During today's incident we ended up depooling db1127 via dbctl. Please investigate why the database was malfunctioning and re-pool at your earliest convenience. Thank you!
Description
Description
Related Objects
Related Objects
- Mentioned In
- T330653: Upgrade 10.6.10 hosts to 10.6.12
- Mentioned Here
- T326590: wbsgetsuggestions not returning anything on Wikidata
Event Timeline
Comment Actions
What am I doing wrong? I'm noob to this :(
ladsgroup@cumin1001:~$ sudo ipmitool -I lanplus -H "db1127.mgmt.eqiad.wmnet" -U root -E sel list Unable to read password from environment Password: 1 | 10/06/2021 | 16:51:12 | Event Logging Disabled #0x72 | Log area reset/cleared | Asserted
Comment Actions
Found it, there is no hw crash reported, e.g. memory corruption or something like that.
Also no slow queries triggered this, it seems it just decided not to respond to simple queries: https://logstash.wikimedia.org/goto/fa397c0fe75ce0345136a1831e0d78cf
It might be connection exhaustion. I'll take a look. I have feeling mw is opening waaaaay too many connections. Everything in processlist is always at "sleep"
Comment Actions
Yeah -- the hardware was fine, but mysqld was spinning on 100% CPU, and there were many many many open connections.
@hnowlan pointed out that s7 was slow/throwing lots of errors. I then diagnosed db1127 just from the plot of per-instance open connections against s7 I constructed in grafana explore:
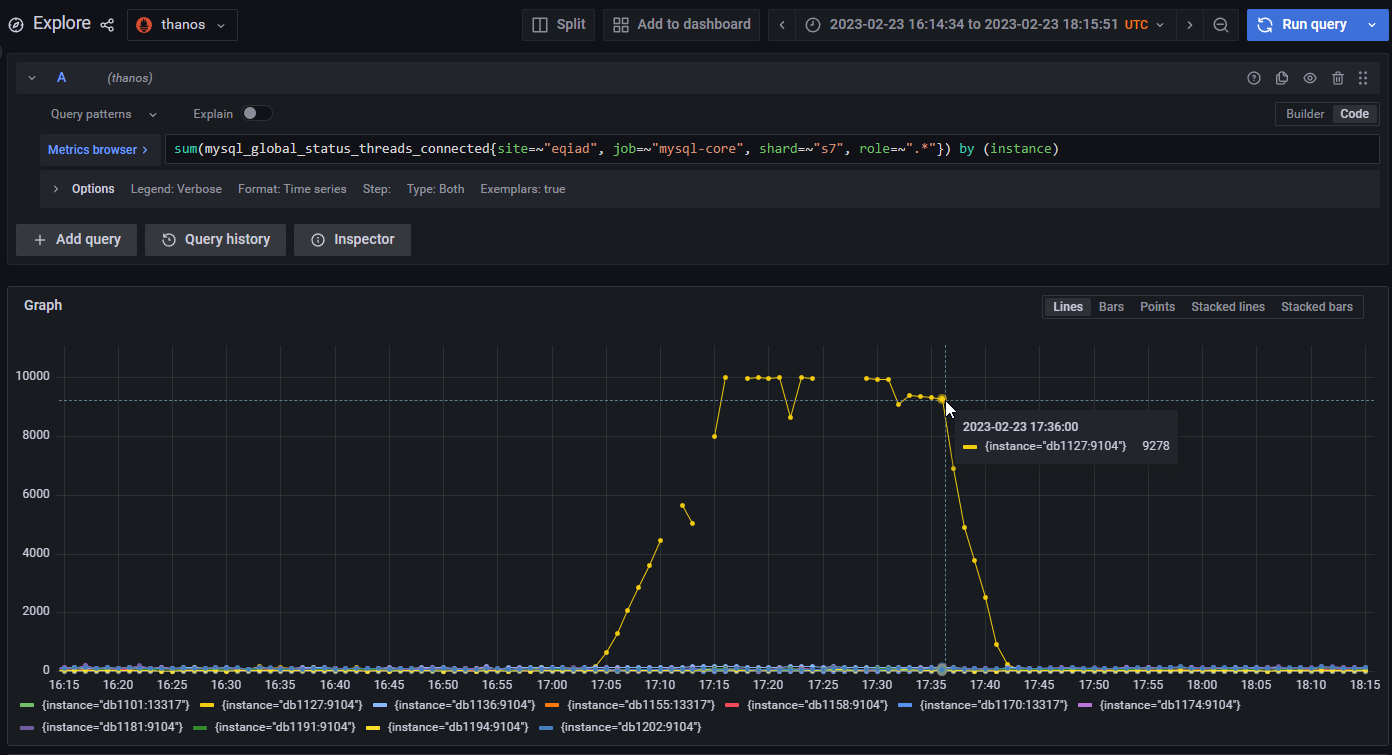
The gaps in the data for db1127 are from when it was too busy to respond even to the simple statistics queries that the mysql prometheus exporter runs.
(BTW I think this per-instance-in-a-shard breakdown is a graph we should have easily available in some MySQL dashboard. I've used it in the past as well.)
