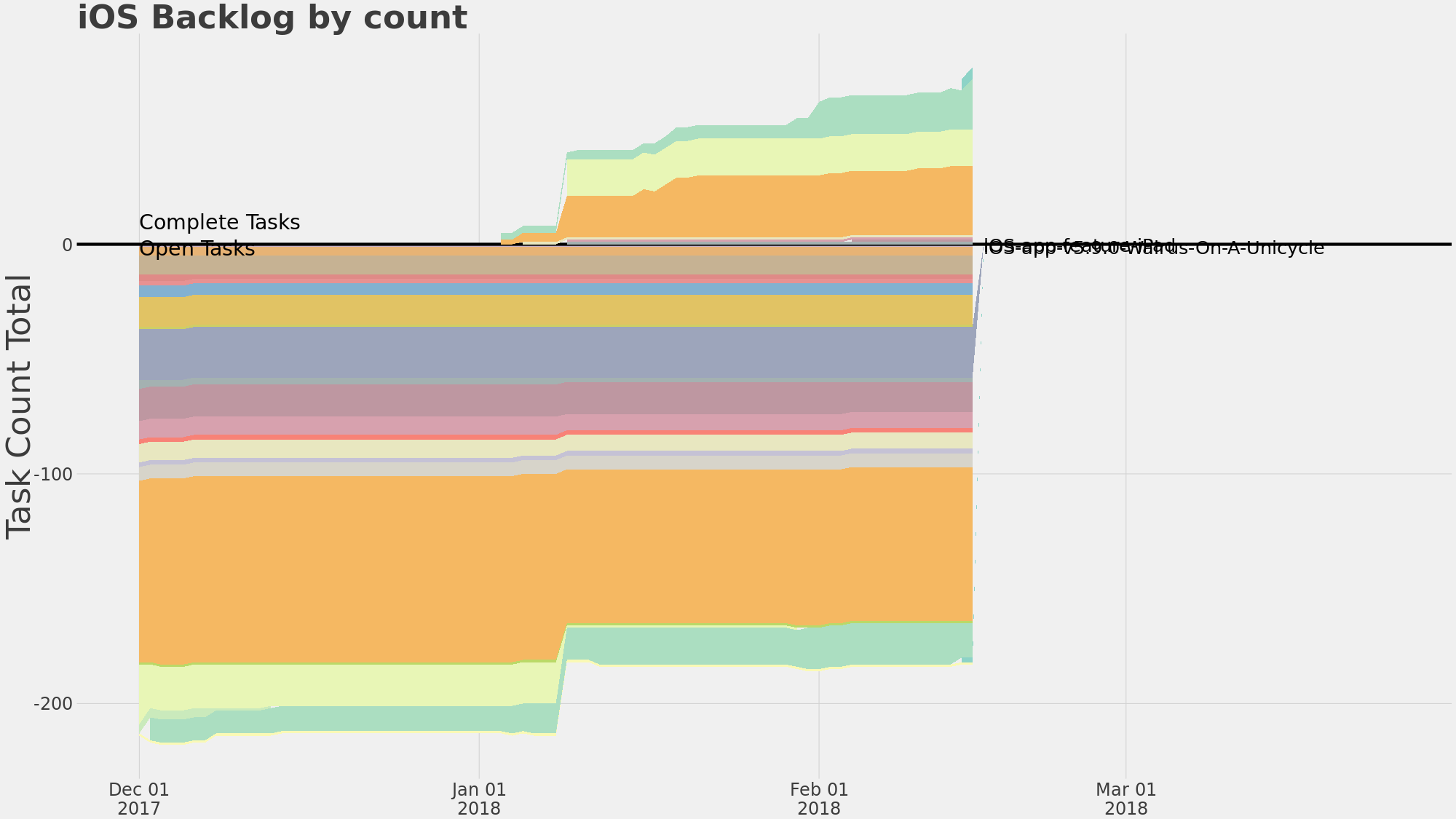
Phlogiston task data truncates around Feb 15th, although there are a few lines suggesting a few tasks remain. This happens with all projects I have sampled.
| • JAufrecht | |
| Feb 23 2018, 10:18 PM |
| F15413120: Screen Shot 2018-03-14 at 9.40.49 AM.png | |
| Mar 14 2018, 4:46 PM |
| F15413236: Screen Shot 2018-03-14 at 9.44.36 AM.png | |
| Mar 14 2018, 4:46 PM |
| F13976264: image.png | |
| Feb 23 2018, 10:18 PM |
Phlogiston task data truncates around Feb 15th, although there are a few lines suggesting a few tasks remain. This happens with all projects I have sampled.
