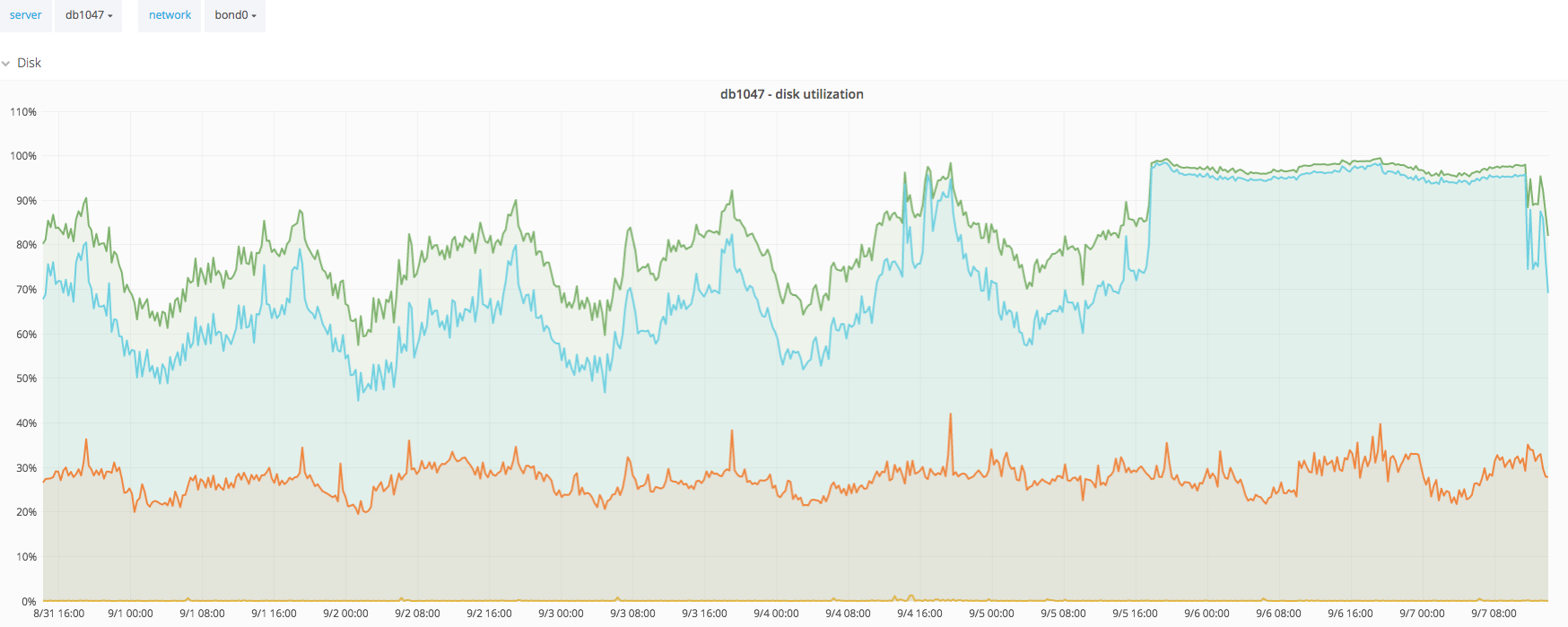
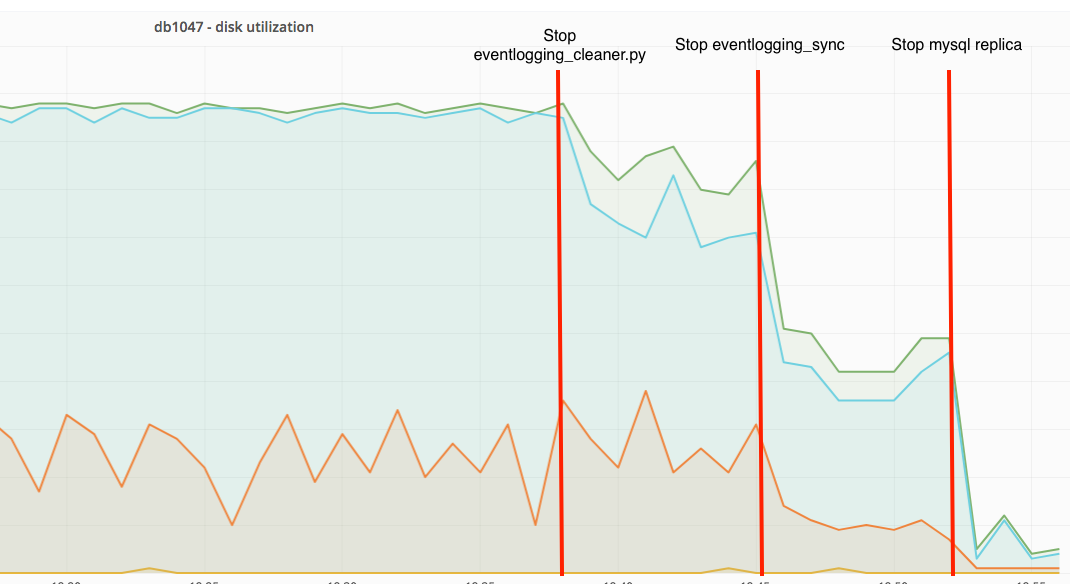
Temporary solution until we move backend away from MySQL
Purging policy defined in [1].
NOTE: pause the replication from production while this is running.
[1] https://gerrit.wikimedia.org/r/#/c/298721/5/files/mariadb/eventlogging_purging_whitelist.tsv