Project page: https://www.mediawiki.org/wiki/Moderator_Tools/Automoderator
Hypothesis
If we enable communities to automatically prevent or revert obvious vandalism, moderators will have more time to spend on other activities. This project will use the Research team's revert prediction model, and we may explore integrating it with AbuseFilter, or creating an automated anti-vandalism revert system. Targets and KRs for this project will be set collaboratively with the community.
Goals
- Reduce moderation backlogs by preventing bad edits from entering patroller queues
- Give moderators confidence that automoderation is reliable and is not producing significant false positives
- Ensure that editors caught in a false positive have clear avenues to flag the error / have their edit reinstated
Proposed solution
Build functionality which enables editors to revert edits which meet a threshold in the revert-prediction model created by the Research team.
Give communities control over the product's configuration, so that they can:
- Locally turn it on or off
- Set the revert threshold
- Audit configuration changes
- Be notified of configuration changes
- Customise further aspects of how the feature operates
Illustrative sketch

Model
T314384: Develop a ML-based service to predict reverts on Wikipedia(s) (Meta, model card).
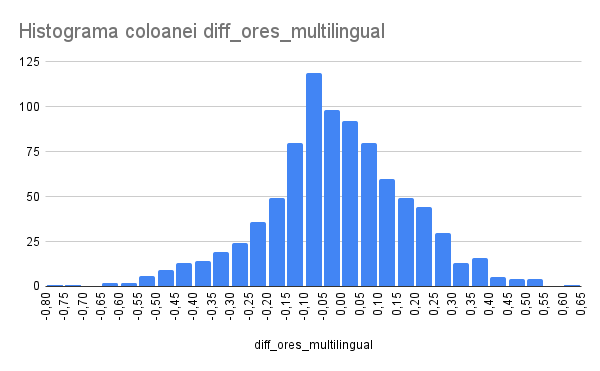
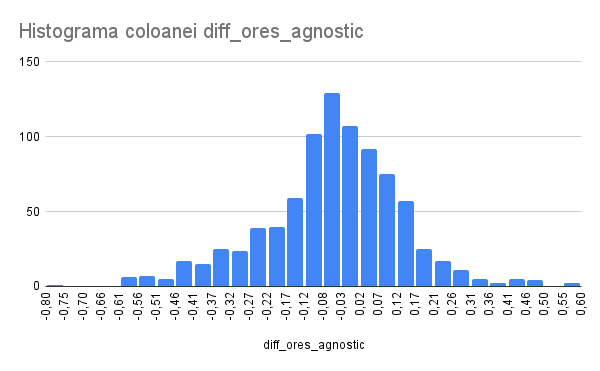
There are two version of the model: Language-agnostic and multilingual. The multilingual model is more accurate, but only available in 48 languages, as documented in the model card.
The model is only currently trained on namespace 0 (article/main space). It has been trained on Wikipedia and Wikidata, but could be trained on other projects.
Existing volunteer-maintained solutions
| Project | Bot |
|---|---|
| en.wiki | ClueBot NG |
| es.wiki | SeroBOT |
| fr.wiki & pt.wiki | Salebot |
| fa.wiki | Dexbot |
| bg.wiki | PSS 9 |
| simple.wiki | ChenzwBot |
| ru.wiki | Рейму Хакурей |
| ro.wiki | PatrocleBot |
Relevant community discussions
- Community Wishlist Survey 2022/Larger suggestions/Automatic vandalism/spam detection and revert in more wikis (meta)
- Community Wishlist Survey 2022/Admins and patrollers/Expose ORES scores in AbuseFilter (meta)
- Re-prohibition of IP editing (fa.wiki)
Key Results
- Automoderator has a baseline accuracy of 90%
- Moderator editing activity increases by 10% in non-patrolling workflows
- Automoderator is enabled on two Wikimedia projects by the end of FY23/24.
- 5% of patrollers engage with Automoderator tools and processes on projects where it is enabled.
- 90% of false positive reports receive a response or action from another editor.
See more details in our measurement plan.
Open questions
- Can we improve the experience of receiving a false positive revert, as compared to the volunteer-maintained bots?
- How can we quantify the impact this product will have? Positive (reducing moderator burdens) and negative (false positives for new users)