cvgnfg
Description
Description
Related Objects
Related Objects
Event Timeline
Comment Actions
A few things I found:
- It seems the number of unique IPs that visited /wiki/XHamster is significantly less than articles that received around the same number of pageviews.
- The top referrals aren't what'd you expect (duckduckgo.com, among others). This sort of makes sense due to the nature of what XHamster is, but I still would think Google and other major search engines would trump duckduckgo.
- The top city where most traffic came from is "unknown", when normally (in my brief time of working with the data on Hive) I see actual cities as the top 3 to 5 results.
- I'm normally able to identify false positives because most traffic originates from a single city. Here again it is "other", but even the second most popular one isn't significantly less than "other", as I would expect for a false positive. Most of the top cities that are shown however don't use English as their official language, inconsistent with what I see for other articles on enwiki.
- Some 95%+ of traffic is from mobile web. For top-ranked articles, we normally see between 20% and 70% mobile viewership.
I am leaning towards the theory that XHamster is intentionally using bots of sorts to scrape their Wikipedia page for SEO purposes. (NSFW): For instance, use Google to search for XHamster and note the WP article is the second result. Compare the ranking of the WP article when searching for other similar sites. The graph as linked in the description shows clearly something happened on January 8, 2016, after which XHamster consistently stays at drasticly higher numbers than we would expect.
Comment Actions
Interesting research!
I am leaning towards the theory that XHamster is intentionally using bots of sorts to scrape their Wikipedia page for SEO purposes. (NSFW): For instance, use Google to search for XHamster and note the WP article is the second result. Compare the ranking of the WP article when searching for other similar sites. The graph as linked in the description shows clearly something happened on January 8, 2016, after which XHamster consistently stays at drasticly higher numbers than we would expect.
What would be the SEO benefit of scraping the page?
Comment Actions
What would be the SEO benefit of scraping the page?
eh... traffic, of course, as a result of better positioning on search.
Comment Actions
Yeah you've got me why article promotion is so important to them, but it seems to be inline with why people spam Wikipedia all the time. Search engines have heuristics that look at traffic/number of incoming links to a site (Wikipedia), and that increases the ranking of sites that are linked on that page (XHamster), etc., or at least that's my understanding. So not just searching for "XHamster", which search engines would obviously put the actual site at the top, but rather the search terms in the article, in this case more general pornographic terms.
Looking more into the referrals, I checked similar sites and the top referrals are inconsistent. Some show Duckduckgo at the top, others show Google at the top and Duckduckgo isn't even in the top 50, which is more commonly the case. However all that I checked have high-ranking referrals from non-English speaking countries, and also the top city is "unknown" followed by foreign cities – so maybe we should ignore that aspect. This may be common for articles on this type of subject. You have to remember search engine users may click on the Wikipedia article, perhaps inadvertently, when seeking adult content. That certainly doesn't explain the overall high-ranking of the XHamster article, but it may explain the foreign referrals/cities in countries where Wikipedia is not as well known.
Comment Actions
Are you saying that Google use our pageview numbers as a search result ranking signal? That would be huge and surprising news which should be more widely known. What is the source for this?
Usually spammers try to edit articles to insert links.
Search engines have heuristics that look at traffic/number of incoming links to a site (Wikipedia), and that increases the ranking of sites that are linked on that page (XHamster), etc., or at least that's my understanding. So not just searching for "XHamster", which search engines would obviously put the actual site at the top, but rather the search terms in the article, in this case more general pornographic terms.
Yes, see e.g. https://en.wikipedia.org/wiki/PageRank . But links to a page are not the same a the number of times a page was "scraped", so I still don't understand the hypothesis here.
Or do you mean that they try to use bots to simulate clickthroughs from (e.g.) Google's search result page to the article? That's indeed something that Google tracks (on their own site) and reportedly uses as a signal. But one would imagine that Google is pretty good at detecting and mitigating that kind of fraudulent SEO attempt.
