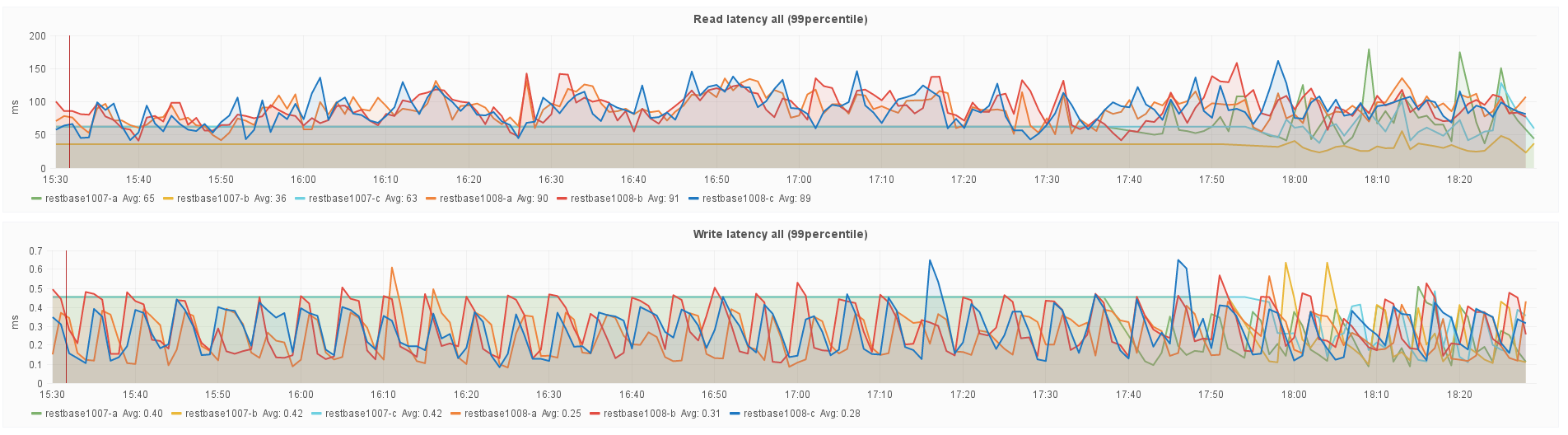
Histogram metrics are lacking the recency bias in 2.2.6 that they had in 2.1.13, resulting in strangely consistent values.
See also: https://issues.apache.org/jira/browse/CASSANDRA-11752
| Eevans | |
| Jun 9 2016, 7:42 PM |
| F4400926: Screenshot from 2016-08-24 19-46-38.png | |
| Aug 25 2016, 9:39 PM |
| F4400929: Screenshot from 2016-08-24 19-43-37.png | |
| Aug 25 2016, 9:39 PM |
| F4400927: Screenshot from 2016-08-24 19-45-02.png | |
| Aug 25 2016, 9:39 PM |
| F4400930: Screenshot from 2016-08-24 19-46-15.png | |
| Aug 25 2016, 9:39 PM |
| F4400928: Screenshot from 2016-08-24 19-44-25.png | |
| Aug 25 2016, 9:39 PM |
| F4161746: Screenshot from 2016-06-13 13-30-07.png | |
| Jun 13 2016, 6:31 PM |
| F4150582: Screenshot from 2016-06-10 17-29-06.png | |
| Jun 10 2016, 3:32 PM |
| F4147640: Screenshot from 2016-06-09 21-40-31.png | |
| Jun 9 2016, 7:42 PM |
Histogram metrics are lacking the recency bias in 2.2.6 that they had in 2.1.13, resulting in strangely consistent values.
