Right now we have no quantitative metric defined to measure satisfaction with the completion suggester. We should measure this somehow.
Description
Description
Event Timeline
Comment Actions
Pulled this into Discovery-Analysis (Current work) and assigned it to @mpopov to reflect the reality of the situation.
Comment Actions
Okay, the proposed TestSearchSatisfaction3 schema has an extraParams field for including information like "opted in to completion suggester".
We can then compare the clickthrough rate differences of users with completion suggester vs users without. Furthermore, we can use survival analysis to see if completion suggester helps users stay on pages longer.
@Ironholds Thoughts?
Comment Actions
For the existing beta, with the view of then becoming the logging that we would use if the feature is pushed to production.
Comment Actions
That's something I've been debating about with myself. On one hand, I think the scientifically right thing to do would be to run a proper test where a user is randomly selected for this test and then are either given the completion suggester or not.
But we're primarily interested in how the people who opted in to completion suggester have been affected. I don't think it makes sense to compare their measurements with the overall population, so maybe we could try a small placebo experiment wherein we take a small sample of users who have opted in to the completion suggester and silently turn it off for half of them so that it's still "on" on their beta features panel but actually turned off behind the scenes? That may be a bit far fetched and impossible to engineer, though.
Comment Actions
If there's thinking that we should run an A/B test, then we can definitely consider that. We have run an A/B test before on the completion suggester, of course. How would this differ?
Comment Actions
This is a different test in that the outcome is clickthrough + dwell time, not zero results rate. But THE KEY difference is between the populations if we don't do an A/B test. I'm not comfortable comparing outcomes (clickthrough + dwell time) of ALL kinds of users vs. users with accounts (subset) who have completion suggester enabled (subset of a subset) who inherently use our product differently than the general population.
Comment Actions
Thanks, that helps. We could do an A/B test on that, irrespective of the beta feature, in the same manner as our previous test; we give some people the completion suggester randomly, and measure them against a base cohort. If you want us to proceed down that avenue, please write a task for it and raise it as a discussion point in our next sprint planning meeting. :-)
Comment Actions
So, I'd strongly suggest:
- Using it as well as, instead of as a replacement for, the existing schema. The target population is totally different. Only logged-in people are using the completion suggester: if you want anywhere near as many results as you'll need for something interesting, you need to be specifically targeting editors with this schema;
- Based on 1, change the name? *3 suggests it's a successor/replacement for *2. It's really not in its audience. In fact, they should be running in parallel unless we're really confident we can pull enough events from a broad sample of _readers_ to get something important here.
Comment Actions
Okay, after some discussion, the consensus here is:
- Schema:TestSearchSatisfaction3 should be moved to the name Schema:AutocompleteSatisfaction
- We do not need an A/B test. This will just be base logging for the suggester.
- This is a supplement to our existing search satisfaction schema, not a replacement.
- We want to track a base population to compare against.
Outstanding questions:
- Sampling rates
- Who is the base population?
Semi-related points:
- We should rename the other search satisfaction schema at some point, but that's harder and more complicated, so we can defer.
Comment Actions
Proposed schema: https://meta.wikimedia.org/wiki/Schema:AutocompleteSatisfaction
The base population is editors (users with accounts) so we can compare those who opted-in to those who have not, because then we can expect the two groups to have similar search behaviors.
As for sampling, I don't know if we should have different sampling rates for those who opted-in to completion suggester vs those who haven't. I think we should have an overall rate (e.g. 1%) that will enable us to also get an estimate of the % who have opted-in. Let's start with 0.5% or 0.01% and then increase it if we have to?
Comment Actions
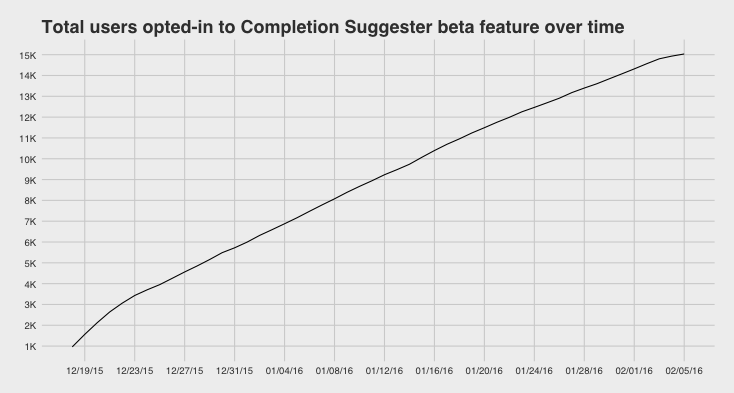
As of this morning: 15K opted-in, 45.3K opted-out (based on the PrefUpdate table).
I'm gonna try generating a couple of opt-in/opt-out graphs over time because that seems like something we should know.
This comment was removed by mpopov.
Comment Actions

Selected users' Completion Suggester opt-in/out switching over time (above/below the line, respectively):

Visualizes 20 users' back-and-forth decision-making.
Update: adjusted the filter a little bit so it's better at picking out which users' switch tracks to show

Comment Actions
Per @debt's suggestion/request:
which uses the same technology as our dashboards to allow zooming in to see the granular, minute-by-minute changesComment Actions
I want to note here that we discussed (on IRC) the possibility of identifying & contacting users who switched back and forth a few times and then settled on "off" because it would be interesting to hear why they had chosen to finally opt-out after opting-in. This will be brought up in the search sprint meeting.
Comment Actions
That needs to be discussed with Legal. "our data said you did a thing so we contacted you privately/publicly about the thing revealing data in the process/using other data in the process" is an area that has traditionally been ehhhhh.
Comment Actions
Indeed. Even ignoring legal issues, @leila told me about issues that she ran in to when doing reading recommendations; some people were surprised/annoyed to be contacted unexpectedly. None of these are blockers, but they do need to be considered.
Comment Actions
@Deskana the issue we ran into was when we contacted users for article creation recommendation, not article read recommendation.
Most of the complaints we received (around 0.1% of those who had received the emails raised concerns) where from users that were contacted by mistake (in a language they did not speak). That's a black-and-white issue: they shouldn't have been contacted. A small percentage of the users contacted us and raised the issues around user privacy, especially that in the same week the users were contacted, the issue of email privacy was on in French Parliament.
If you are considering to contact users who have opted in for beta, that may be less problematic in general, as they have opted in for a system where they know things are experimental and we may ask for their feedback. I suggest:
- Not contacting users who in their user preferences have specified they don't want to receive emails from other users.
- Checking with our Legal team to make sure it's fine to email users.
- If you're in Desktop, consider running a QuickSurvey widget if that works for your use-case.