As per Tilman Bayer:
Hi Kevin and Dan,
thanks again for taking the time last week to explain how to retrieve pageview from Hive! It worked out well and I was able to publish the quarterly report on schedule on July 30. (And BTW I also got my access to Hue sorted out this week with the help of Andrew O.)
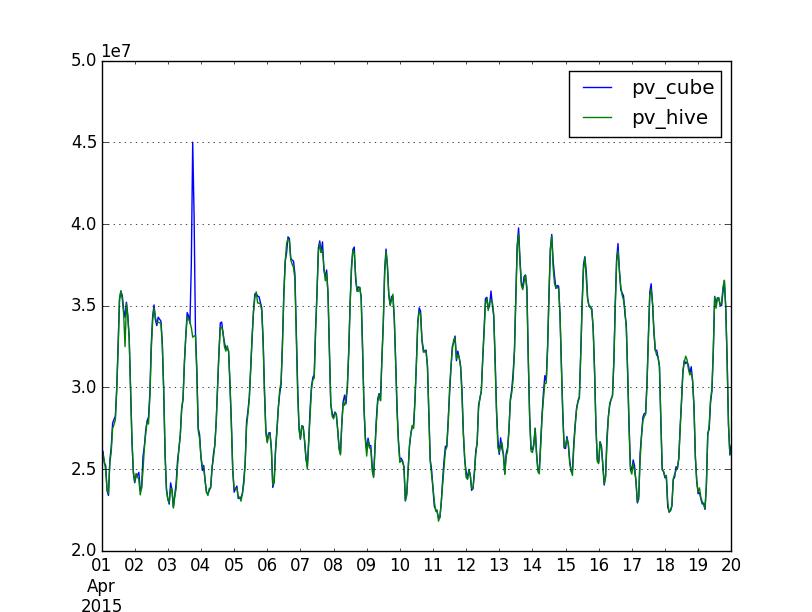
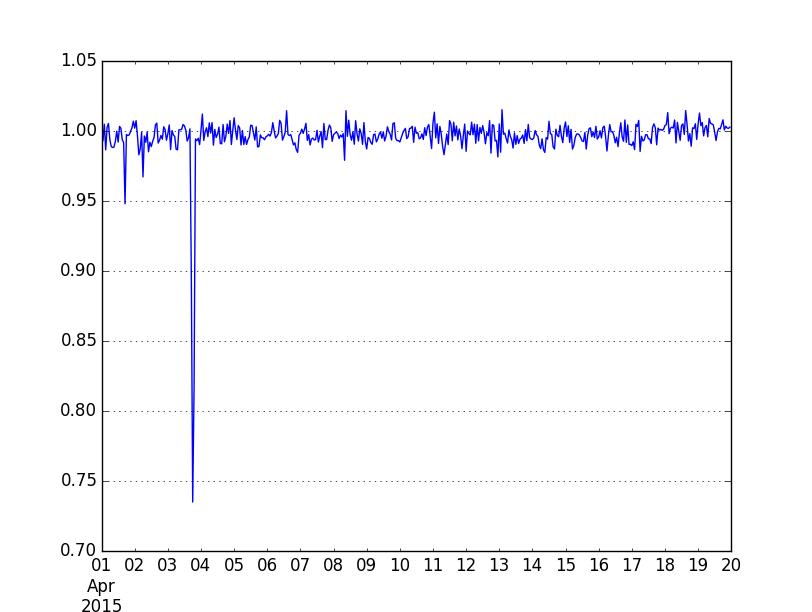
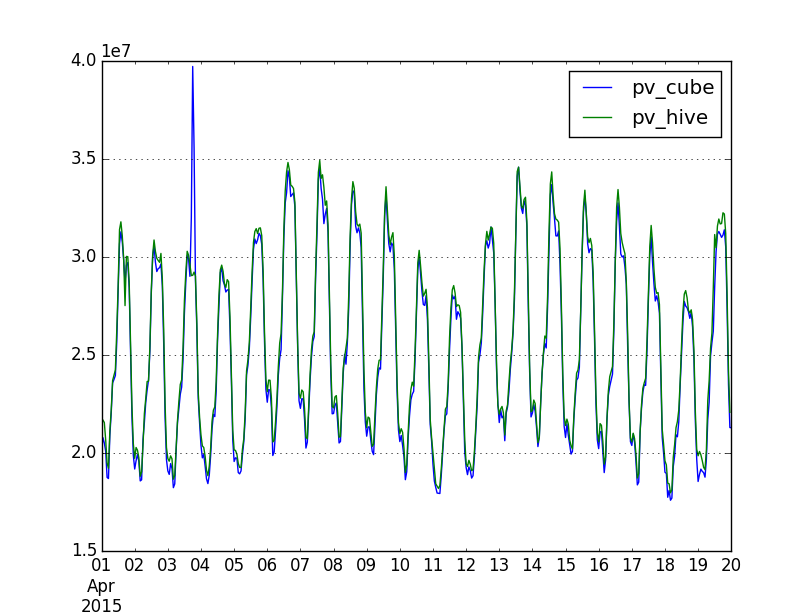
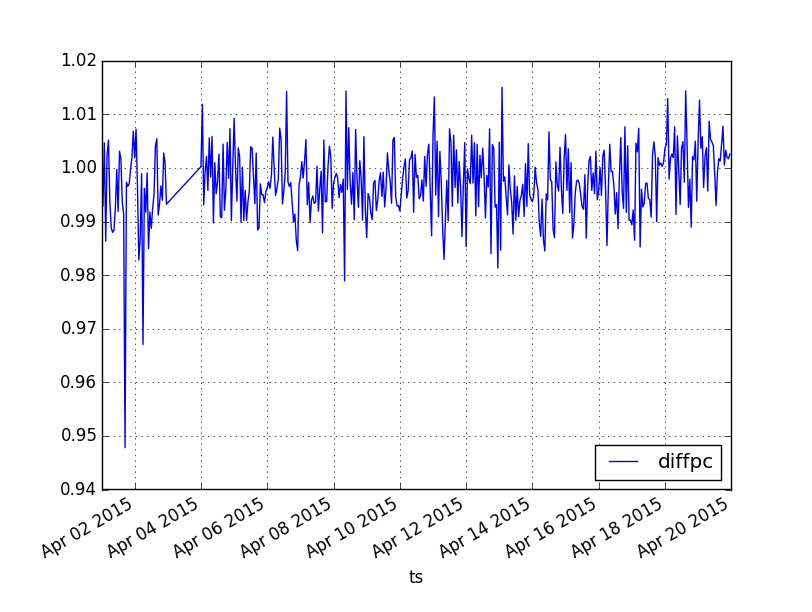
As envisaged, I did some spot checks to see if the new def sampled PV data I had used for the Q3 report (cube 0.5, back then via Pentaho) matches with the new def unsampled PV data on Hive. Picking two days during the overlap in April 2015:
Example #1:
mysql:research@analytics-store.eqiad.wmnet [staging]> select sum(pageviews) from pageviews05 where timestamp between '2015-04-15 00:00:00' and '2015-04-16 00:00:00' and is_spider = 0;
+----------------+
sum(pageviews) +----------------+
634431000 +----------------+
BUT:
hive (wmf)> select sum(view_count) from projectview_hourly where agent_type <> 'spider' and year=2015 and month=04 and day=15;
622049519Example #2:
