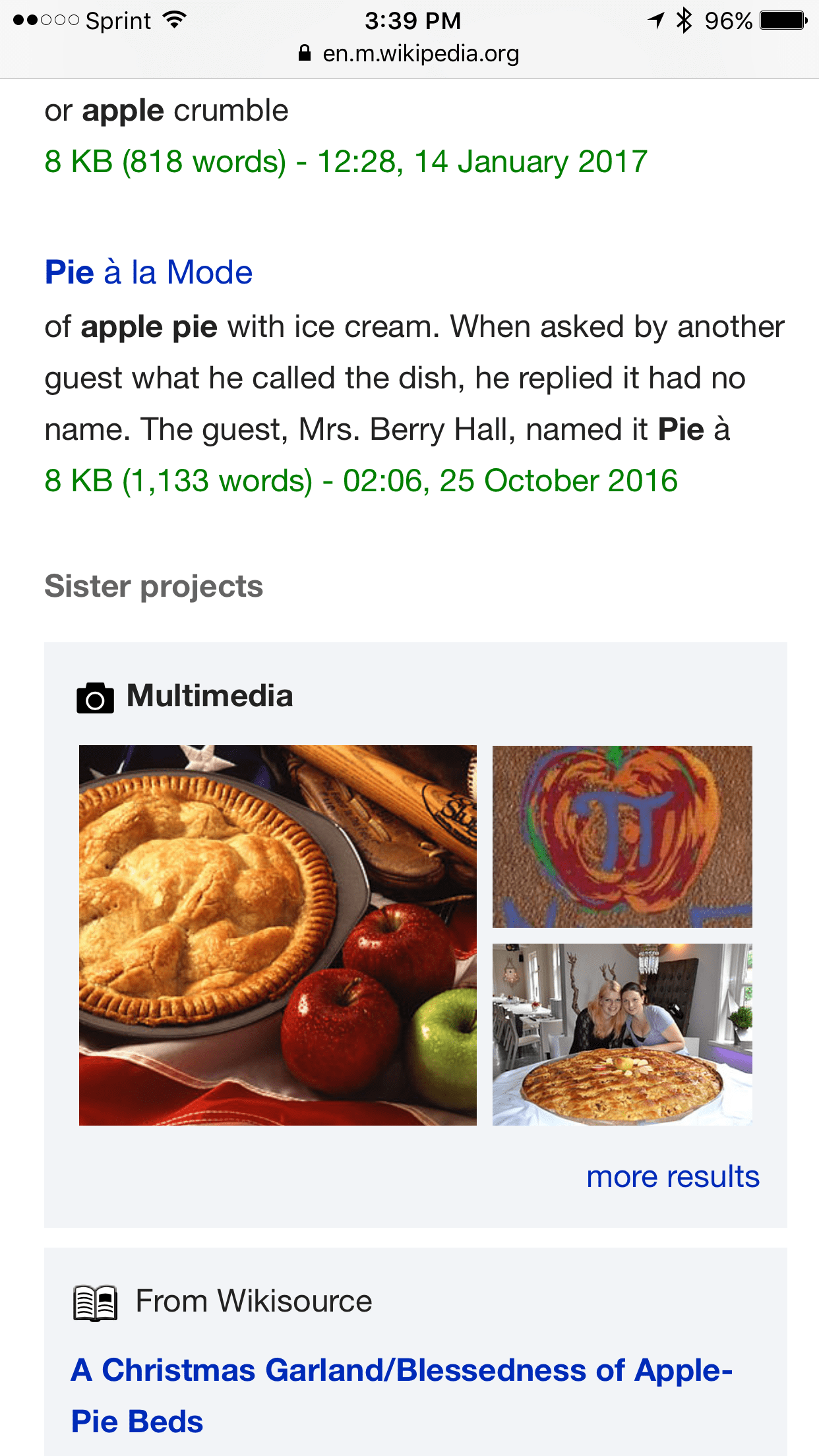
Based on the results from T149806 (see: T156300), this second A/B test for displaying sister project search results in a sidebar will have just one test group (displaying the project results based on recall) and one control group. Since the test results showed that we didn't get enough clickthroughs - mostly based on two bugs (T158935 and T158937) and the fact that the zero results rate for the queries entered on the original 4 wikis was higher than average - we decided to add in 4 additional wikipedias to be tested in this round.