Comment Actions
db1127 is the only s7 host that runs mariadb 10.6, coincidence? I don't think so, because it is not the first time it happens: db1143 / https://wikitech.wikimedia.org/wiki/Incidents/2023-01-09_API_errors_-_db1143 / T326590
While it doesn't necessarily mean there is an issue with 10.6 itself (it could be an incompatibility of the query killer, or some change regarding how thread coordination works), and an overload can happen on any server, clearly 10.4 recovers more robustly after an overload (it goes back to a good state quickly after being overloaded) while 10.6 needs manual depooling.
Comment Actions
My guess this is a query killer issue- as this was the same behaviour when it was accidentally not deployed to a host- check how many kills db1202 get (which quickly recovers) compared to the 0 at db1127 (which ends up rejecting connections only after its 10K slots are full:
db1127
{F36867654}
db1202
{F36867653}
Comment Actions
Another confirmation, on the logs, the last time the query killed executed on that host was 2016 (while random execution should happen almost every month):
root@db1127[ops]> select * FROM event_log; +-----------+---------------------+---------------------------+-----------------+ | server_id | stamp | event | content | +-----------+---------------------+---------------------------+-----------------+ | 171970582 | 2016-06-14 09:09:05 | wmf_master_wikiuser_sleep | kill 967549361 | | 171970582 | 2016-06-14 09:09:05 | wmf_master_wikiuser_sleep | kill 967549356 | | 171970582 | 2016-06-14 12:10:35 | wmf_master_wikiuser_sleep | kill 972732779 | | 171970582 | 2016-06-14 13:33:35 | wmf_master_wikiuser_sleep | kill 975134305 | | 171970582 | 2016-06-14 14:17:05 | wmf_master_wikiuser_sleep | kill 976432503 | | 171970582 | 2016-06-14 14:59:35 | wmf_master_wikiuser_sleep | kill 977727356 | | 171970582 | 2016-06-14 15:05:35 | wmf_master_wikiuser_sleep | kill 977912572 | | 171970582 | 2016-06-14 15:15:35 | wmf_master_wikiuser_sleep | kill 978226044 | | 171970582 | 2016-06-14 15:57:35 | wmf_master_wikiuser_sleep | kill 979486330 | | 171970582 | 2016-06-14 16:10:35 | wmf_master_wikiuser_sleep | kill 979882663 | | 171970582 | 2016-06-14 19:33:05 | wmf_master_wikiuser_sleep | kill 986105435 | | 171970582 | 2016-06-15 05:04:05 | wmf_master_wikiuser_sleep | kill 1002520987 | | 171970582 | 2016-06-15 07:04:35 | wmf_master_wikiuser_sleep | kill 1005745735 | +-----------+---------------------+---------------------------+-----------------+ 13 rows in set (0.000 sec)
Compared to db1202, which just fired a few minutes ago:
root@db1202[ops]> select * FROM event_log ORDER BY stamp DESC; +-----------+---------------------+---------------------------+-----------------+ | server_id | stamp | event | content | +-----------+---------------------+---------------------------+-----------------+ | 172001293 | 2023-02-24 08:41:35 | wmf_slave_wikiuser_sleep | kill 1858195552 | | 172001293 | 2023-02-24 08:39:35 | wmf_slave_wikiuser_sleep | kill 1858076576 | | 172001293 | 2023-02-24 08:34:35 | wmf_slave_wikiuser_sleep | kill 1857681818 |
Comment Actions
I have taken a look at db1132 (s1 - 10.6.12) and the query killers does work there.
What I have done for now is dropped + created all the query killers on db1127 and I am going to repool this host during working hours and see if there are kills happening
Comment Actions
Some tests with the query killer (wmf_slave_wikiuser_slow):
Using wikiuser2023 and select sleep (900).
db1202 (10.4 - s7): killed
db1132 (10.6.12 - s1): killed
db1106 (11.0 - s1): killed
db1127 (10.6.10 - s7): NOT KILLED
db1182 (10.6.10 - s2): NOT KILLED
After upgrading db1127 to 10.6.12 the query gets killed.
Maybe a specific 10.6 bug?
I will confirm this by upgrading db1182 to 10.6.12
Comment Actions
db1182 has been upgraded to 10.6.12 and the query was killed right away when it had to:
| 171978822 | 2023-02-27 12:20:33 | wmf_slave_wikiuser_slow (>60) | kill 17; select sleep(900) |
So this looks like a 10.6 bug which is fixed on 10.6.12 for some reason. I am going to create a task to upgrade our 10.6.10 hosts to 10.6.12, it shouldn't take long as we don't have that many
Comment Actions
Going to start repooling this host now that it looks like it is fixed. I am going to monitor it though before closing this.
Comment Actions
db1127 seems to be working again so I am closing this as fixed:
| 171966561 | 2023-02-27 14:15:33 | wmf_slave_wikiuser_slow (>60) | kill 464833; SELECT /* GrowthExperiments\UserImpact\ComputedUserImpactLookup::getEditData */ ct_id,page_namespa | | 171966561 | 2023-02-27 14:15:33 | wmf_slave_wikiuser_slow (>60) | kill 464833; SELECT /* GrowthExperiments\UserImpact\ComputedUserImpactLookup::getEditData */ ct_id,page_namespa | +-----------+---------------------+-------------------------------+-------------------------------------------------------------------------------------------------------------------+