See also: https://issues.apache.org/jira/browse/CASSANDRA-11752
| Status | Subtype | Assigned | Task | ||
|---|---|---|---|---|---|
| Invalid | None | T93751 RFC: Next steps for long-term revision storage -- space needs, storage hierarchies | |||
| Declined | Eevans | T93496 Improve revision compression in Cassandra / Brotli or LZMA support | |||
| Declined | Eevans | T125904 Brotli compression for Cassandra | |||
| Declined | None | T120171 RFC: Differentiate storage strategies for archival storage vs. hot current data | |||
| Declined | None | T122028 RFC: Chunked storage algorithms for archival data vs. large-window brotli compression | |||
| Declined | Eevans | T125906 Evaluate Brotli compression for Cassandra | |||
| Invalid | None | T126582 Log input from cassandra caused logstash process to crash repeatedly | |||
| Resolved | • GWicke | T111746 [future] Keep an eye on materialized views in Cassandra 3.0 | |||
| Resolved | Eevans | T126629 Cassandra 2.2.6 | |||
| Resolved | Eevans | T137474 Investigate lack of recency bias in Cassandra histogram metrics |
Mentioned in SAL [2016-06-09T19:59:15Z] <urandom> Restarting Cassandra on xenon.eqiad.wmnet (removing patched test build; restoring state) : T137474
Mentioned in SAL [2016-06-10T13:13:00Z] <urandom> Testing patched Cassandra (dpkg -i ...; service cassandra-a restart) on xenon : T137474
Mentioned in SAL [2016-06-10T13:15:03Z] <urandom> Starting html dump(s) in RESTBase staging : T137474
Mentioned in SAL [2016-06-10T13:58:27Z] <urandom> Testing patched Cassandra (dpkg -i ...; service cassandra-a restart) on cerium : T137474
Mentioned in SAL [2016-06-10T13:59:54Z] <urandom> Testing patched Cassandra (dpkg -i ...; service cassandra-a restart) on praseodymim : T137474
Mentioned in SAL [2016-06-10T14:06:51Z] <urandom> Testing patched Cassandra (dpkg -i ...; service cassandra-a restart) on restbase-test2001 : T137474
Mentioned in SAL [2016-06-10T14:17:43Z] <urandom> Testing patched Cassandra (dpkg -i ...; service cassandra-{a,b} restart) on restbase-test200[1-2] : T137474
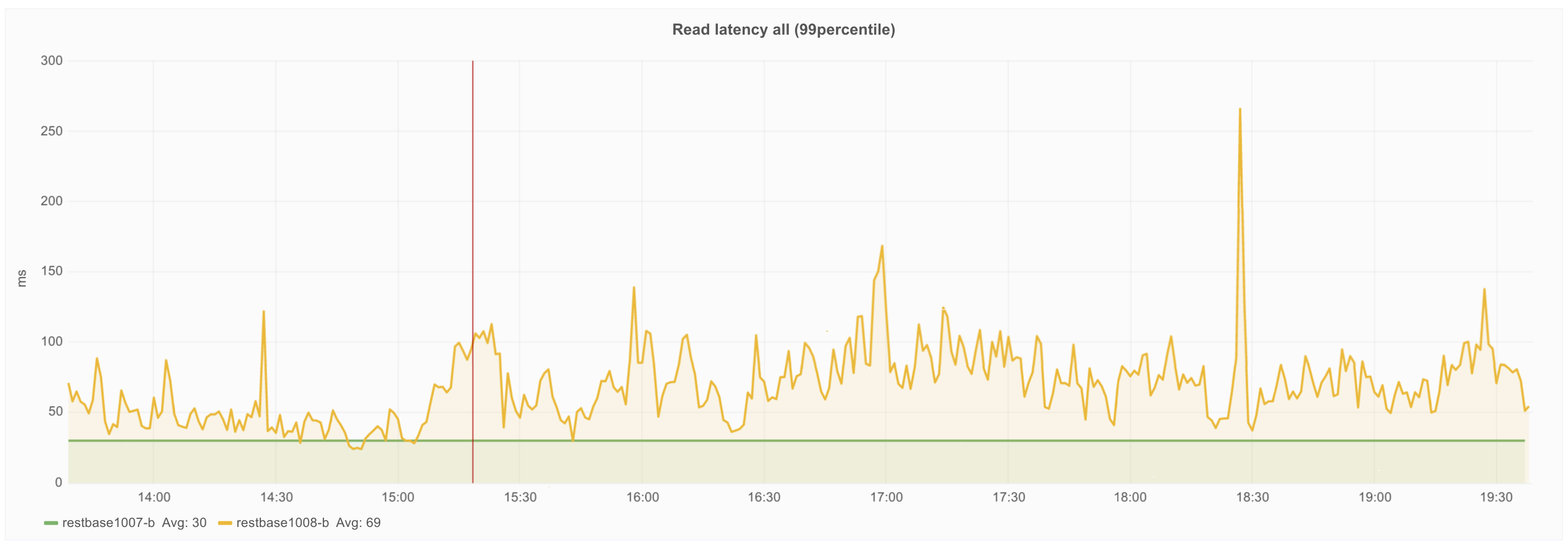
The root cause here is a deliberate change to the histogram implementation in order to address concerns some had over the lossy nature of the forward-decaying priority reservoir sampling used prior to Cassandra 2.2. Options are still being discussed on CASSANDRA-11752, but consensus seems to be that at a minimum, percentile accessors should be recency biased without requiring a reset-on-read.
