
This project brought two major changes to our infrastructure. Firstly, servers that used to be fronted by LVS for load balancing are now peering directly with our routers. Secondly, we have started using IP anycast for a highly critical service: recursive DNS.
Load balancing
At the infrastructure level, load balancing means sending clients requests to more than one backend server. There are many different ways to achieve this each one with their advantages and drawbacks.
Any users accessing Wikimedia’s websites will go through those following two layers.
GeoDNS
- A client asks our DNS for the IP of a given service (eg. www.wikipedia.org)
- Our authoritative DNS server looks up the client IP using an IP to geolocation database (in our case MaxMind), which in turn gives a rough idea of this IP’s location (country or state)
- Finally, our DNS server checks our manually curated list of “location-POP mapping”, and replies with the IP of the nearest POP
As a result, depending on their estimated location, users are balanced to different caching POPs).
See, for example, in San Francisco and Singapore:
$ host www.wikipedia.org www.wikipedia.org is an alias for dyna.wikimedia.org. dyna.wikimedia.org has address 198.35.26.96 dyna.wikimedia.org has IPv6 address 2620:0:863:ed1a::1
$ host www.wikipedia.org www.wikipedia.org is an alias for dyna.wikimedia.org. dyna.wikimedia.org has address 103.102.166.224 dyna.wikimedia.org has IPv6 address 2001:df2:e500:ed1a::1
LVS
To reach those IPs (eg. 2620:0:863:ed1a::1 or 2001:df2:e500:ed1a::1), users’ requests will cross the Internet and eventually hit our routers and our Linux load-balancer: the Linux Virtual Server.
LVS’ peers with our routers using BGP to advertise (“claim”) those specific IPs and forwards inbound traffic towards them to a pool of backend servers (called “origin servers”). Decisions about which server to forward the traffic to are made based on:
- Their administrative state: pooled/de-pooled, which is set in an etcd-backed store. See eqiad/text-https for example
- The health of the service, using regular health checks (active probing)
- The source and destination IP and port (hashing)
The first two are handled by PyBal, our homemade LVS manager and “battle-tested” tool.
The last one is to ensure that packets from a user’s session are always forwarded to the same backend server. If they were randomly balanced, backend servers would not know what the packets are about, as they don’t share states between each other (very costly). There are thoughts about replacing the scheduler.
Bypassing the LVS
Our routers (in our case Juniper MXs but it’s similar through all the major vendors) support multiple types of load-balancing. The one we’re interested in now is called BGP multipath. To achieve this, every end server maintains a BGP session with the routers and advertises the same load-balanced IP.
BGP default behavior is to only pick one path (one backend server in our case) and keep the other ones as backups. Flipping the multipath knob, the router will start doing what’s called ECMP (Equal Cost Multiple Paths) and similar to LVS, it will decide which server to forward the packets to based on:
- The servers advertising the IPs (passive)
- The source and destination IP and port (configurable)
This has the obvious advantage of being a more lightweight solution. Getting rid of a middle layer, which means less hardware, less software, and an easier configuration.
On the other hand, there are some limitations:
- Service health-check probing is replaced by self-monitoring, a daemon on the end server stops advertising the IP if it detects an issue at the service level. This allows some failure scenarios where the end service is locally healthy but can’t be reached remotely (eg. firewalling issues)
- Less control on the hashing algorithm, since it is controlled by a proprietary software (the router’s OS). Not a big deal until we hit bugs
- No etcd integration (yet?), thus depooling a backend server is only possible by disabling the BGP session or stopping the service being self-monitored
The goal here is not to get rid of those LVS, but instead find a better load balancing solution for those "small" services, on which LVS may depend on. For example DNS.
Let’s checkout anycast before looking at the end result.
What is anycast?
Anycast is one of the few ways the IP stack can route traffic from a source to a destination. In a good old unicast setup, the destination IP is unique on the network. But, what happens if there are several of them? You can imagine it as a larger scale version of BGP multipath (mentioned previously).
