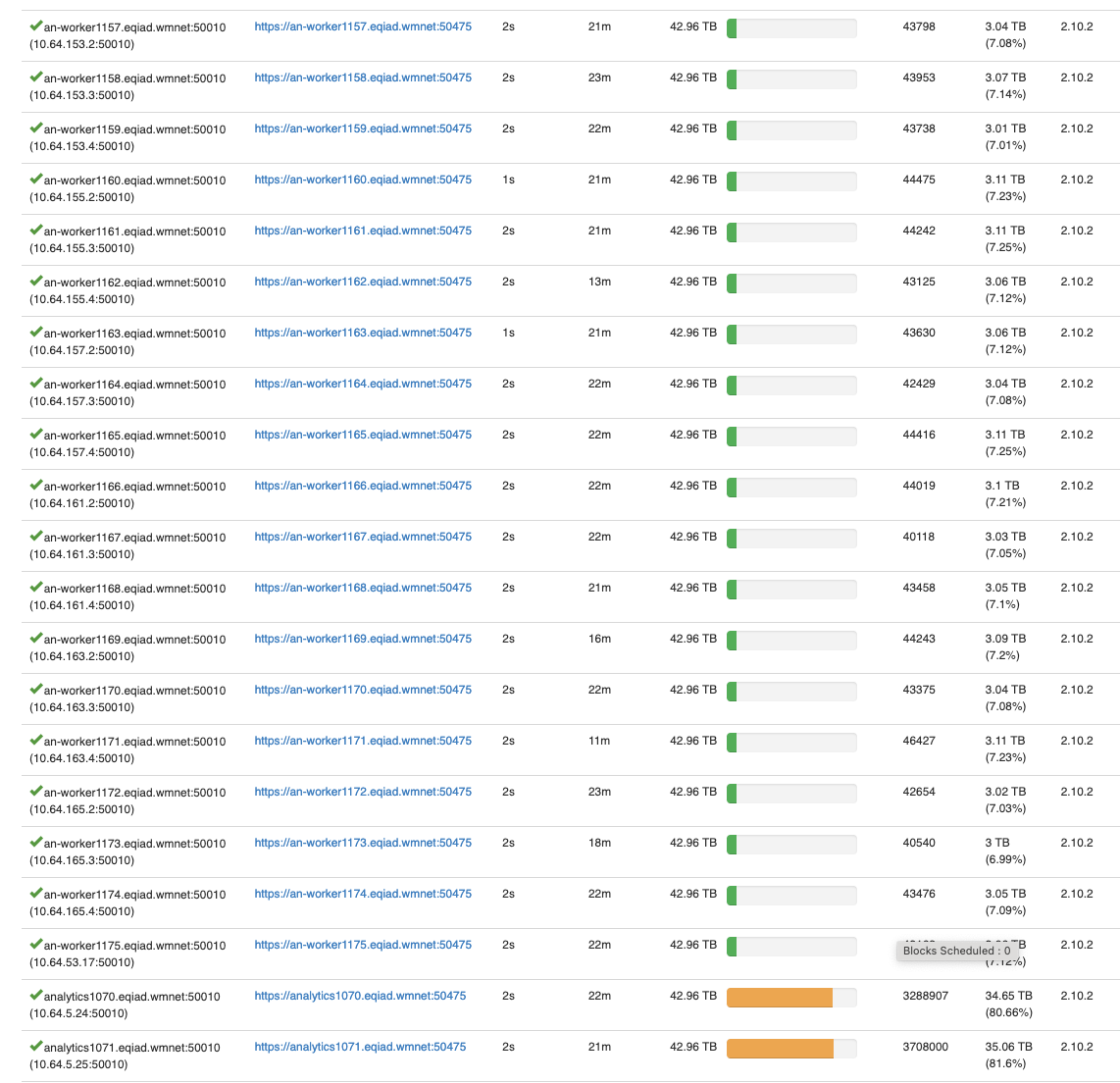
We have 18 new Hadoop workers to bring into service. These were racked in T349936 Q2:rack/setup/install an-worker11[57-75]
For these we are going to:
- Assign the servers the right partman recipe analytics-flex.cfg (This was done during initial setup)
- Install Debian Bullseye on the hosts.
- Create the server's dummy keytabs.
- Create the server's kerberos keytabs.
- Run the hadoop-init-worker.py cookbook to setup the remaining partitions
- Setup journalnode on each
- Add the hosts to net_topology with the right rack assignment
- Add the hosts to role(analytics_cluster::hadoop::worker)