Until a resolution to CASSANDRA-11752 is available, I propose we patch our build to make use of the Dropwizard ExponentiallyDecayingReservoir (the implementation used in 2.1). The patch for this is very simple:
diff --git a/src/java/org/apache/cassandra/metrics/CassandraMetricsRegistry.java b/src/java/org/apache/cassandra/metrics/CassandraMetricsRegistry.java index 6fdb2ff..308a65b 100644 --- a/src/java/org/apache/cassandra/metrics/CassandraMetricsRegistry.java +++ b/src/java/org/apache/cassandra/metrics/CassandraMetricsRegistry.java @@ -60,7 +60,7 @@ public class CassandraMetricsRegistry extends MetricRegistry public Histogram histogram(MetricName name, boolean considerZeroes) { - Histogram histogram = register(name, new ClearableHistogram(new EstimatedHistogramReservoir(considerZeroes))); + Histogram histogram = register(name, new Histogram(new ExponentiallyDecayingReservoir())); registerMBean(histogram, name.getMBeanName()); return histogram; @@ -68,7 +68,7 @@ public class CassandraMetricsRegistry extends MetricRegistry public Timer timer(MetricName name) { - Timer timer = register(name, new Timer(new EstimatedHistogramReservoir(false))); + Timer timer = register(name, new Timer(new ExponentiallyDecayingReservoir())); registerMBean(timer, name.getMBeanName()); return timer;
I have built Debian packages that apply this patch as part of the package build, they can be found here. I've manually installed these packages on the staging cluster, and have a couple of dump processes running.
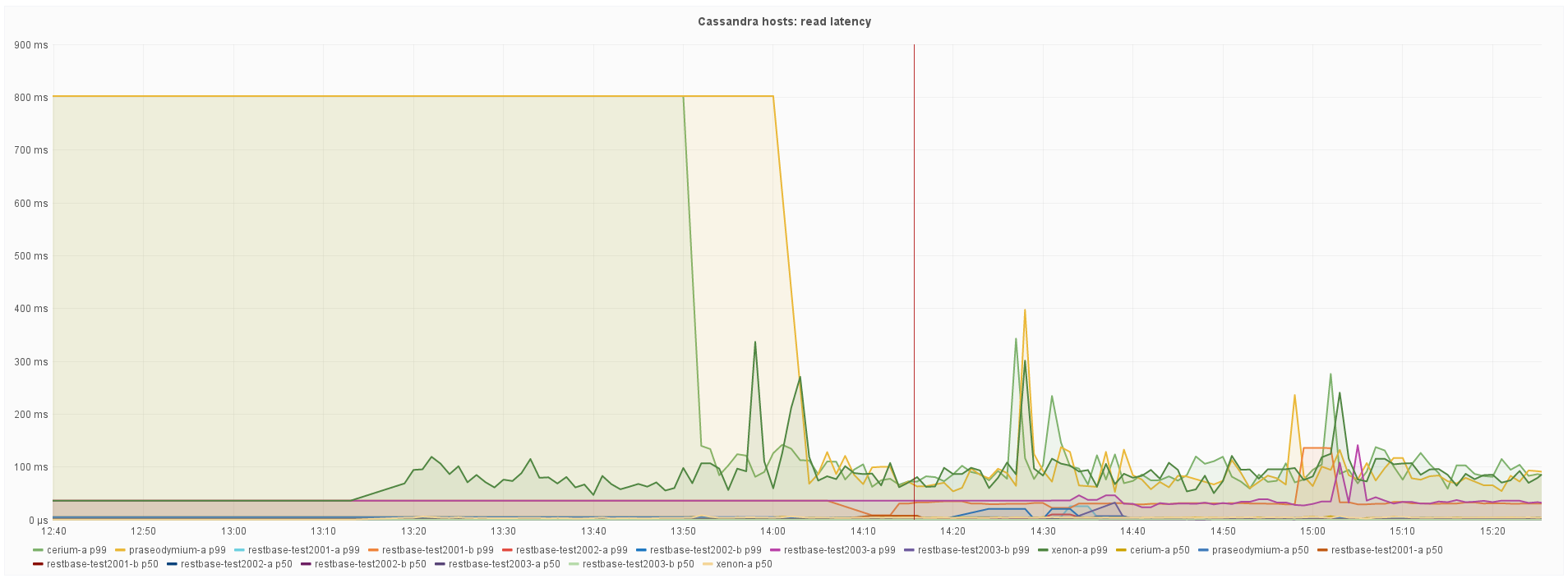
I propose that we keep the dumps running over the weekend, and upgrade restbase1007.eqiad.wmnet on Monday if everything continues to look OK.