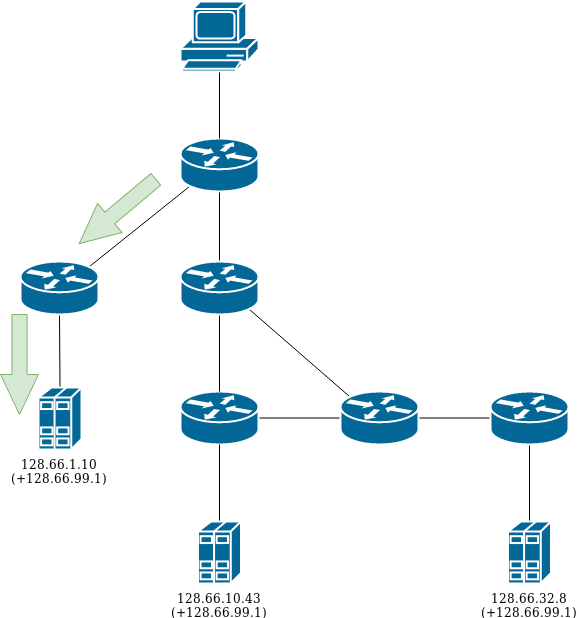
When a router receives a packet destined for an IP for which multiple paths exist, it will go through a list of criteria (known as path selection) in order to decide which next hop is the best. For BGP, the main criteria is the “distance” measured in AS PATH length.
The way our infrastructure is designed, each service is assigned an AS number (eg. 64605 for anycast, 64600 for LVS), the same goes for each site (eg. 65001 for Ashburn, 65004 for San Francisco).
For example, traffic going from a host to a service hosted in the same site will have a distance (AS PATH length) of 1 (SITE->SERVICE). The distance for the same host to the same service in another site would be 2 (SITE->SITE->SERVICE).
In the example below (edited for readability), cr3-ulsfo has 3 options to reach 10.3.0.1—the first one having the shortest distance is the preferred route.
cr3-ulsfo> show route 10.3.0.1 terse A Destination Next hop AS path * 10.3.0.1/32 198.35.26.7 64605 I 10.3.0.1/32 198.35.26.197 (65002) 64605 I 10.3.0.1/32 198.35.26.197 (65001 65002) 64605 I
Reasons for using anycast
If for some reason the prefered path becomes unavailable, it will transparently fail over to the next one within milliseconds, making the service significantly more resilient. One must obviously keep those traffic pattern changes in mind while designing the service. In our infrastructure, edge (caching) sites will fallback to core sites if the local service is down, but not the other way around.
To give a more concrete example, using an internal service:
If an anycast endpoint is in Ashburn, all clients in Ashburn will prefer it. If that endpoint goes down, and we have a similar endpoint in Dallas, Ashburn clients will automatically "reroute" to Dallas.
It is easy to see the reliability improvements of the above solution compared to more traditional ones, like, for instance, when servers had two nameserver entries in their resolv.conf file. Unfortunately, resolv.conf is configured to try the nameservers sequentially and has a default timeout of 5 seconds, with a minimum possible value of one second. This means that an outage can lead to servers being unable to resolve DNS for a number of seconds before they failover to the second nameserver. Some services are more sensitive to these failures than others and we have observed real issues with such outages. More details on task T162818.
In addition to resilience, Anycast does a good job to keep latency at a minimum, as a shorter AS PATH usually means lower latency. While this is true within a controlled network, the Internet is another can of worms, but it is still the best option for services which can't do GeoIP (eg. authoritative DNS servers).
Internally, we don't have to maintain a mapping of which server is the best one for a given POP. In our case, all hosts use 10.3.0.1 as DNS. Set it, and forget it.