Looking more into the referrals, I checked similar sites and the top referrals are inconsistent. Some show Duckduckgo at the top, others show Google at the top and Duckduckgo isn't even in the top 50, which is more commonly the case.
What is the overall percentage of externally referred pageviews? Is it higher than normal?
Comment Actions
You clearly are more knowledgeable on the subject of SEO, and yes it would seem merely scraping the page isn't going to help them. Why do bots ever scrape pages hundreds of thousands of times in one day, though? Maybe they think it helps with SEO? I sort of did :) Or maybe they are aware there is a system of ranking articles on Wikipedia by pageviews, and they can exploit this by automating page loads. The benefit there seems insignificant, as https://top.hatnote.com and https://tools.wmflabs.org/topviews, among others, aren't enormously popular outside the Wikimedia community. Who knows...
What is the overall percentage of externally referred pageviews? Is it higher than normal?
On a select day, XHamster received all of 2 internal referrals, versus 542 external referrals. I checked the same day for Pornhub, a similar site that is not experiencing an unusual spike in pageviews, and it received 3 internal referrals versus 805 external. Nothing seems too out of place there, but I am not sure what the averages are across all pages.
Comment Actions
Are you saying that Google use our pageview numbers as a search result ranking signal? That would be huge and surprising news which should be more widely known. What is the source for this?
not sure how you got that...
Let me explain: more traffic means more links to your wikipedia page from any page where traffic is reported on our end (like https://en.wikipedia.org/wiki/Wikipedia:Top_25_Report). That is clearly valuable on its own for SEO as wikipedia already has a high google page rank and links on high-rated sites are valuable for SEO. In this case those links are to your wikipedia page, not to your site but links to your site are already on this page with higher value. Seems a way to try to game the system, whether it is really successful I couldn't say for sure.
Comment Actions
...
What is the overall percentage of externally referred pageviews? Is it higher than normal?
On a select day, XHamster received all of 2 internal referrals, versus 542 external referrals. I checked the same day for Pornhub, a similar site that is not experiencing an unusual spike in pageviews, and it received 3 internal referrals versus 805 external. Nothing seems too out of place there, but I am not sure what the averages are across all pages.
I meant the percentage of external referrals among total pageviews rather than the ratio of external vs internal referrals, but in any case these numbers are interesting and seem to tell us that the abnormal pageviews in this case are not caused by external referrals. That would bury the "simulated clickthroughs SEO" hypothesis.
Thanks for clarifying. But that too seems like a very contrived hypothesis, not least considering that https://en.wikipedia.org/wiki/Wikipedia:Top_25_Report has afaics never linked to the XHamster article. We would need to assume a SEO bot operator who is cunning enough to know about this internal Wikipedia page, but at the same time dumb enough not to notice, even after many months, that their page is being filtered out there.
Comment Actions
I ran a query [1] for the most frequent user agents on this page for yesterday, and 43 of the top 50 contained "Safari/534.30" and "Android". Per https://developer.chrome.com/multidevice/user-agent , this indicates the WebView component of older Android versions (up to or before KitKat/4.4). So another hypothesis might be a widely used Android app that is hardcoded to display this Wikipedia article inside the app.
Overall, 82.6% of pageviews to this page had an user agent containing "Safari/534.30" yesterday.[2] I didn't check for other versions of WebView.
[1]
SELECT user_agent, COUNT(*) AS views FROM wmf.webrequest WHERE year = 2017 AND month = 2 AND day = 16 AND pageview_info['page_title'] = 'XHamster' AND agent_type = 'user' AND is_pageview = TRUE AND normalized_host.project = 'en' AND normalized_host.project_class = 'wikipedia' GROUP BY user_agent ORDER BY views DESC LIMIT 50;
[2]
SELECT SUM(IF(user_agent LIKE '%Safari/534.30%', 1, 0))/SUM(1) AS webview_percentage FROM wmf.webrequest WHERE year = 2017 AND month = 2 AND day = 16 AND pageview_info['page_title'] = 'XHamster' AND agent_type = 'user' AND is_pageview = TRUE AND normalized_host.project = 'en' AND normalized_host.project_class = 'wikipedia'; webview_percentage 0.8263699167844245 1 row selected (338.271 seconds)
Comment Actions
For the record, http://top.hatnote.com is fairly popular, more popular than my own Topviews anyway, and I've seen both show up as referrals for XHamster. I've now hidden it from Topviews based on my own research, as I think we can at least conclude the bulk of pageviews are not legitimately human. It is still included in Hatnote's reports, however.