A preliminary inspection suggests that the dumps are still coming, still fresh, but missing all edges (aka which tasks belong to which project). While I investigate further, a question: Did anything change in the dumps around Feb 15th?
I also checked in new code on Feb 15, which is a superficial clue. I will continue investigating. Do you think the schema change affected the dumps?
Have dug in deeper; pretty sure this is a change in the data files provided to Phlogiston, and not a code problem introduced recently in Phlogiston alone.
@JAufrecht I think you are probably right, I'm looking at the schema changes and I will update the dump. Hopefully nothing will need to be done on your end.
So, after much digging I wasn't able to find any changes to edges, however, it appears that the dump stops after the 99999th task. I can't figure out why it would stop just short of 100,000, the code hasn't changed and there isn't any limit on the query.
I still see 179180 tasks in the dump, which is presumably all of the public tasks. What does seem to be missing in the dumps is some, but not all, of the core:edge transaction content. For the missing ones, there's still a record for the transaction, but the content of the transaction is missing. I haven't spotted other things specifically missing from the dump yet.
What exactly is stopping at 99,999?
The keys of the task objects, which are not phids but rather based on the actual id field in the database. The last one is 99999
Where to see the problem?
Screenshot says "iOS Backlog by count" but "iOS" link on http://phlogiston.wmflabs.org/ going to http://phlogiston.wmflabs.org/ios_report.html says 404.
Random assumptions on what we're talking about:
Latest dump includes T188473 as last entry (poor man's check via less phabricator_public.dump | tail -c 5000) which seems up to date?
All of the current reports are failing every day because they basically have no data and Phlogiston (or R) doesn't have enough error handling to continue functioning. The chart above was captured two weeks after the apparent change but before Phlogiston gave up; you can see that the task counts dropped from ~300 to maybe two or three tasks. When I reported the task count of 179,180, that was a literal count of objects (
len[data]['task']
) so there are still >100,000 tasks in the dump, but most of the edge data seems to be missing. It's hard to be more precise because I don't have a "before" dump handy, but the first thing that caused Phlogiston to outright crash was that some of the transactional core:edge data started showing up empty. Is that helpful or should I try to provide more precise information about what's missing in the dump?
Any more information would be welcome. I haven't had a lot of time to work on this but so far no luck tracking down the cause.
Upstream seems to be working on burndown charts, finally: https://secure.phabricator.com/T13083
What kind of information would be helpful? I could examine the dump file to give more information over what's above. I could look to see how the apparent 100,000 cutoff manifests in the dump. I could try to define a filter that would cut the number of tasks for reporting below 100,000 to see if the problem then (temporarily) goes away.
See T188149#4010091 - clear steps that allow someone else to see the problem, to start with.
In T188149#4049142, @Aklapper wrote:
See T188149#4010091 - clear steps that allow someone else to see the problem, to start with.
I was going to try to provide these steps, but now the tool seems to have gone missing alltogether. So here is the best I can do in terms of a step-by-step.
Expected result: see the Collaboration Team Phlogiston report.
Actual result: 404 message. See below.
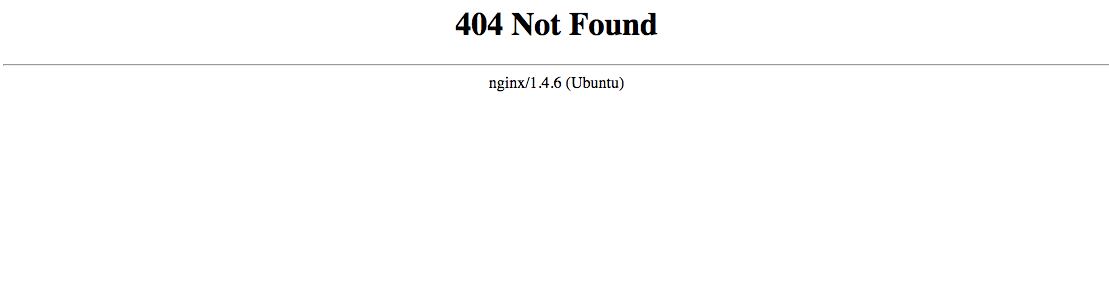
[trying alternate address for reports on Dev.]
