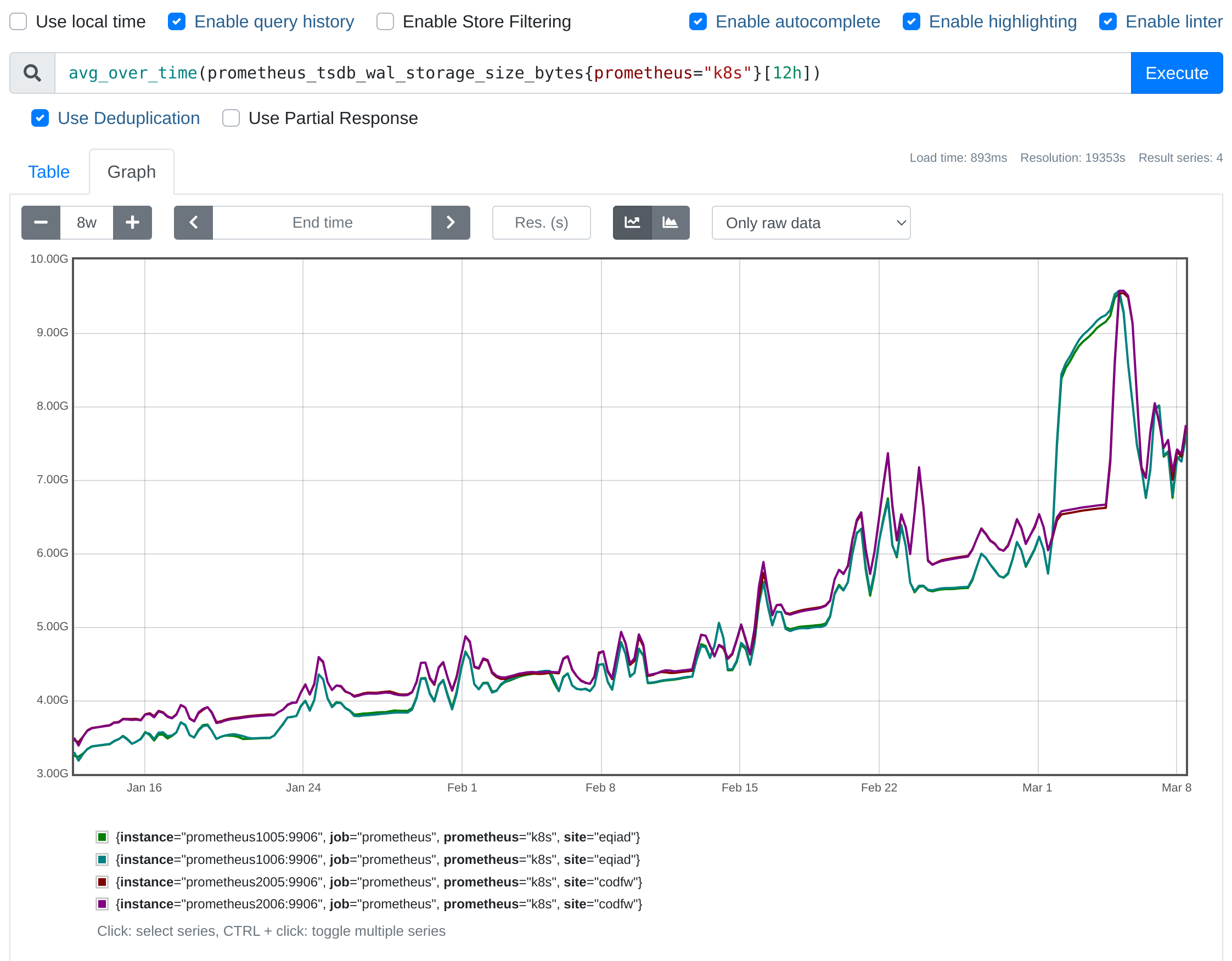
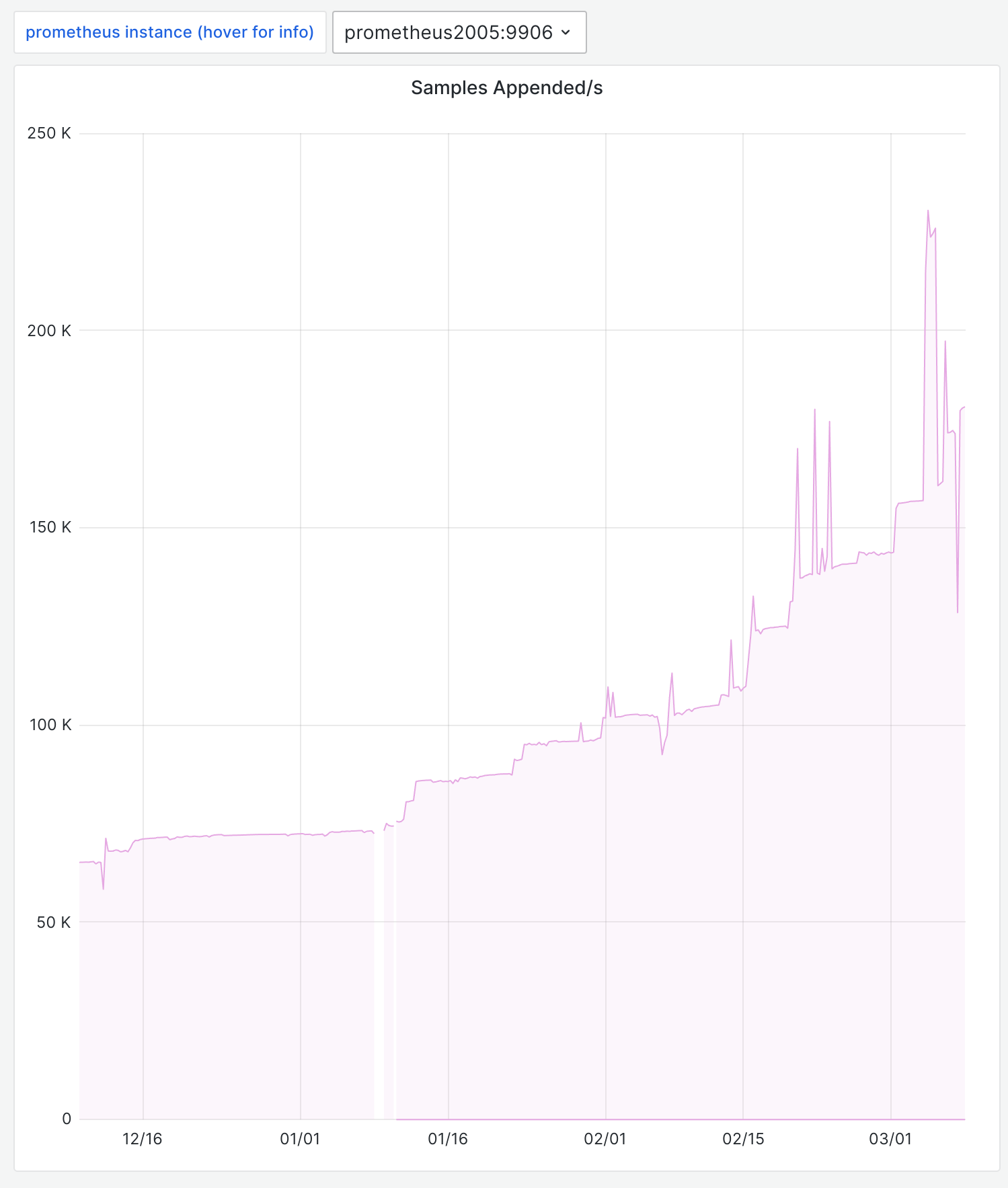
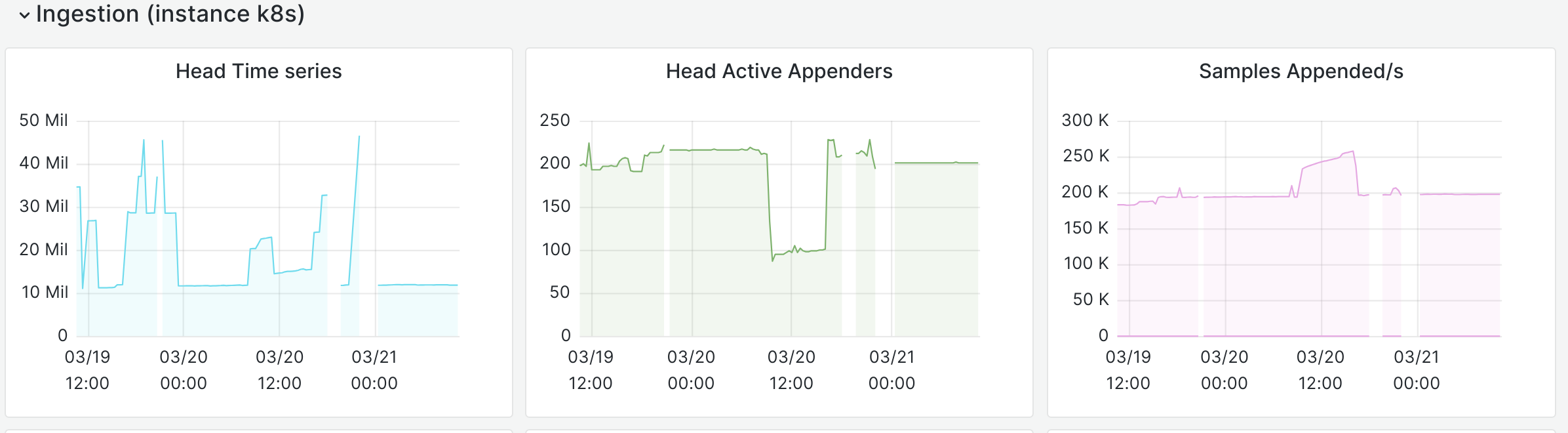
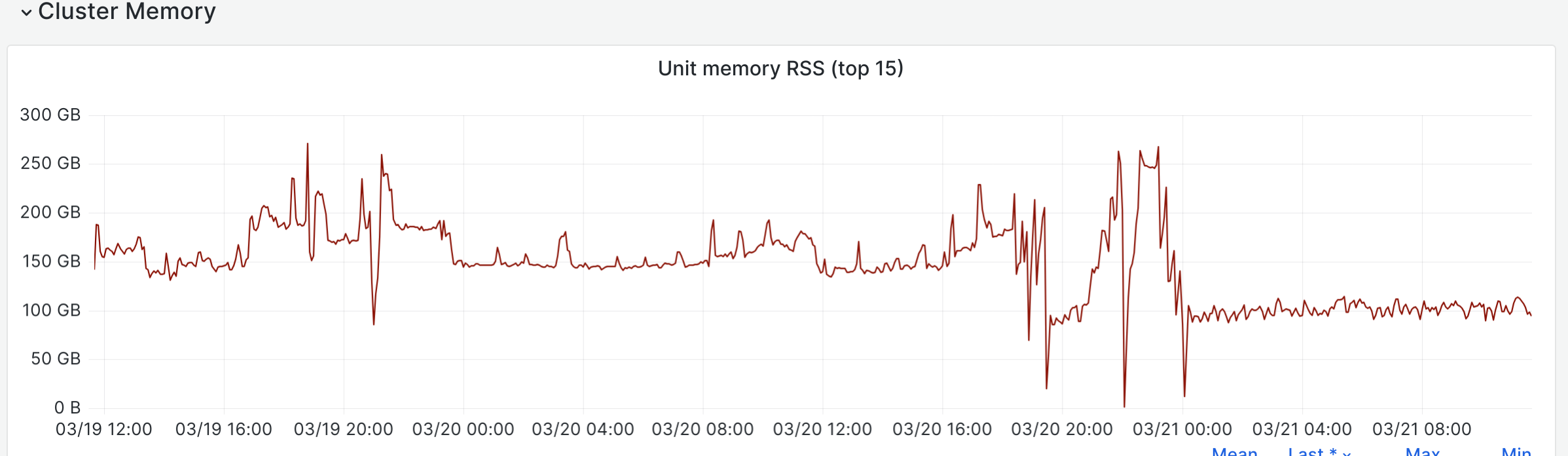
Prometheus consumes a ton of memory replaying the wal, then later gets reaped by the oom-killer. As a mitigation, I backed up the wal to 2024-01-05_wal and restarted prometheus@k8s. It's unclear at the moment whether prometheus@k8s is the cause or the victim.
Jan 5 00:44:19 prometheus1006 kernel: [11682403.939219] oom-kill:constraint=CONSTRAINT_NONE,nodemask=(null),cpuset=/,mems_allowed=0-1,global_oom,task_memcg=/system.slice/system-prometheus.slice/prometheus@k8s.service,task=prometheus,pid=3833619,uid=110 Jan 5 