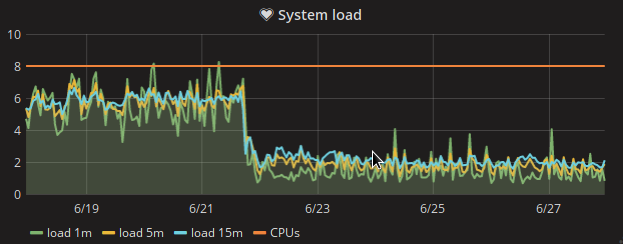
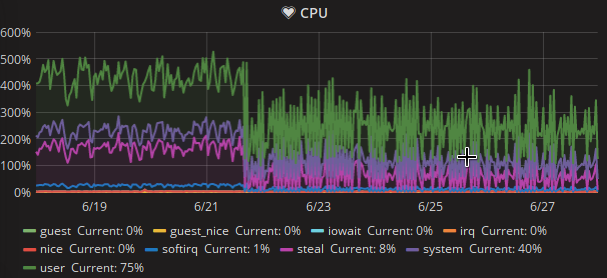
The beta cluster swift backend instances show high load and system CPU usage. There must be something wrong with them.
Symptoms
| Jessie / new | |
|---|---|
| deployment-ms-be03.deployment-prep | Prometheus 1 days |
| deployment-ms-be04.deployment-prep | Prometheus 1 days |
Load:
deployment-ms-be03.deployment-prep.eqiad.wmflabs: 08:54:01 up 12 days, 19:40, 0 users, load average: 5.27, 3.87, 3.67 deployment-ms-be04.deployment-prep.eqiad.wmflabs: 08:54:20 up 12 days, 21:11, 0 users, load average: 7.59, 6.35, 5.61
Maybe the Swift services have to many workers for the labs instances?
deployment-ms-be01.deployment-prep.eqiad.wmflabs:
/etc/swift/account-server.conf:workers = 8
/etc/swift/container-server.conf:workers = 8
/etc/swift/object-server.conf:workers = 100
deployment-ms-be02.deployment-prep.eqiad.wmflabs:
/etc/swift/account-server.conf:workers = 8
/etc/swift/container-server.conf:workers = 8
/etc/swift/object-server.conf:workers = 100Fix candidates
The summary:
- number of containers
There tis ~ 20k containers which causes the replicator to issue a lot of stat() calls and similar. A low hanging fruit are the -deleted ones 1296 containers per wiki.
That is controlled from MediaWiki config which uses a shard level of 2 pretty much everywhere with the exception of $wgLocalFileRepo which uses 3 levels for deleted files:
$wgLocalFileRepo = [ 'class' => 'LocalRepo', 'name' => 'local', 'backend' => 'local-multiwrite', 'url' => $wgUploadBaseUrl ? $wgUploadBaseUrl . $wgUploadPath : $wgUploadPath, 'scriptDirUrl' => $wgScriptPath, 'hashLevels' => 2, ... 'deletedHashLevels' => 3, ... ];
On beta it would be nice to lower it to two. Question is do we have a way to migrate containers? Then given it is beta and they are just deleted files, we can probably just delete them all.
- lower replication passes
Running the replication less often would help. There is a puppet patch to let us tweak Swift configs via hiera and on beta change the interval between pass to 300 seconds with only 1 concurrent process. That is applied on beta and nicely reduced the load. https://gerrit.wikimedia.org/r/344387
- migrate Swift to Jessie
On beta the three Swift instances are on Ubuntu Trusty when production has switched to Jessie. That has to be done eventually and might bring in optimization in the replication pass. Filled T162247
- instances on different labvirt
Both ms-be instances are on the same labvirt. T161083 Though if we create Jessie instances they will most probably end up on different labvirt.
- nscd eating CPU
gethostbyname('localhost') is not cached by nscd and causes lot of disk access. The lookups come from statsd metrics. Worked around on beta by disabling statsd entirely.
Potential fix is to use 127.0.0.1 https://gerrit.wikimedia.org/r/#/c/358799/