Expected result: see link the Collaboration Team Phlogiston report on Dev
Actual result: notice that the link says "no data" see below [I clicked on the link anyway, and got the same 404 message]
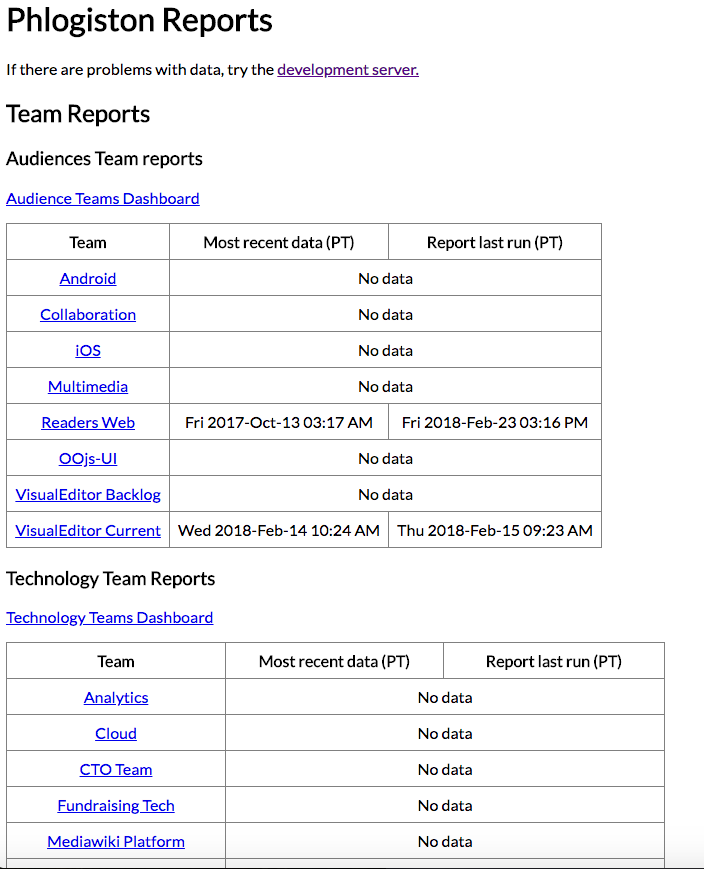
Steps to Reproduce:
Actual Results
load 2018-03-14 04:24:17: Dump file load starting load 2018-03-14 04:24:52: 3289 projects loading load 2018-03-14 04:24:55: 11257 columns loading load 2018-03-14 04:25:04: Tasks, transactions, and edges for 180436 tasks loading Data error for transaction PHID-XACT-TASK-j4goxjs7ynylrym: no keys. Skipping. Data error for transaction PHID-XACT-TASK-z2fmfhdfiu74ctr: no keys. Skipping.
followed by thousands more data errors.
The data errors are cases where the transaction data in the dump is incomplete. These are all new problems since circa Feb 15th, because the initial manifestation of this problem was crashes loading the dump, because Phlogiston had no error handling for this case. An example of a successfully loaded edge transaction is:
success. jblob {'PHID-PROJ-osuk4au5ksi6kl66jvk5': {'seq': '1', 'dst': 'PHID-PROJ-osuk4au5ksi6kl66jvk5', 'dateCreated': '1477920002', 'src': 'PHID-TASK-ze5vxql56rz3woisdco7', 'type': '41', 'dataID': None, 'data': []}, 'PHID-PROJ-2olj6ckxwlzq3akoznah': {'seq': '0', 'dst': 'PHID-PROJ-2olj6ckxwlzq3akoznah', 'dateCreated': '1477920002', 'src': 'PHID-TASK-ze5vxql56rz3woisdco7', 'type': '41', 'dataID': None, 'data': []}, 'PHID-PROJ-noxukdupa22qjuzcwtwe': {'seq': '0', 'dst': 'PHID-PROJ-noxukdupa22qjuzcwtwe', 'dateCreated': '1477517432', 'src': 'PHID-TASK-ze5vxql56rz3woisdco7', 'type': '41', 'dataID': None, 'data': []}, 'PHID-PROJ-k73rs2d4jrtxacicze62': {'type': 41, 'dst': 'PHID-PROJ-k73rs2d4jrtxacicze62', 'data': []}}An example of an unsuccessfully loaded edge transaction is:
Data error for transaction PHID-XACT-TASK-edgy64kb4aup3tw: no keys. jblob ['PHID-PROJ-onnxucoedheq3jevknyr'] Skipping.
