We need to make several decisions about how to install the new ceph cluster.
These decisions include:
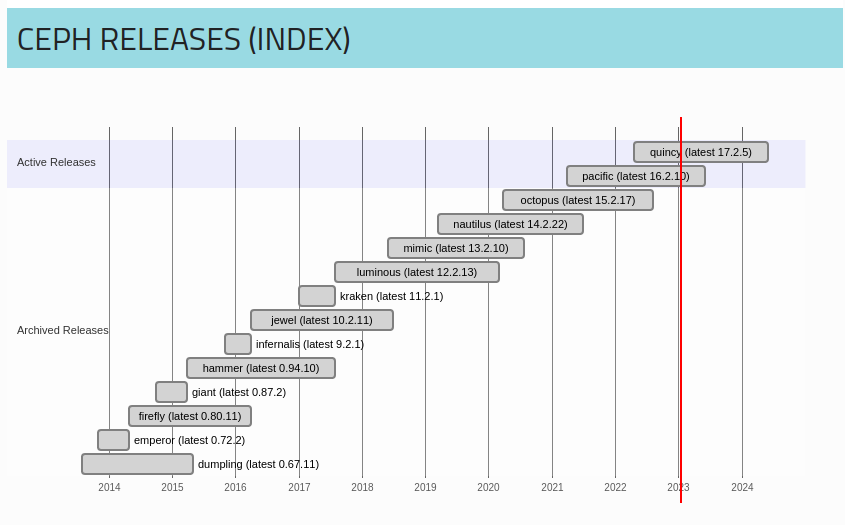
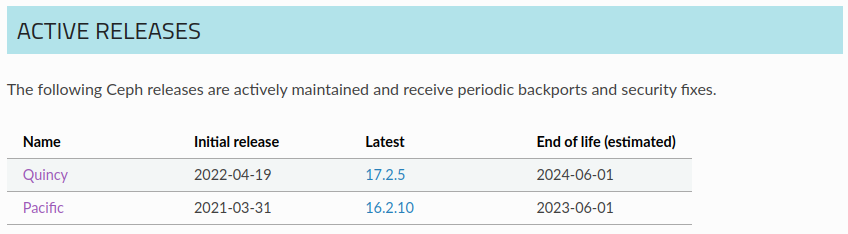
- Which version of ceph should we target? - Quincy - That's 17.2.5 at the time of writing.
- Should we use packages or containers? Packages
- Where exactly do we get our Ceph builds? download.ceph.com
- What installation and bootstrapping method will we use? i.e.
- Existing puppet manifests: modules/ceph
- ~~Import/adapt third-party puppet module: https://opendev.org/openstack/puppet-ceph~~
cephadmceph-deployManul installation
- What will the pool names be? 4 initial pools configred for RBD
- What will the replication settings and/or erasure coding settings be for the pools? Currently evaluating erasure coding for RBD, with replicated pools for metadata
- How many placement groups should be configured for each pool? Initial settings: 1200 PGs for the HDD pools, 800 for the SSD pools. Autotuning enabled
- Should we add buckets for row and rack to the CRUSH maps now? Yes