Hmm, we have around 10% free space left on eqiad-staging nodes (~40 GB). Since the idea is to run the dumps, perhaps it'd be worth truncating the most significant CFs to be in the clear?
This looks awesome! Thank you, @Eevans for investigating and coming up with a working solution so quickly!
It's going to be difficult to move the needle by a whole lot without truncating the wikipedia parsoid tables (which we've been reluctant to do so far). Truncating local_group_wikipedia_T_mobileapps_remaining would free up ~23G, and local_group_wikipedia_T_mobileapps_lead another ~8G (combined that's about 10% of the current data); Are we OK truncating the mobileapps tables?
[ ... ] 43165683 data/local_group_wikisource_T_parsoid_html 45114701 data/local_group_phase0_T_parsoid_html 2296759180 data/local_group_wikipedia_T_summary 8347359051 data/local_group_wikipedia_T_title__revisions 8465207914 data/local_group_wikipedia_T_mobileapps_lead 9147278915 data/local_group_wikipedia_T_parsoid_section_offsets 24520085710 data/local_group_wikipedia_T_mobileapps_remaining 76365898022 data/local_group_wikipedia_T_parsoid_dataW4ULtxs1oMqJ 188561917420 data/local_group_wikipedia_T_parsoid_html 318081577290 total
It's going to be difficult to move the needle by a whole lot without truncating the wikipedia parsoid tables (which we've been reluctant to do so far).
I know, but we are coming at a point where we have to take a decision what to do next, otherwise we won't be able to store anything any more (but let's not discuss this here, it's kind of OT for this task).
For the time being keep the dumps running so that we collect as much data as possible. I will monitor the nodes over the week-end and if we come dangerously close to filling the disk I'll stop the dump. Where is it running from?
Truncating local_group_wikipedia_T_mobileapps_remaining would free up ~23G, and local_group_wikipedia_T_mobileapps_lead another ~8G (combined that's about 10% of the current data); Are we OK truncating the mobileapps tables?
Sure, go ahead and do that.
Thanks @mobrovac ! The dumps are running on xenon and cerium.
eevans@xenon:~$ screen -ls There is a screen on: 15544.dump (06/09/2016 10:20:00 AM) (Detached) 1 Socket in /var/run/screen/S-eevans.
eevans@cerium:~$ screen -ls There is a screen on: 18952.dump (06/09/2016 10:20:09 AM) (Detached) 1 Socket in /var/run/screen/S-eevans.
Truncating local_group_wikipedia_T_mobileapps_remaining would free up ~23G, and local_group_wikipedia_T_mobileapps_lead another ~8G (combined that's about 10% of the current data); Are we OK truncating the mobileapps tables?
Sure, go ahead and do that.
Done.
$ df -h Filesystem Size Used Avail Use% Mounted on udev 10M 0 10M 0% /dev tmpfs 3.2G 331M 2.8G 11% /run /dev/md0 28G 6.3G 20G 24% / tmpfs 7.8G 0 7.8G 0% /dev/shm tmpfs 5.0M 0 5.0M 0% /run/lock tmpfs 7.8G 0 7.8G 0% /sys/fs/cgroup /dev/mapper/xenon--vg-srv 355G 271G 66G 81% /srv
Dumps ran continuously over the weekend in staging, and the metrics appear reasonable. I'm going to proceed with the upgrade of restbase1007 (the only production node currently running 2.2.6).
