[05:21] <icinga-wm> PROBLEM - logstash process on logstash1003 is CRITICAL: PROCS CRITICAL: 0 processes with UID = 998 (logstash), command name java, args logstash
Logs on logstash1003 showed that process had died from heap exhaustion:
Error: Your application used more memory than the safety cap of 500M.
Specify -J-Xmx##m to increase it (## = cap size in MB).
Specify -w for full OutOfMemoryError stack trace
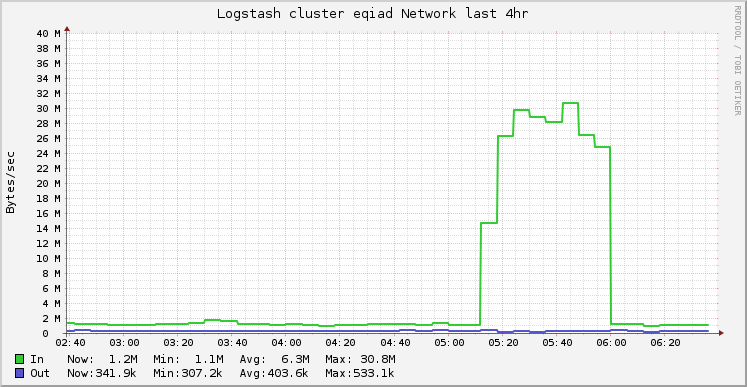
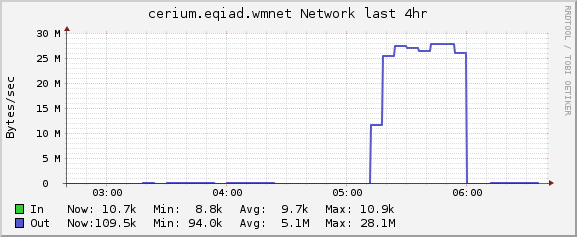
Network traffic to logstash cluster was up as was outbound from restbase cluster: