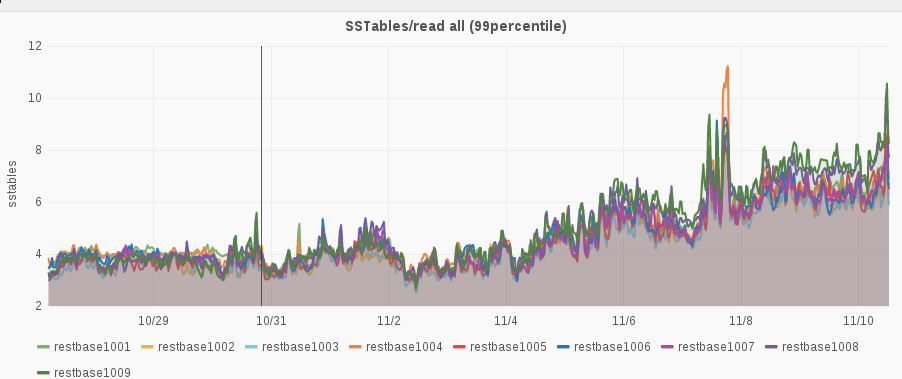
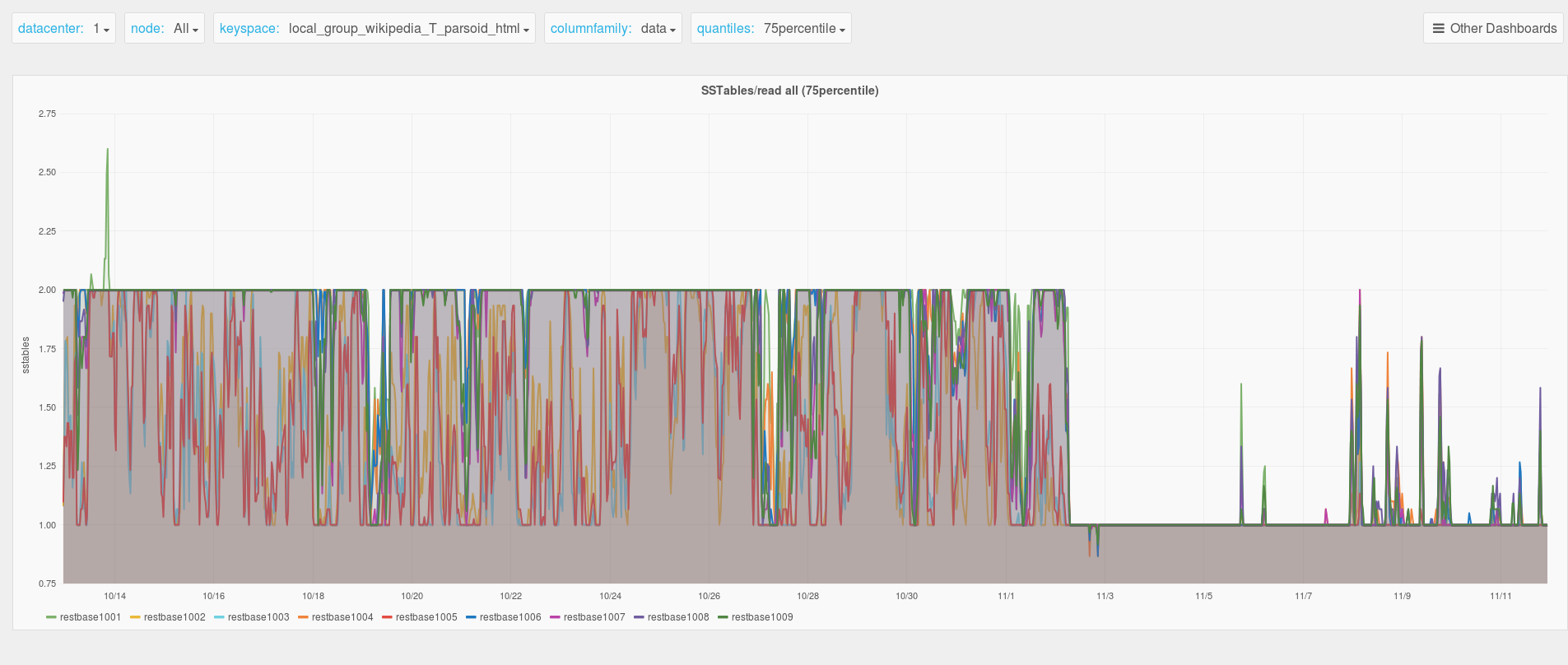
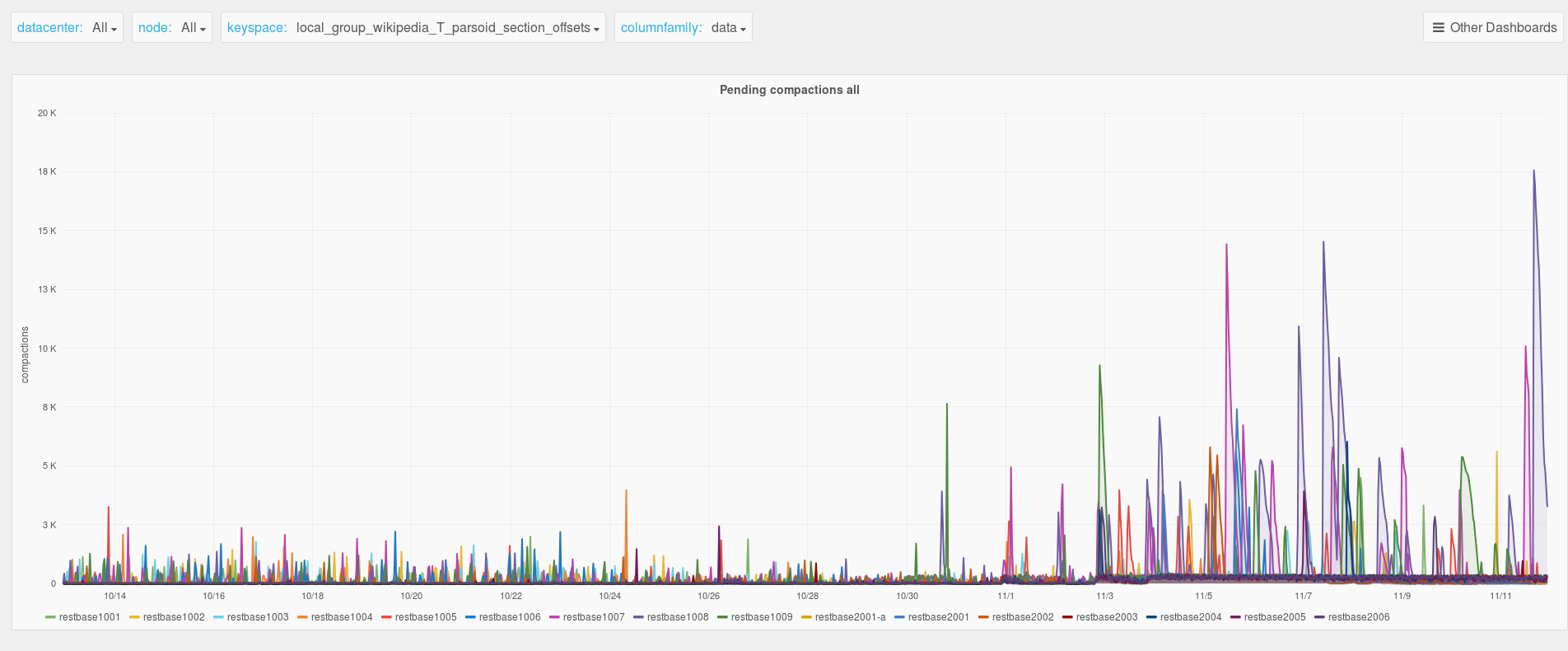
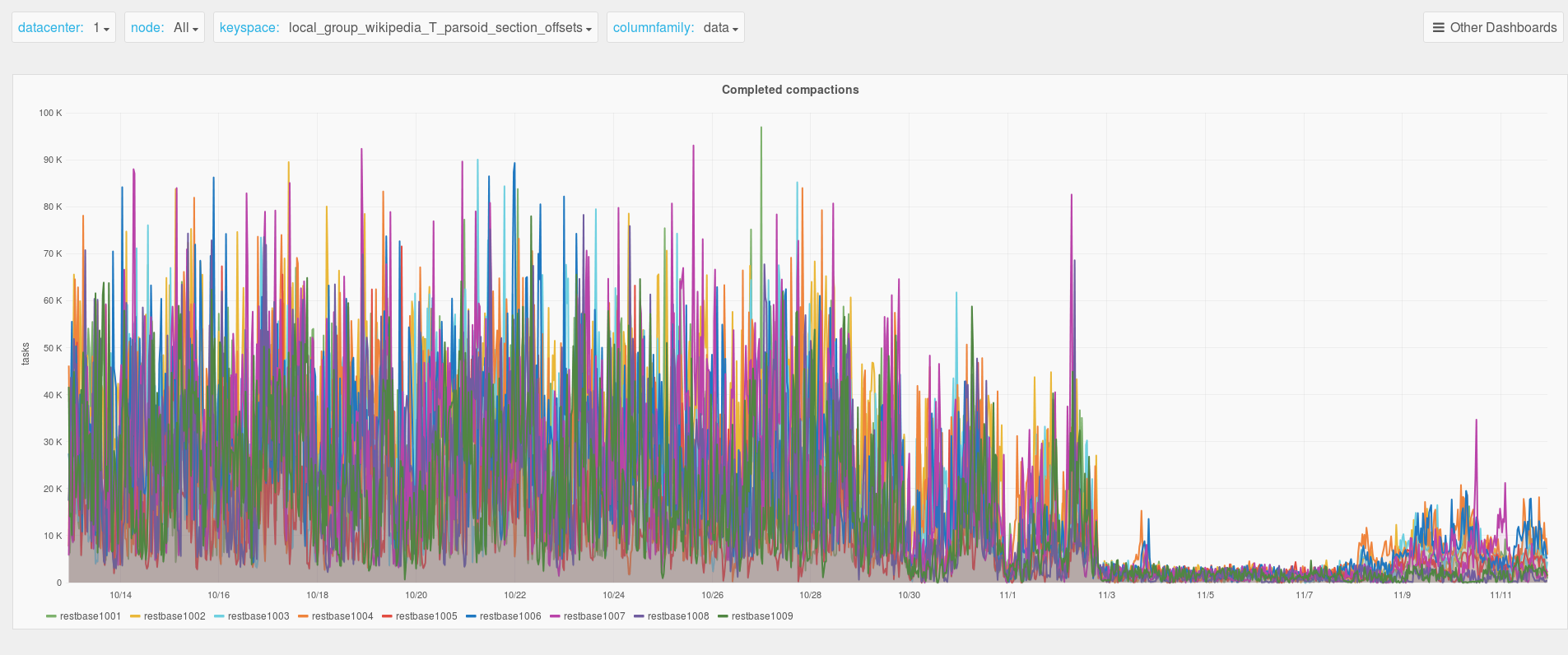
The investigation into timeouts in T116933 showed that leveled compaction's inability to ignore sstables containing tombstones for a partition key is likely causing timeouts and memory pressure for keys that are extremely frequently rerendered. A subsequent experiment in staging shows promising performance with the Date-Tiered Compaction Strategy (DTCS). A key benefit of using this strategy is its non-overlapping sstable hierarchy by writetime, which lets it avoid reading older tombstones when it can establish that their writetime is further in the past based on the hierarchy.
Configuring individual tables to use DTCS is fairly simple:
alter table data WITH compaction = {'class': 'DateTieredCompactionStrategy', 'base_time_seconds':'3600', 'max_sstable_age_days':'365'} and gc_grace_seconds = 86400;For this reason, I'm proposing to start cautiously testing this in production as well, starting with small projects. The metrics collected under realistic conditions will let us make an informed decision about using DCTS by default.