Lets convert the performance dashboards that uses Graphite to use Prometheus instead.
Description
Description
Details
Details
- Other Assignee
- Krinkle
| Status | Subtype | Assigned | Task | ||
|---|---|---|---|---|---|
| Open | None | T343020 Converting MediaWiki Metrics to StatsLib | |||
| Open | None | T355837 Add Prometheus support to statsd.js via mw.track() | |||
| Open | None | T180105 Set up a statsv-like endpoint for Prometheus | |||
| Open | None | T228380 Tech debt: sunsetting of Graphite | |||
| Open | colewhite | T205870 Fully migrate producers off statsd | |||
| Open | None | T319329 Expand navigation timing metrics to include user experience metrics and modernise navigation timing | |||
| Open | None | T175087 Create a navtiming processor for Prometheus | |||
| Open | Peter | T321398 Move performance metrics from Graphite to Prometheus | |||
| Resolved | Peter | T325283 Update navtiming dashboards to use Prometheus metrics |
Event Timeline
Comment Actions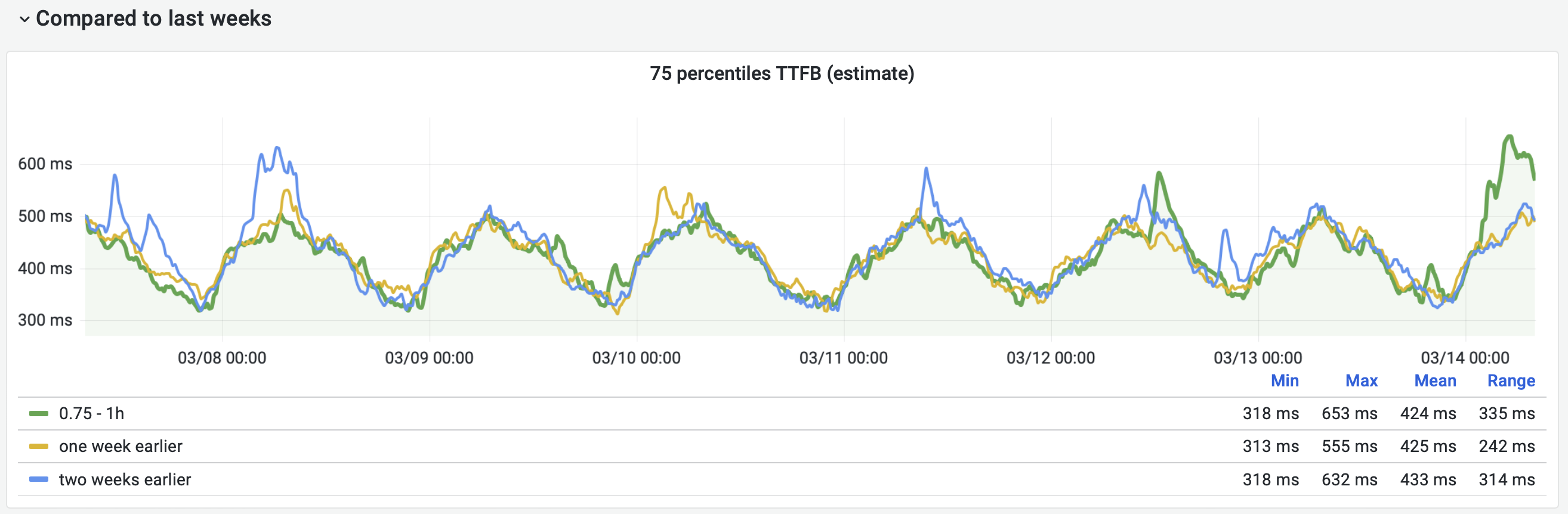


Today we have an issue for users with TTFB and I just verified that we can see the same thing with our Prometheus metrics. Looking at TTFB 75p and compare with one/two weeks back:
And also in the dashboard where we calculate how many users gets a faster experience than X
We can see here that across the board we don't reach the same level as one week ago.