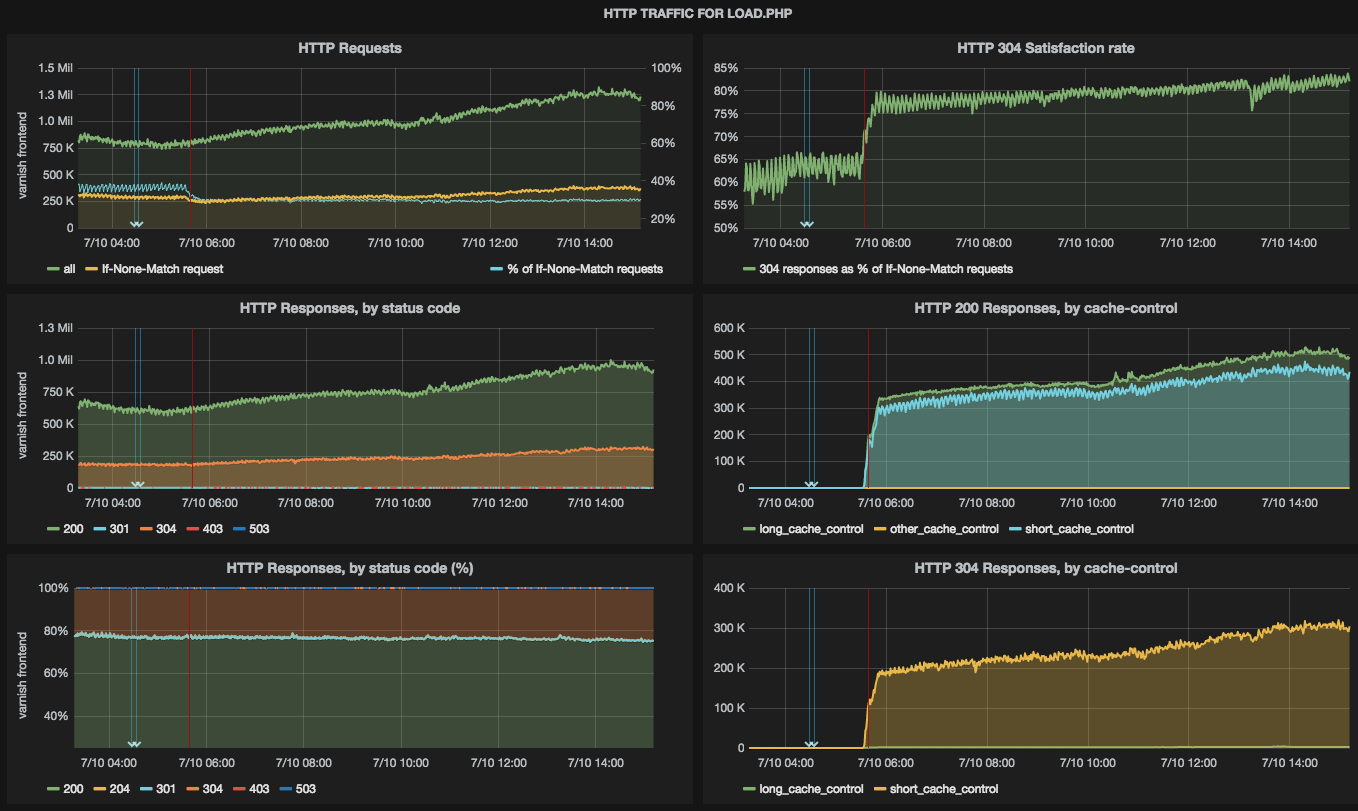
In order to better understand how well ResourceLoader is performing, and to measure the impact of deployments and trends over time, I'd like to request we continuously aggregate metrics for load.php requests.
Specifically, requests and responses from Varnish to /w/load.php on all wiki domains (e.g. en.wikipedia.org/w/load.php?...).
- Total count of load.php requests per minute.
- Broken down by label(s):
- Response http status code (e.g. HTTP 200, 304, or 500).
- Whether request had a If-None-Match header.
- Response byte size of HTTP 200 responses (Content-Length).
Use case is to be able to continuously answer the below questions. (e.g. in Grafana or elsewhere, showing trends and correlation to deployment events.)
- How many (absolute number) requests were there to load.php globally per minute at any given time? (req.all.count)
- How is the average response size per request changing? (resp.content-length)
- What percentage of clients actually had a local cache for the request? (req.if-none-match.count)
- What was the ratio between responses being cache hits and cache misses? (resp.http-200.count, resp.http-304.count)