Mentioned in SAL [2016-06-13T17:37:11Z] <urandom> Upgrading restbase1007.eqiad.wmnet w/ https://people.wikimedia.org/~eevans/debian/cassandra_2.2.6-wmf1_all.deb : T137474
Mentioned in SAL [2016-06-13T17:38:00Z] <urandom> Restarting restbase1007-a.eqiad.wmnet : T137474
Mentioned in SAL [2016-06-13T17:52:42Z] <urandom> Restarting restbase1007-b.eqiad.wmnet : T137474
Mentioned in SAL [2016-06-13T17:55:20Z] <urandom> Restarting restbase1007-c.eqiad.wmnet : T137474
Mentioned in SAL [2016-06-13T17:58:01Z] <urandom> Upgrade of restbase1007.eqiad.wmnet (https://people.wikimedia.org/~eevans/debian/cassandra_2.2.6-wmf1_all.deb) complete : T137474
Thanks, @Eevans! Is there anything left on this task (upstreaming?), or should we resolve it?
A patch for this has been submitted upstream. We should test this out, and provide feedback if necessary, before it becomes a part of the 2.2.8 release.
A Debian package with a backported patch from https://issues.apache.org/jira/browse/CASSANDRA-11752 can be found at https://people.wikimedia.org/~eevans/debian/
Mentioned in SAL [2016-08-24T20:03:54Z] <urandom> T137474 Starting htmldumper in RESTBase Staging
Mentioned in SAL [2016-08-24T20:59:02Z] <urandom> T137474: Upgrading xenon.eqiad.wmnet to cassandra_2.2.6-wmf2
Mentioned in SAL [2016-08-25T00:51:14Z] <urandom> T137474: Stopping dumps in RESTBase staging, and reverting xenon.eqiad.wmnet to Cassandra 2.2.6-wmf1
Some explanation:
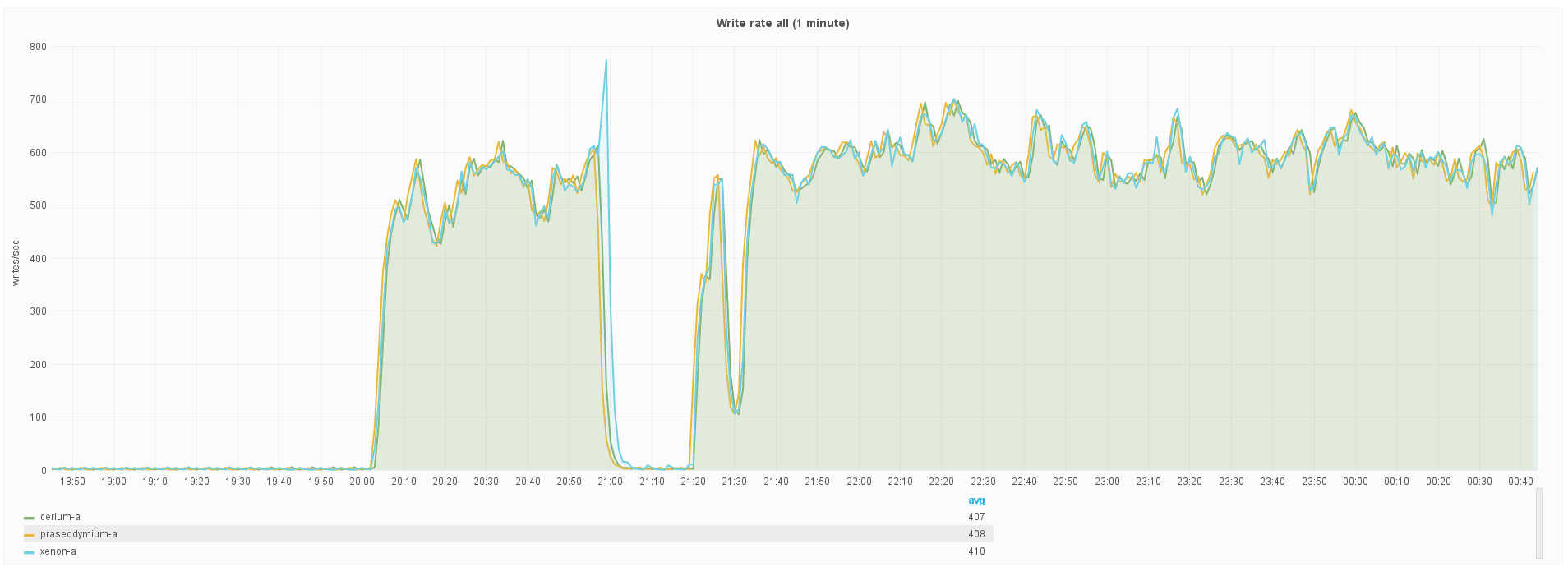
When the test begins at ~20:00, all 3 nodes are running a version of Cassandra 2.2.6 patched to reinstate the Dropwizard ExponentiallyDecayingReservoir that was used prior to Cassandra 2.2:
At ~21:00, traffic generation was stopped long enough to upgrade xenon-a to a version of Cassandra 2.2.6 patched to include what was merged as a part of CASSANDRA-11752.