Comment Actions
We would need to assume a SEO bot operator who is cunning enough to know about this internal Wikipedia page,
No, sorry, you missunderstood. That was just an example. "Any" page from a domain with a somewhat high page rank that links to Wikipedia's XHamster page works. It's the page rank of the site that holds the links, not the page itself what matters. In this case any of our own reports about traffic (if they were to link to xhamster). Now, again, the traffic we are seeing might have no motive and might be just spam.
Comment Actions
Traffic starts getting significantly higher from 1/8/2016 onwards
Xhamster blog has loads of stats as of their traffic: https://xhamster.com/blog but couldn't find anything that might be related to this, now, given their usage numbers I doubt they are intentionally crawling wikipedia, their numbers are pretty amazing and look pretty legit given their detailed reporting and the fact they are ~80 in Alexa. They report traffic stats at end of the year.
Looking at UAs I do see (all?) pageviews come from mobile devices, which certainly indicates an app. Mostly Android 4 but 2 and 5 also appear. Tabs and phones.
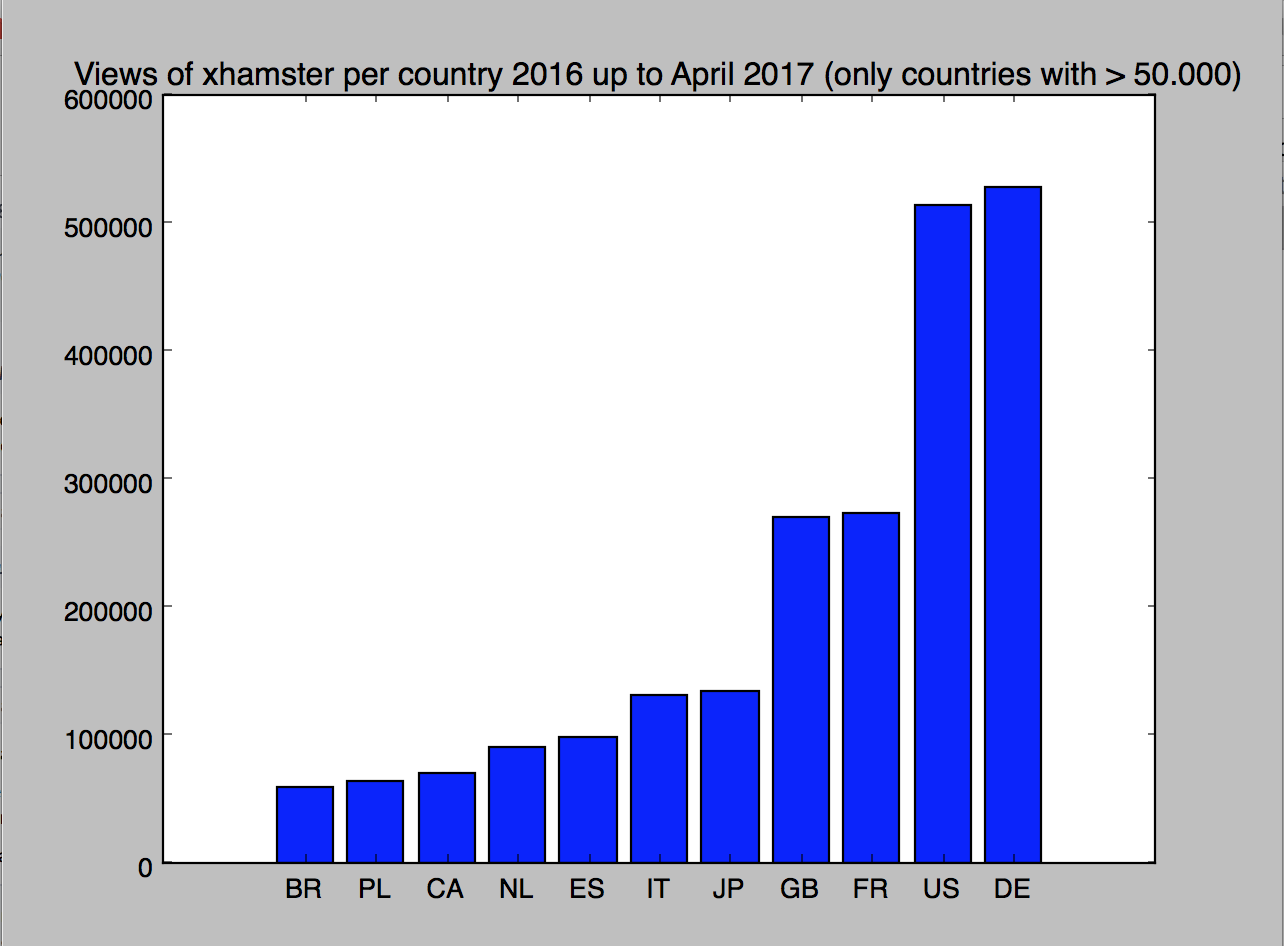
Comment Actions
Android Samsung tablets from EU countries and US make the bulk of pageviews on 2016 and 2017 . There is not even desktop browsers on the top 10 uas that browsed that site , Chrome appears sparingly on a top 100 per browser per country.
This has all the looks of a mobile app that loads wikipedia xhamster page but also xhamster content, traffic (given the variety of mobile uas) looks pretty legit
Comment Actions
It seems the number of unique IPs that visited /wiki/XHamster is significantly less than articles that received around the same number of pageviews.
