In the filters box at the top of the interface -- see T132352
There's an input field that allows the user to filter by WikiProject.
- The default state (empty WikiProject filters) is to show all open cases.
- The user can start typing in the input field; this opens an autocomplete list of existing WikiProjects.
- Choosing a WikiProject adds a bubble with the project name to the filters.
- Multiple WikiProjects can be in the filter at the same time; this loads cases that are either in one WikiProject or the other, or both.
- Clicking on an X for a WikiProject bubble deletes it from the list.
- Clicking Submit refreshes the list showing only the items that belong to the chosen WikiProjects.
Additionally: The WikiProject bubbles in the item listings are clickable. When the user clicks on a WP bubble, it opens a new tab, where the filter is set to All open cases, with the selected WikiProject active.
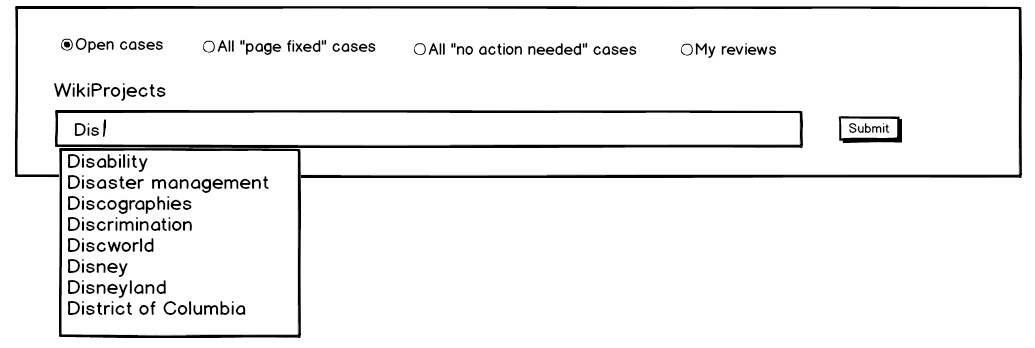

Note: We talked about whether the autocomplete list should include all WikiProjects, or only the WikiProjects appearing on currently open cases. We decided that it should include all of them, because it would feel broken if you tried typing a WikiProject name and it didn't show up in the autocomplete. On the other hand, if it does appear and then gives zero results, you have a complete understanding of what happened.