00:44:19 prometheus1006 kernel: [11682403.939321] Out of memory: Killed process 3833619 (prometheus) total-vm:854719612kB, anon-rss:62292952kB, file-rss:3912kB, shmem-rss:0kB, UID:110 pgtables:136472kB oom_score_adj:0 Jan 5 00:44:22 prometheus1006 kernel: [11682407.168165] oom_reaper: reaped process 3833619 (prometheus), now anon-rss:0kB, file-rss:0kB, shmem-rss:0kB Jan 5 00:44:22 prometheus1006 systemd[1]: prometheus@k8s.service: Main process exited, code=killed, status=9/KILL Jan 5 00:44:22 prometheus1006 systemd[1]: prometheus@k8s.service: Failed with result 'signal'. Jan 5 00:44:22 prometheus1006 systemd[1]: prometheus@k8s.service: Consumed 1h 2min 15.057s CPU time. Jan 5 00:44:24 prometheus1006 systemd[1]: prometheus@k8s.service: Scheduled restart job, restart counter is at 13. Jan 5 00:44:24 prometheus1006 systemd[1]: Stopped Prometheus server (instance k8s). Jan 5 00:44:24 prometheus1006 systemd[1]: prometheus@k8s.service: Consumed 1h 2min 15.057s CPU time.
Thanos may still have a copy of the data? eqiad prometheus/k8s definitely has a gap since the OOMs started.
remediation
Nuking the WAL is enough to let prometheus start back up (with loss of data that was in the WAL):
# might take up to 1-2 minutes systemctl stop prometheus@k8s mv /srv/prometheus/k8s/metrics/wal /srv/prometheus/k8s/metrics/wal-$(date -Im) systemctl start prometheus@k8s