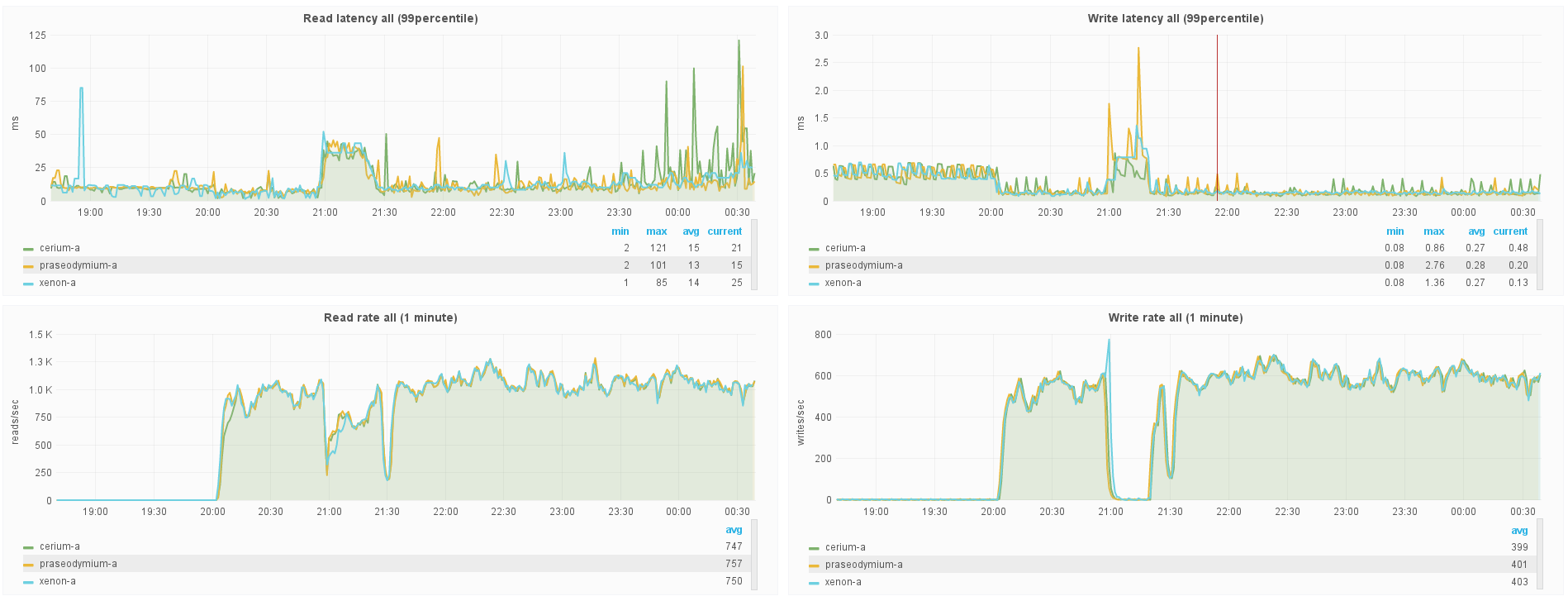
Write rate (org.apache.cassandra.metrics.ColumnFamily.all.WriteLatency.1MinuteRate).
