This task was simplified per a conversation with @Tnegrin. We're going to publish a new dataset, in WSC format, to feed into the Monthly Pageview Reports. The Traffic Breakdown Reports will be done as part of the wikistats 2.0 project.
Archiving the rest of the description because it's useful:
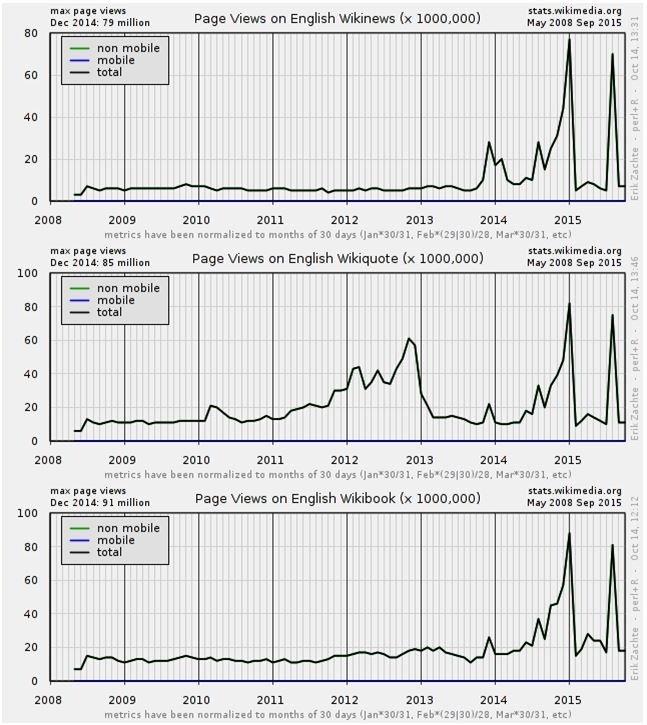
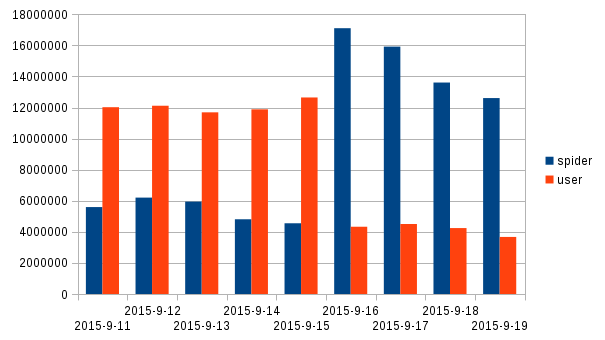