mysql:research@analytics-store.eqiad.wmnet [staging]> select sum(pageviews) from pageviews05 where timestamp between '2015-04-16 00:00:00' and '2015-04-17 00:00:00' and is_spider = 0;
+----------------+
sum(pageviews) +----------------+
626001000 +----------------+
BUT
hive (wmf)> select sum(view_count) from projectview_hourly where agent_type <> 'spider' and year=2015 and month=04 and day=16;
616117283(I also added these examples to our Etherpad at https://etherpad.wikimedia.org/p/analytics-notes , but feel free to move it to a more appropriate place - not sure if it merits a Phabricator task.)
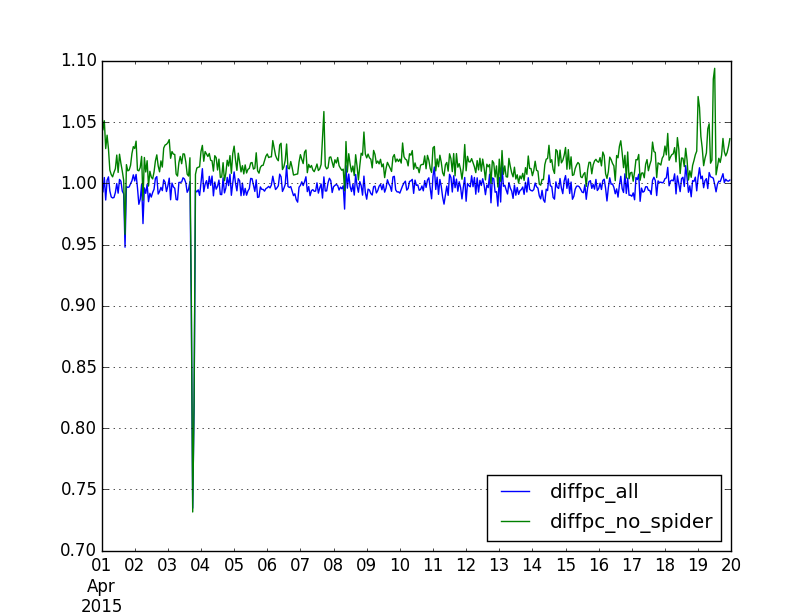
I didn't have time to look further into these discrepancies before the publication of the report, which is why the Q3 and y-o-y trend data in the quarterly scorecard is marked as "N/A" in the pageviews section.
But it would still be good to find out the reason. IIRC you said that these two databases are based on the same (iteration of the new) pageview definition. Are we certain that both use the same timezone? And what was the sampling method - was it realized via counters, or did it rely on random number generators?
Wikidata doesn't make the difference (200k view_count vs 10m missing) so it would be good to investigate in spider or projects differences.