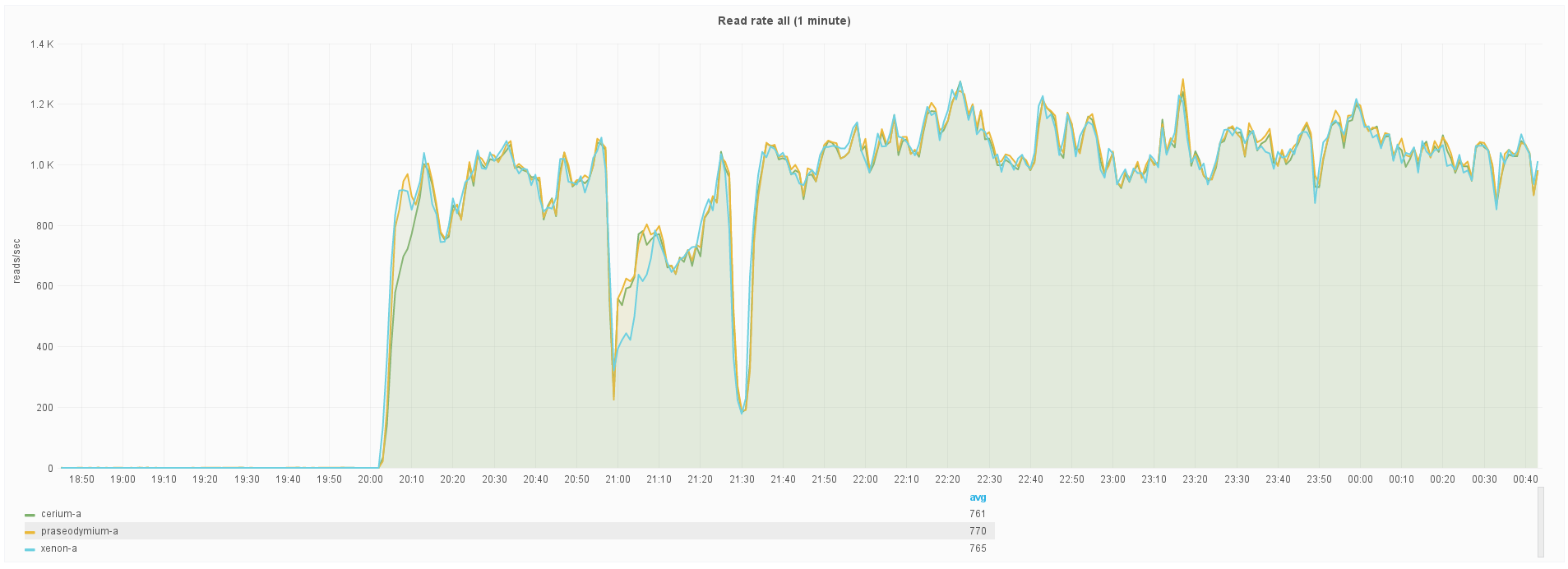
Read rate (org.apache.cassandra.metrics.ColumnFamily.all.ReadLatency.1MinuteRate).
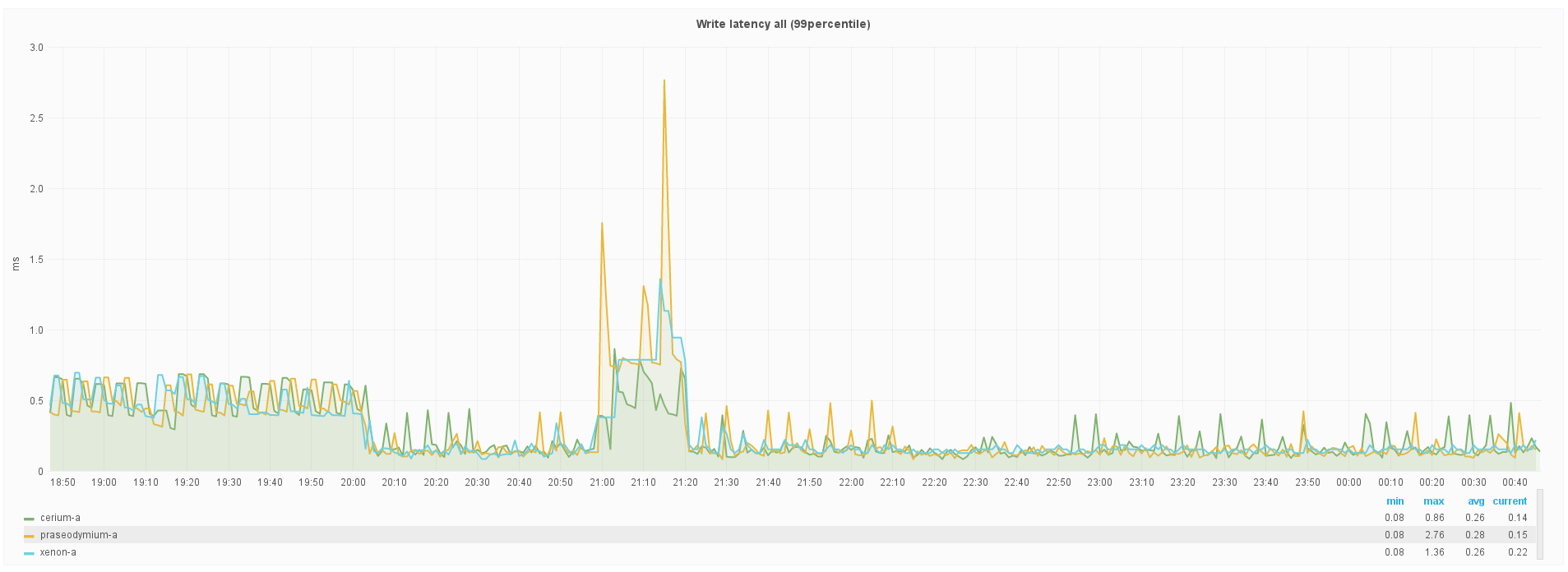
Write latency (org.apache.cassandra.metrics.ColumnFamily.all.WriteLatency.99percentile)
Read latency (org.apache.cassandra.metrics.ColumnFamily.all.ReadLatency.99percentile)