This test is expected to last at least a week and will be run on the following wikipedias:
- Persian (tested in T149806)
- Italian (tested in T149806)
- Catalan (tested in T149806)
- Polish (tested in T149806)
- Arabic
- French
- German
- Russian
Test group users will see:
- additional search results from sister wikis in a right sidebar
- each result for the sister wiki(s) will display:
- the top ranked result from any wiki that contain relative search results
- an icon that denotes which wiki the result is from
- article name of the search result
- description of the search result
- typical bolding of the search result term(s)
- link below the search result that is labeled 'more results'
- this link will open a new browser tab and display a search results page for the original search term on that sister wiki
- separate section for multimedia results above the other sister wiki results
- up to 3 images will be displayed that are relevant to the original search term
- display a link that will open a new browser tab and display a search results page of multimedia for the original search term from the native wikipedia that the user is on
- for example, if a user searched for 'gutenberg' on English Wikipedia, and clicked on the more multimedia link, the user will be displayed search results for multimedia for 'gutenberg' on English Wikipedia in a new tab.
Order of projects will be based on recall - most to least number of articles returned from each project
- results from Commons will always be displayed first
- Wikispecies will most likely not be included in this test cycle
Bucket testing logic generally is as follows:
- 1 in 200 users are included in EventLogging
- Of those 1 in 200 users, 1 in 10 are included in the test
- Of those 1 in 10 users
- 1/2 will go in a test group, labeled "recall_sidebar_results"
- the remaining 1/2 of users will go in a control group, labeled "no_sidebar"
- The remaining chunk of the original bucketed 200 users will get a NULL (the string null, or the MySQL null, we can detect either).
Eventlogging needs to capture:
- if the user clicked on an individual result and what wiki project that result came from
- what position in the list was the selected result
- if the user clicked on the 'more from' on any wiki project result that was displayed
- important to compare control group that has sister wiki results vs test group that also has sister wiki results
Eventlogging data will be joined against CirrusSearchRequestSet logging to capture:
- if results were shown and from which wiki projects
Notes to take into account:
- for those wikis (it, ca) that aren't selected in the bucketing, we'll need to show the existing sister wiki search results.
Sample urls of what this test could look like on the newly added wikipedias to test:
- de: https://de.wikipedia.org/wiki/Special:Search?search=regenbogen&fulltext=1&cirrusUserTesting=recall_sidebar_results&searchToken=aiwxd5mpr0r33pcn3fevn363j#regenbogen
- fr: https://fr.wikipedia.org/wiki/Special:Search?search=arc+en+ciel&fulltext=1&cirrusUserTesting=recall_sidebar_results&searchToken=6icx5hguf1qluixan4behr6zr#arc+en+ciel
- ar: https://ar.wikipedia.org/wiki/Special:Search?search=%D9%82%D9%88%D8%B3+%D8%A7%D9%84%D9%85%D8%B7%D8%B1&fulltext=1&cirrusUserTesting=recall_sidebar_results&searchToken=dwsezgjbl1oy2ylnosyiyvpld#%D9%82%D9%88%D8%B3+%D8%A7%D9%84%D9%85%D8%B7%D8%B1
- ru: https://ru.wikipedia.org/wiki/Special:Search?search=%D1%80%D0%B0%D0%B4%D1%83%D0%B3%D0%B0&fulltext=1&cirrusUserTesting=recall_sidebar_results&searchToken=cczita0zg97erxjpf2ozgfvgy#%D1%80%D0%B0%D0%B4%D1%83%D0%B3%D0%B0