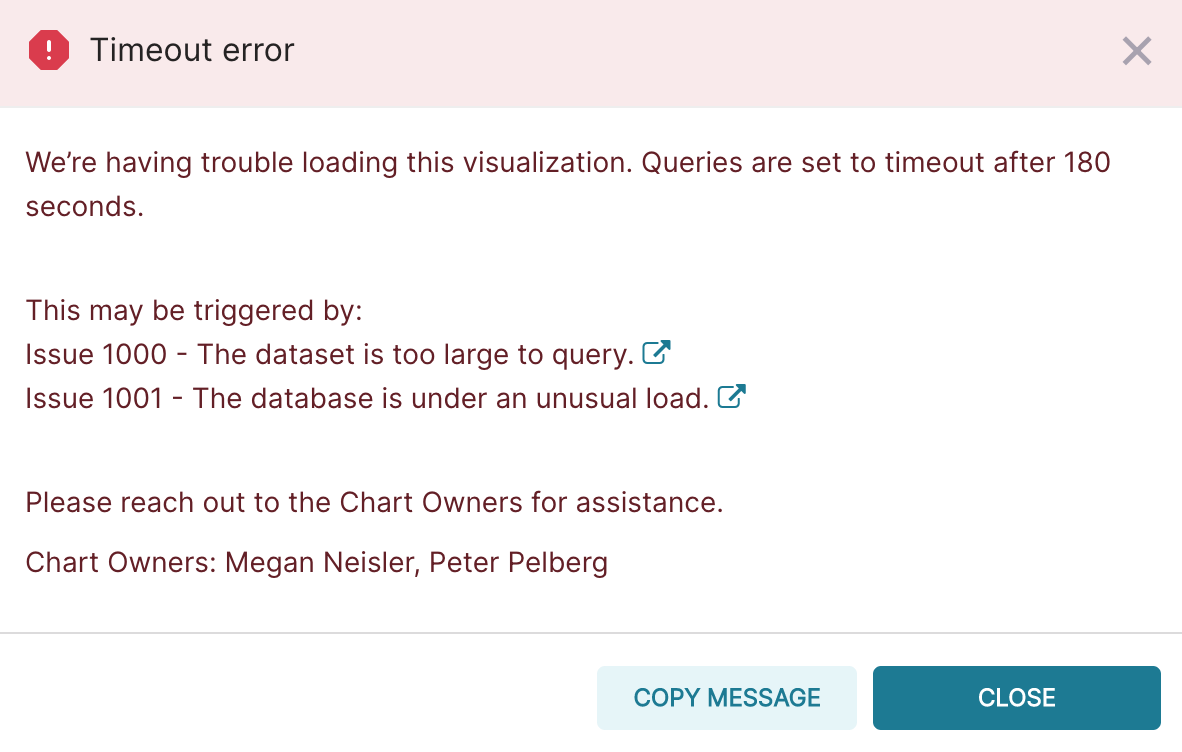 |
Chart: Monthly Distinct Editors by Project and Location
- Navigate to: https://superset.wikimedia.org/r/2210
- ❗️ Notice errors similar to those pictured above
Done
- All charts within the SSA Editors by Project and Country and Monthly Distinct Editors by Project and Location "tabs" of the Sub-Saharan Africa Editors Superset Dashboard load and function as expected
I've had inconsistent timeouts on the editors metrics and readers metrics dashboard as well.
- https://superset.wikimedia.org/superset/dashboard/editors-metrics/
- https://superset.wikimedia.org/superset/dashboard/readers-metrics/
- https://superset.wikimedia.org/superset/dashboard/content-metrics/
Sometimes they time out and sometimes they load after a longer than usual time period.
Individual charts from the content metrics, editors metrics, and readers metrics dashboards are all taking a very long time to load.