Not sure what was the interval you looked at but number of cities seems pretty spread out in both Germany and US. Overall numbers for DE for more than 500 views (2016 and 2017). Bucket of Unknown is large
584 Siegen
586 Viersen
588 Zwickau
610 Düren
613 Fulda
620 Herford
622 Albstadt
625 Cottbus
626 Bayreuth
629 Gütersloh
635 Erkrath
636 Iserlohn
639 Wolfsburg
652 Gera
663 Eschweiler
667 Flensburg
669 Hilden
674 Celle
685 Lünen
707 Villingen-Schwenningen
709 Altena
709 Hanau
713 Salzgitter
714 Bottrop
716 Leverkusen
719 Reutlingen
753 Jena
753 Pforzheim
776 Oberursel
796 Heilbronn
804 Giessen
822 Göttingen
829 Mülheim
887 Erlangen
897 Aurich
911 Recklinghausen
973 Langenfeld
992 Witten
1002 Wurzburg
1017 Bremerhaven
1027 Neuss
1043 Trier
1050 Solingen
1060 Heidelberg
1112 Hamm
1129 Fürth
1139 Regensburg
1147 Koblenz
1149 Rostock
1205 Ludwigsburg
1261 Hagen
1301 Paderborn
1313 Ludwigshafen
1364 Herne
1421 Ulm
1447 Aachen
1454 Lübeck
1481 Kaiserslautern
1550 Saarbrücken
1597 Freiburg
1675 Darmstadt
1711 Krefeld
1813 Wiesbaden
1816 Mönchengladbach
1900 Chemnitz
1976 Mainz
1996 Gelsenkirchen
2023 Magdeburg
2058 Augsburg
2117 Braunschweig
2118 Kassel
2124 Oberhausen
2281 Erfurt
2414 Halle
2489 Münster
2662 Oldenburg
2663 Kiel
2863 Osnabrück
3024 Karlsruhe
3147 Mannheim
3205 Wuppertal
3748 Bochum
3911 Bielefeld
4312 Duisburg
5518 Dresden
5912 Bonn
5965 Bremen
5988 Leipzig
6340 Essen
6521 Nuremberg
6649 Dortmund
6853 Dusseldorf
7097 Hanover
7944 Stuttgart
9962 Cologne
13759 Munich
14222 Frankfurt
20890 Hamburg
31041 Berlin
72146 Unknown
Comment Actions
Maybe wikipedia page is the "launching" pad for some popular video? I could not find anything obvious on citations and such.