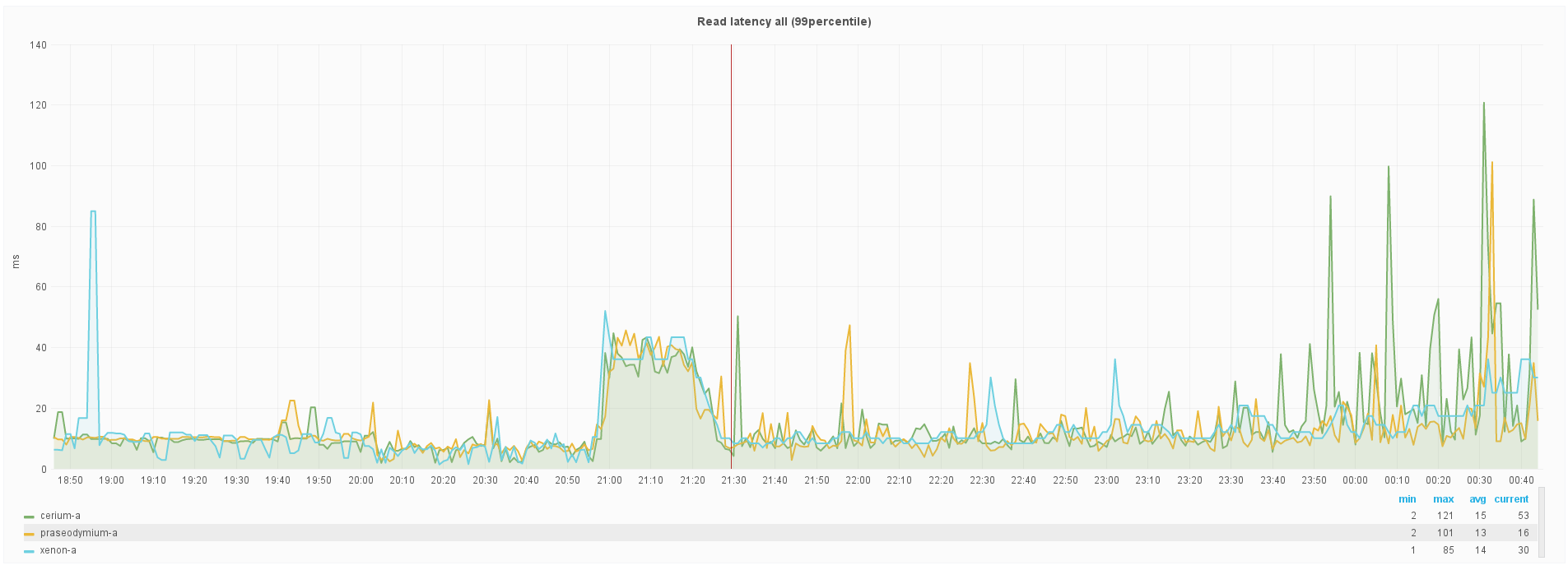
Here you can spot what looks like a bit of difference; xenon-a trends generally close to the other two nodes, but the larger spikes would seem to be smoothed out somewhat.
I'm satisfied that this is Good Enough (and others have indicated the same), so I'm closing this issue.