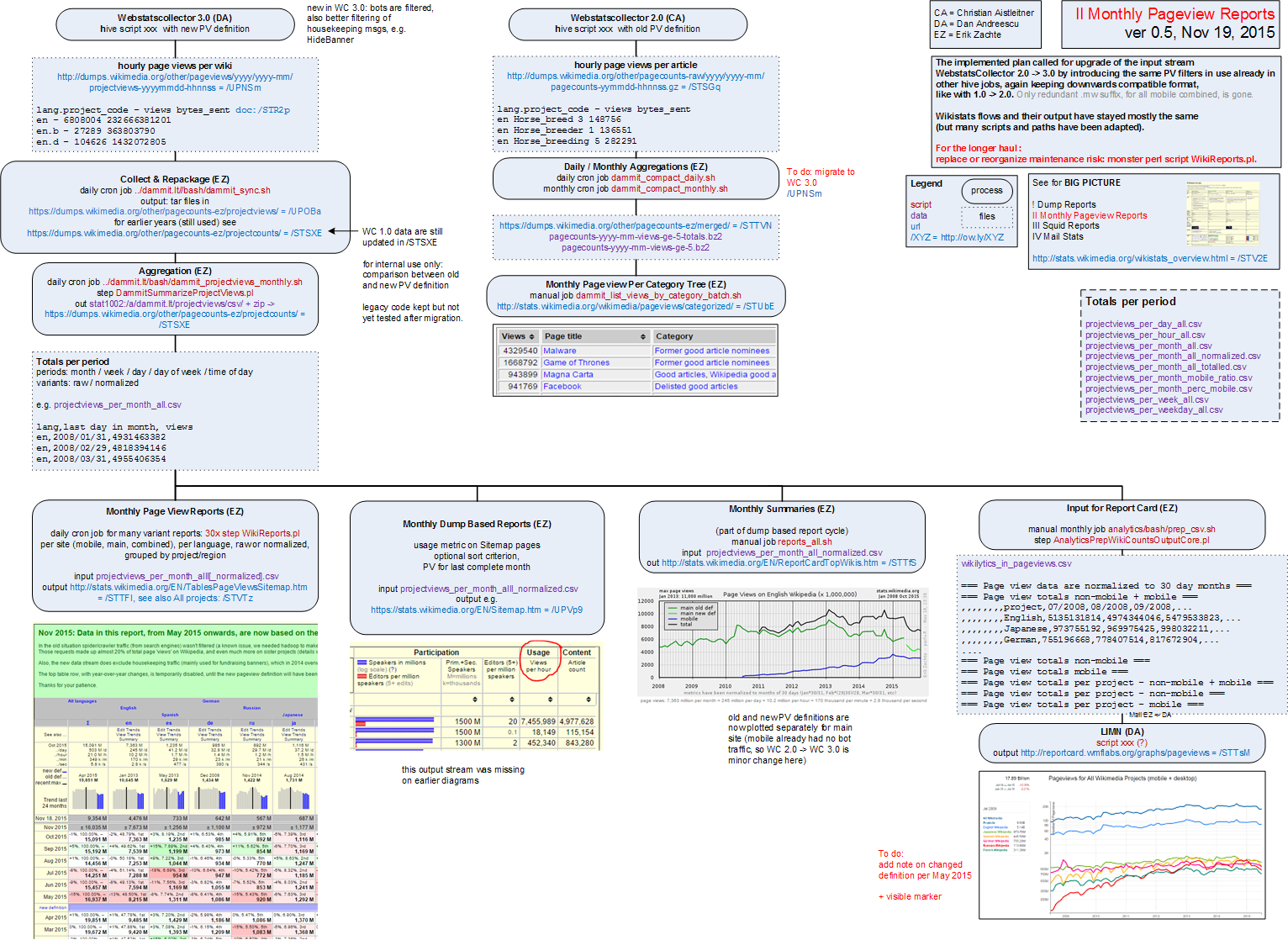
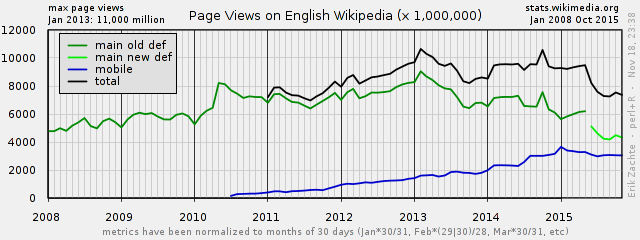
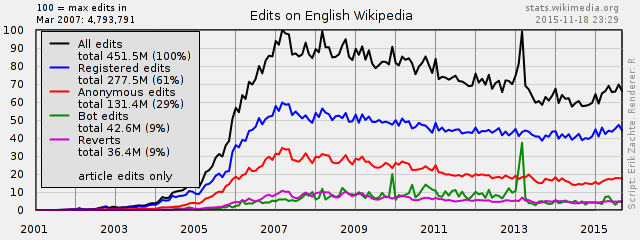
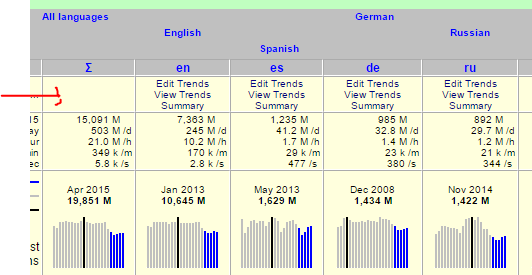
First step in replacing/updating Wikistats traffic reports is feeding these with aggregated hive data directly. This will take away confusion over multiple contradictory counts and take away the need for multiple maintenance in perl and hive.