Of course it's not all upside, Anycast comes with one major risk, especially for a stateful protocol such as TCP: flapping. External factors (topology changes, incorrect load balancing) can cause packets of a given session to get redirected to a different backend server. As the new server did not take part in the initial TCP handshake, it will have no local state and reject (RST) the connection. Fixing it requires keeping states on the routers or sharing them between backend servers. Both are incredibly costly solutions. Remember, we’re trying to keep that step as lightweight as possible. Thankfully, experience and studies have shown that even on the dynamic network that is the Internet, those situations are uncommon.
Another limitation is monitoring, as a source is not able to target a specific destination host (the network decides), monitoring needs to run from at least as many vantage points as end nodes.
Our implementation
Tracked in: T186550
Documented in: https://wikitech.wikimedia.org/wiki/Anycast#Internal
Firstly, we need a daemon that runs on our Debian servers and talks BGP to our routers. We chose the BIRD Internet Routing Daemon for this, because it is both well tested and supports BFD out of the box.
BFD (Bidirectional Forwarding Detection) is a very fast and lightweight failure detection tool. As BGP's keepalives timers are not designed to be quick (90s by default), we need something to ensure the routers will notice the server going down fast enough, in our case after 3*300ms.
At this point, we could already call it a day. We have the server advertising the Anycast IP via Bird to the router and a failover mechanism if the server fails.
But, what if the server stays healthy while the service itself dies?
To cover that failure scenario we found a useful and lightweight tool on GitHub called anycast_healthchecker.
Every second, the health-checker monitors the health of the anycasted service using a custom script. If any issue is detected, it will instruct Bird to stop advertising the relevant IP.
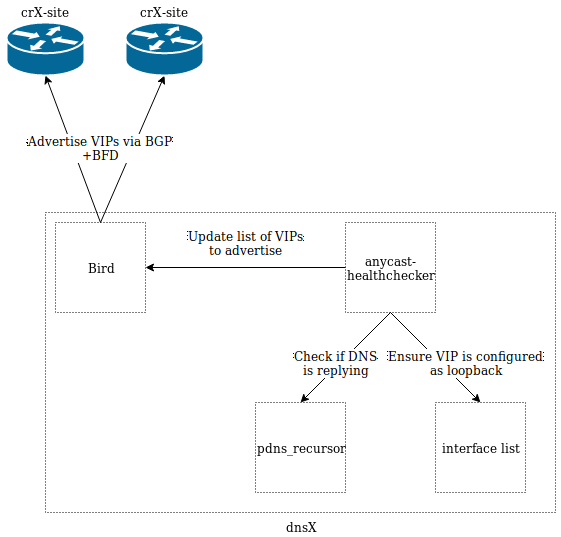
Covering another failure scenario, the Bird process is linked (at the systemd level) to anycast_healthchecker, so that if the latter dies, the former will stop, BFD will detect a failure, and the router will stop advertising the IP as well.
On the monitoring front we have Icinga checking for the Bird and anycast_healthchecker processes, the router’s BGP sessions as well as the Anycasted IP.



As mentioned previously, this check will only fail if all of the possible Anycast endpoints are down (from a monitoring host point of view), this is why this is a paging alert.
All of the above is deployed via Puppet so only a few lines of Puppet/Hiera configuration is needed, see here. If you're curious about the router side, it's over there.
What's next?
This setup has been working flawlessly for a few months now, and is going to grow progressively.
On the "small" improvements side, or wishlist, we want to be able to monitor the Anycast endpoints from various vantage points, or make it v6 ready.
On the larger side, the next big step is to roll Anycast for our authoritative DNS servers (the ones answering for all the *.wikipedia.org hostnames). The outline of the plan can be seen on the tracking task.
Our goal is to do externally what we have been doing internally. Each datacenter will advertise to their transit and peering neighbors the same IPs. The internet will take care of routing users to the optimal site. Add some safety mechanisms (eg. automatic IPs withdrawals), proper monitoring and voila!
Photo by Clint Adair on Unsplash
- Projects
- Subscribers
- dancy