Original summary
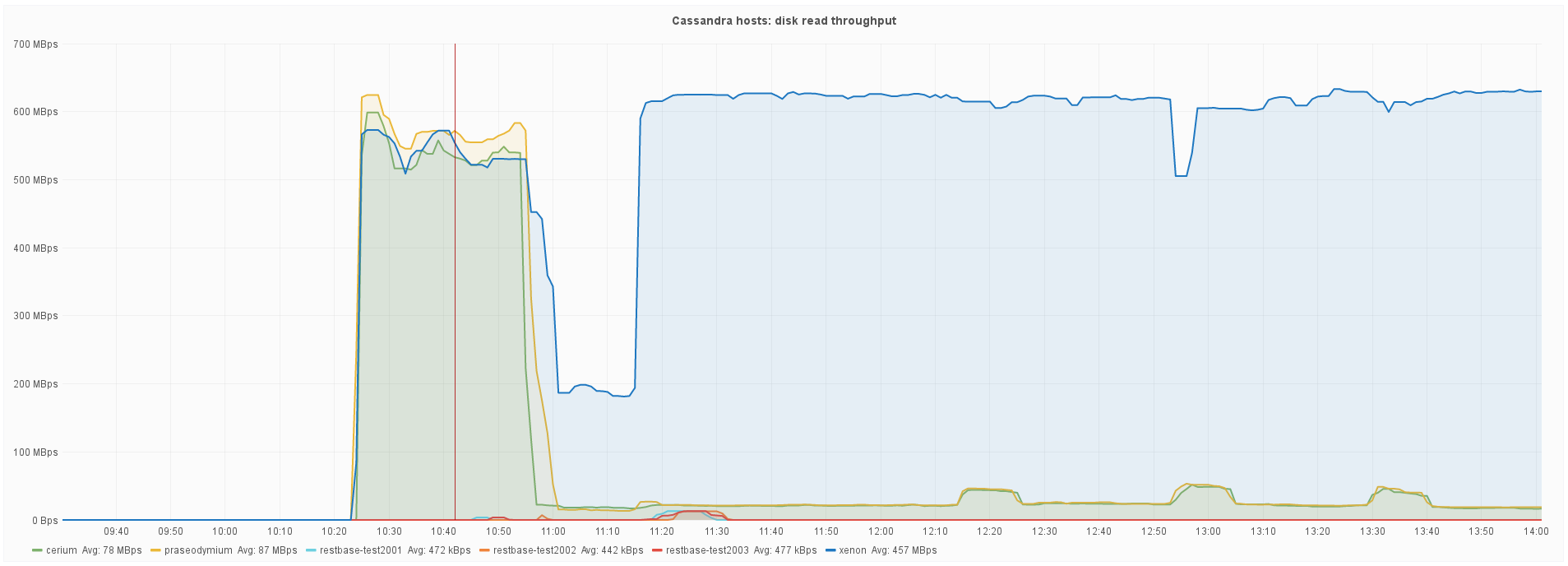
Upon upgrading the first host in production (restbase1007) to Cassandra 2.2.6, very high levels of disk read throughput were encountered (10x or more). Ultimately it required setting disk_access_mode to mmap_index_only to restore normal levels. Since memory-mapped decompression reads were an important new feature of 2.2 for us, we should figure out why this, and what is needed to correct it.
See also: https://wikitech.wikimedia.org/wiki/Incident_documentation/20160531-RESTBase
Update
This issue still affects Cassandra 3, so it is still relevant. The work-around from 2.2 still works, but he option might no longer be officially supported (@Eevans: is this accurate?).