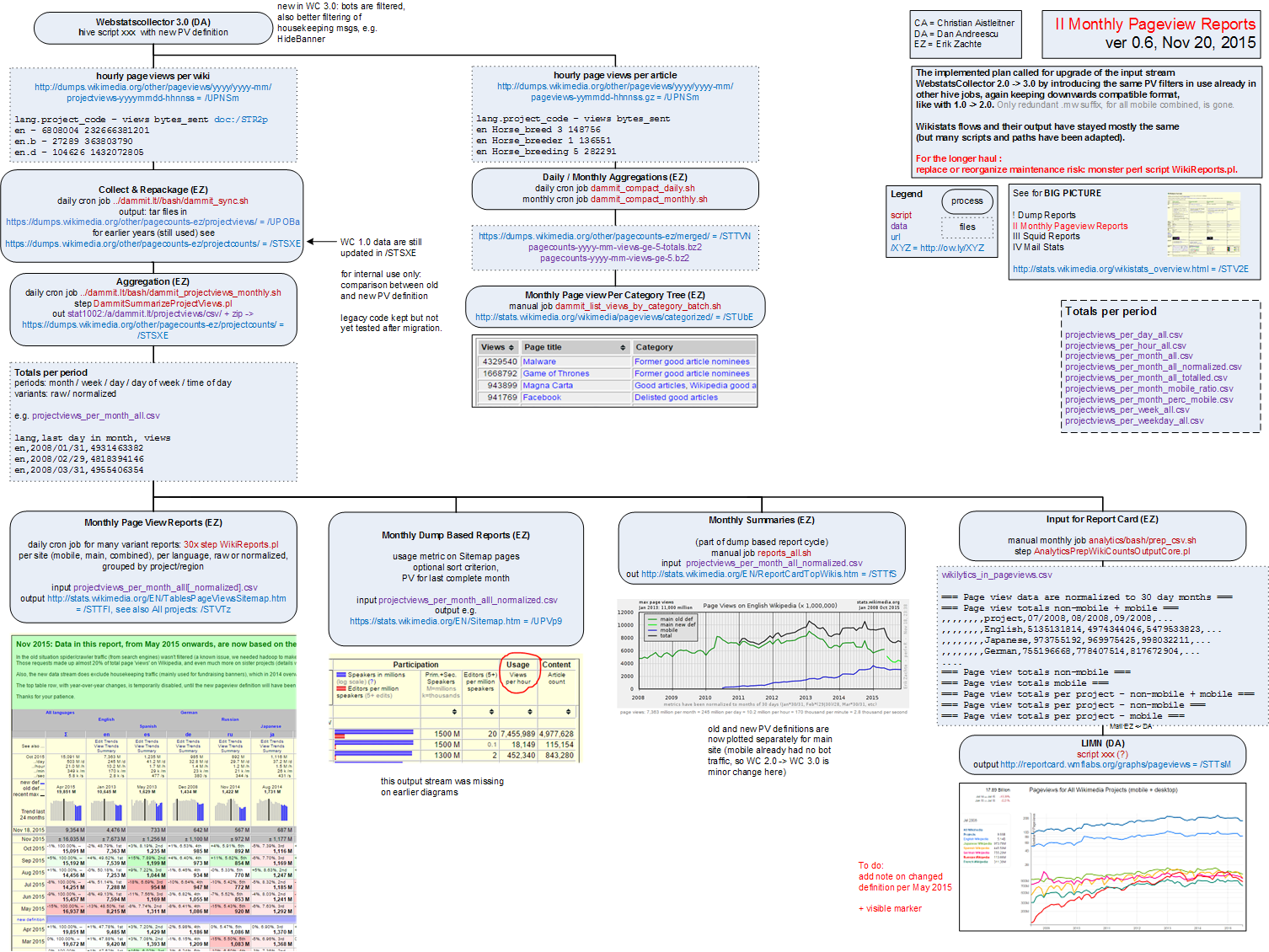
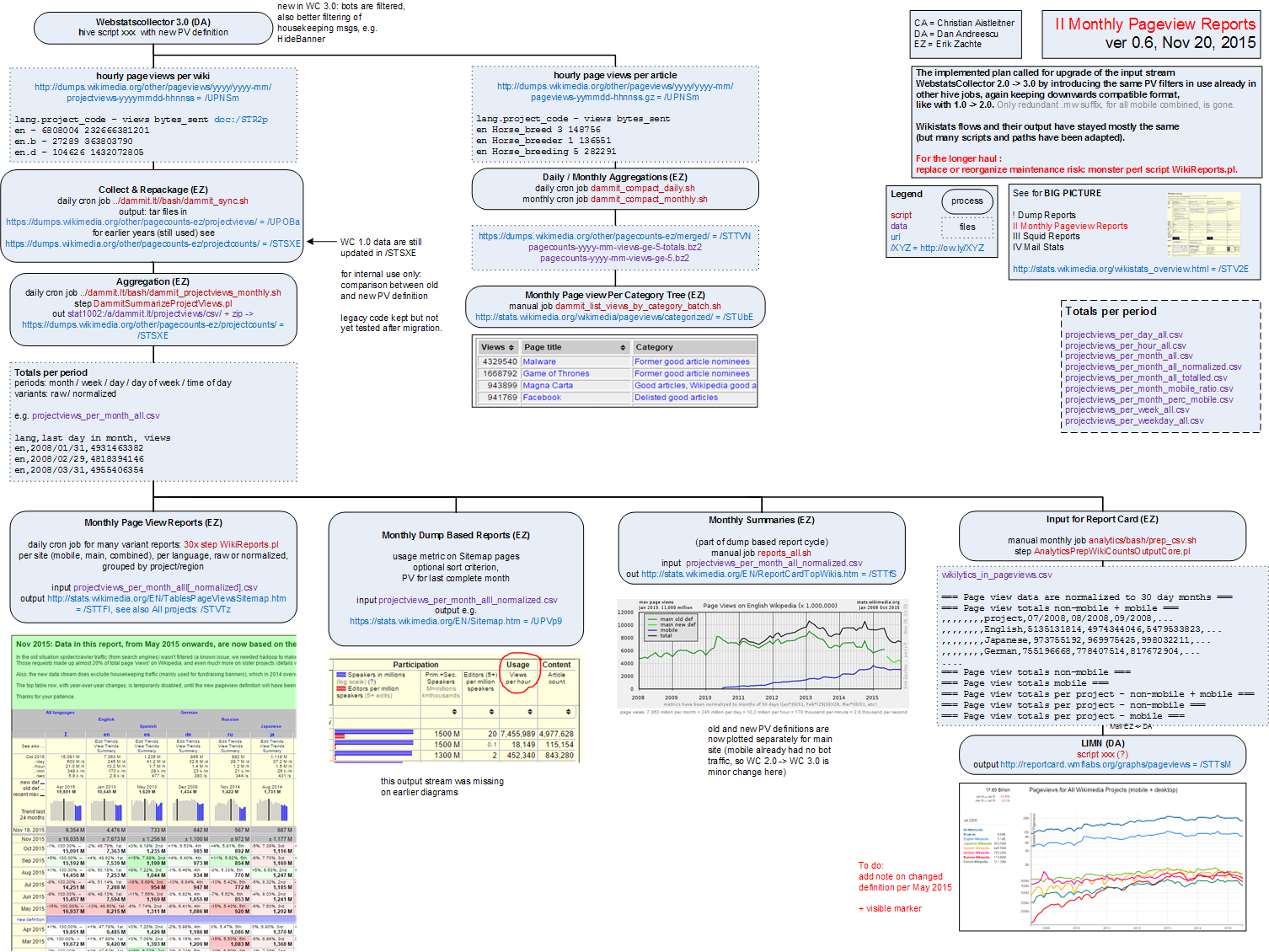
There are two independent process flows. For each a proposal I made a diagram (png). These diagrams are pretty dense, trying to reconcile overview and detail, for use by developer, but I can make a light version if required.
Monthly Pageviews Reports ver 0.1 Oct 1, 2015

Monthly Pageviews Reports ver 0.6 Nov 19, 2015
Traffic Breakdown Reports ver 0.2 Oct 1, 2015