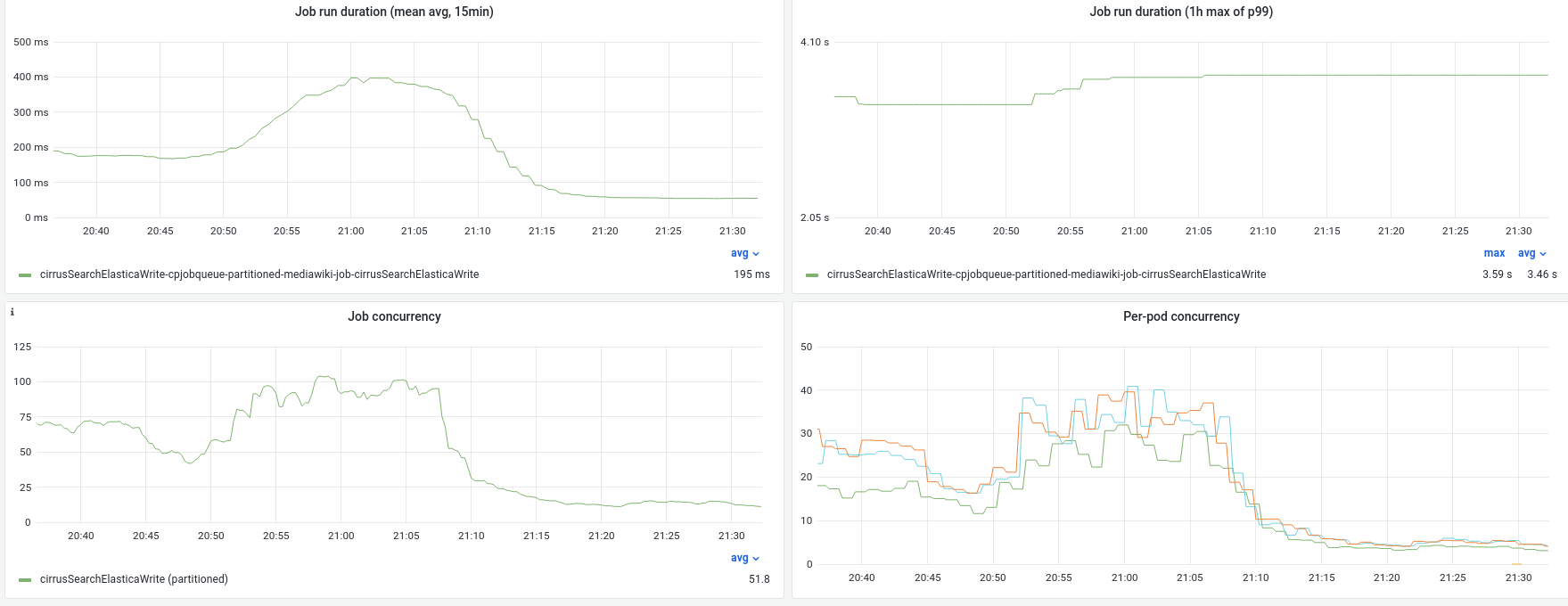
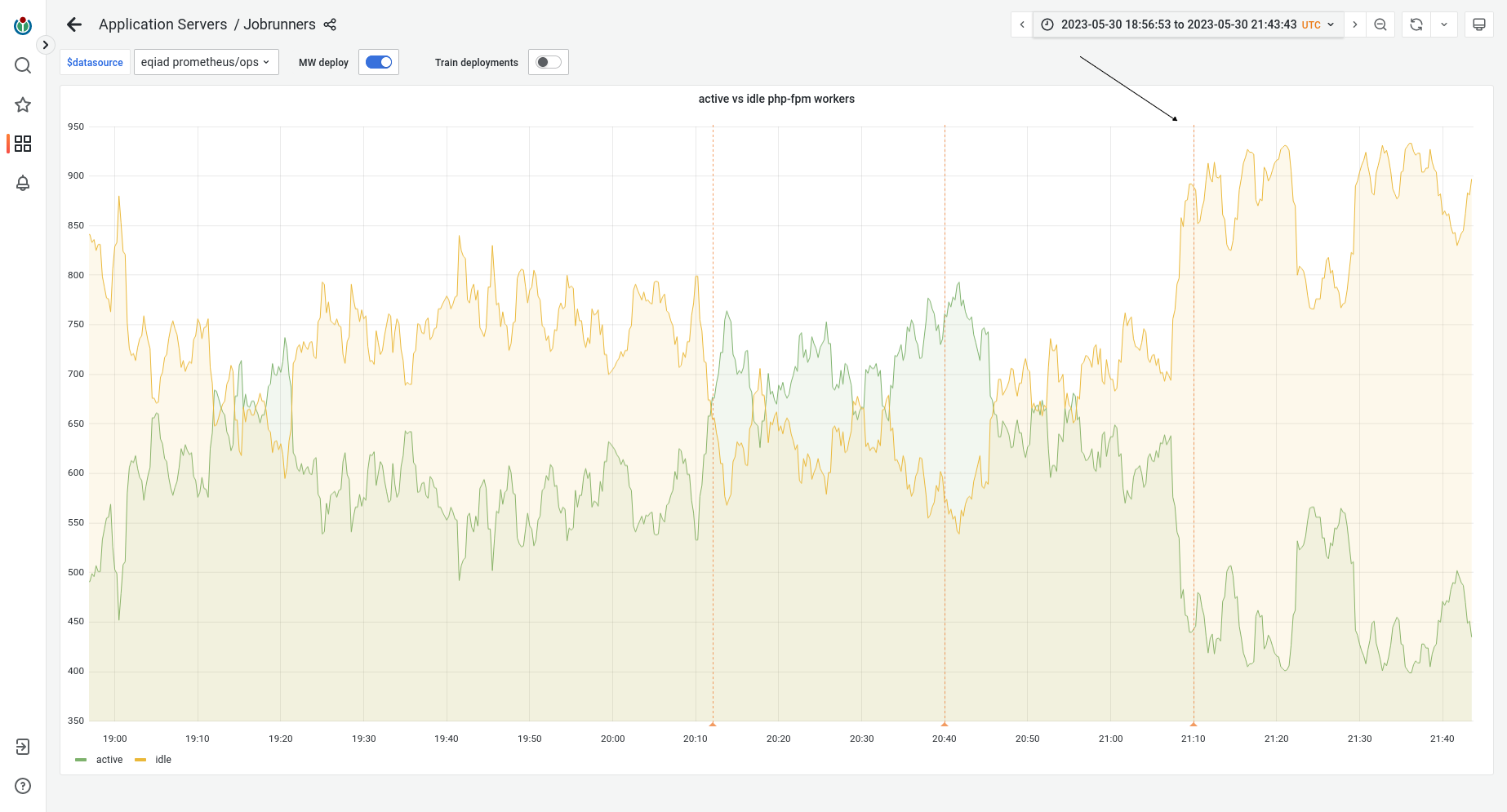
Looking at the flame graphs of a jobrunner it appears that CirrusSearch jobs are taking most of the jobrunner resources.
Few ideas to improve the situation:
- verify that ContentHandler::getParserOutputForIndexing() is not asking to render the HTML output on wikidata
- generate-html is set to false when rendering the output.
- disable the saneitizer for one week and assess the impact
- if the impact is big consider lowering the number of parses by making a dedicated profile for wikis like commons and increase reindex_after_loops from 8 to e.g. 16.
- verify that running the jobs for both eqiad & codfw re-use the parser output (no double parse)
eqiad and codfw writes are done in the same job and they re-use the same documents- the above statement is wrong, the parser output is actually accessed twice but I believe that \MediaWiki\Page\ParserOutputAccess::$localCache is being used to avoid a double parse
- Consider using memcache (~6hours ttl) to hold the indexed content to be re-used by subsequent ElasticaWrite jobs running for cloudelastic
- done in https://gerrit.wikimedia.org/r/c/mediawiki/extensions/CirrusSearch/+/920785
- big impact see T336698#8890551 and T336698#8891221
AC:
- reduce by X% the impact of CirrusSearch jobs on jobrunners