Closing as there is nothing here that points to a bot, rather traffic seems organic
Comment Actions
I used this query to get the number of unique IPs for a given page, in this case on March 10:
SELECT COUNT(DISTINCT ip) AS hits FROM webrequest WHERE year = 2017 AND month = 3 AND day = 10 AND uri_host = "en.wikipedia.org" AND http_status = 200 AND uri_path = "/wiki/Page_title";
Here are some figures using that query:
| Page | Rank | Unique IPs | Pageviews |
| XHamster | 10 | 3532 | 118612 |
| Get_Out_(film) | 12 | 27780 | 106859 |
| Park_Geun-hye | 15 | 47839 | 100714 |
| Nintendo_Switch | 128 | 11499 | 25694 |
| Pornhub | 361 | 3689 | 16116 |
| Paul_Ryan | 363 | 5734 | 16086 |
As you can see XHamster has a very low unique IP count compared to other popular pages. Even Nintendo Switch, which is ranked way down at 128, has over three times as many. Maybe it's wrong to assume any page in top 20 or so should have a high unique IP count, but it seems crazy to me that on a single day, only ~3500 unique IPs viewed XHamster, yet the total pageviews were over 118,000.
I included figures for Pornhub too, since it's a similar site. Here we also have a lower number of unique IPs, but Pornhub ranked 357 and only got ~16,000 pageviews, so the ratio is very different. I do find it interesting Paul Ryan (surely genuine traffic), has more unique IPs but is ranked lower by pageviews. Maybe Pornhub is just less popular than XHamster, and the anomaly of low unique IPs is simply because we have a finite pool of people who end up on Wikipedia when trying to go to these adult sites?
Comment Actions
Maybe it's wrong to assume any page in top 20 or so should have a high unique IP count, but it seems crazy to me that on a single day, only ~3500 unique IPs viewed XHamster, yet the total pageviews were over 118,000.
I can take another look but assuming this in general is certainly not correct, specially if all traffic is mobile (not wi-fi), NAT-ing in mobile makes many users appear under the same IP , for example all vodafone users in SF might have the same IP.
https://en.wikipedia.org/wiki/Network_address_translation
Comment Actions
Took another look and used (for comparison) the page "13 reasons why" which has more traffic but still within the same order of magnitude in mobile. Looking at an hour of traffic definitely the XHamster IPs are skewed. For most ips the number of requests in an hour is <30 for page "13 reasons why". For 'xHamster' this is true too with the notable exception of couple ips that have hundreds of requests. Most notably and IP located in paris ({"city":"Paris","country_code":"FR",,"subdivision":"Île-de-France","timezone":"Europe/Paris","continent":"Europe","country":"France"}) this (according to whois) is some kind of hosting site: s2.lealhost.com, most likely a proxy of some sort that serves as the umbrella for all that traffic. However, the difference per hour is not huge, 1 order of magnitude (10 versus a 100) so while this share of traffic could be automated the "bulk" of XHamster traffic seems organic.


Comment Actions
We talked on IRC, but I'll also thank you here for the thorough analysis! I am going to keep XHamster excluded in Topviews even though traffic appears to be primarily organic, as I don't think most of the traffic is intentional. Surely we want the API to report anything that was human, regardless of how or why they got to the article, so I guess sometimes it's up to the client to make the decision on whether they want to surface it.
Additionally or as a supplement to hand-written annotations (T142408), we might consider introducing a system of unique codes or keywords that indicate specific things about the data. In this case, it might suggest the data is organic, but the bulk of it is questionably "intentional" traffic. This I'm sure happens a lot, hence why some reusable and machine-readable code system might be beneficial so we can automate treatment of the data on the client-side.