So the change in the dump is that it now contains many transaction rows that claim to be core:edge transactions but don't describe what the actual transaction is. Thus Phlogiston cannot recreate all of the data, and produces empty charts or crashes altogether from too much missing data (and not enough error handling).
Expected Results
Grep'ing for no keys I cannot find any match in https://phabricator.wikimedia.org/diffusion/PHTO/browse/master/public_task_dump.py or https://phabricator.wikimedia.org/diffusion/PHTO/browse/master/wmfphablib/phabdb.py or the Phlogiston code base (phlogiston.py only offers print("Data error for transaction {0}: project {1} doesn't exist.).
Any idea where that error string is triggered / comes from?
To clarify, is that the case? If some dump contains any core:edge transactions without transactional data, can you please point both to that dump (full URL) and provide some string that allows findinf a core:edge transaction without transactional data? (Trying to isolate on which level the problem might occur.)
You probably can't find it in the code because ... it's temporary error-handling code that I added to the dev server and never committed. On production, the load log looks like:
Thu Mar 15 04:24:41 UTC 2018: Loading loading new Phabricator dump
load 2018-03-15 04:24:41: Dump file load starting
load 2018-03-15 04:25:13: 3291 projects loading
load 2018-03-15 04:25:16: 11267 columns loading
load 2018-03-15 04:25:29: Tasks, transactions, and edges for 180545 tasks loading
Traceback (most recent call last):
File "phlogiston.py", line 1323, in <module>
main(sys.argv[1:])
File "phlogiston.py", line 89, in main
load(conn, end_date)
File "phlogiston.py", line 331, in load
for key in jblob.keys():
AttributeError: 'list' object has no attribute 'keys'
Thu Mar 15 04:25:40 UTC 2018: Starting Incremental Reconstruction and Report for and
and 2018-03-15 04:25:40: Maniphest_edge creation for 2018-03-01
[...]I.e., it fails partway into loading the tasks, transaction, and edges, the first time it encounters invalid data. Prior to ~15 Feb 2018, this kind of invalid data had never been present, and so there was no error handling for it. I added the error handling on dev to see what would happen if it got past these problems.
331 try:
332 for key in jblob.keys():
... [...]
341 except AttributeError:
342 print("Data error for transaction {0}: no keys. jblob {1} Skipping.".format(trans[1], jblob))It happens when Phlogiston, having identified as core:edge transaction, tries to read the contents of the transaction by opening up the JSON report, aka jblob, which has been converted into a Python dictionary with key-value pairs. Prior to ~Feb 15th, this always worked because every core:edge transaction had a valid transaction detail with key-value pairs.
It appears that the dump now contains a mix of valid and invalid, or complete and incomplete, core:edge transactions. I added some extra debugging flags and identified one task that loaded properly: 185323, and a few tasks that failed, 104419 and 187512.
When I open the dump file with python:
phlogiston@phlogiston-2:~$ python3
Python 3.4.3 (default, Nov 28 2017, 16:41:13)
[GCC 4.8.4] on linux
Type "help", "copyright", "credits" or "license" for more information.
>>> import json
>>> with open('phabricator_public.dump') as dump_file:
... data = json.load(dump_file)
...Here's the good one (manually reformatted for clarity, to show that it has two transactions):
>>> data['task']['185323']['transactions']['core:edge']
[
[3912881, 'PHID-XACT-TASK-i6sqludydmqnio7', 'PHID-USER-uu7wg6g3b37dcktbje3a', 'PHID-TASK-ppt4ezi2fegfxrwxjigc', None, 0, 'core:edge', '[]', '{"PHID-PROJ-uu433qnk7xvy6nnpodlh":{"dst":"PHID-PROJ-uu433qnk7xvy6nnpodlh","data":[],"type":41},"PHID-PROJ-254n3hz7qyerb57bprmr":{"dst":"PHID-PROJ-254n3hz7qyerb57bprmr","type":41,"data":[]}}', '{"edge:type":41,"core.create":true}', 1516377684, 1516377684],
[3912927, 'PHID-XACT-TASK-qa77r3w5brlal3m', 'PHID-USER-uu7wg6g3b37dcktbje3a', 'PHID-TASK-ppt4ezi2fegfxrwxjigc', None, 0, 'core:edge', '[]', '{"PHID-TASK-zw43n4apkne7jrjhatlk":{"dst":"PHID-TASK-zw43n4apkne7jrjhatlk","type":63,"data":[]}}', '{"edge:type":63}', 1516377834, 1516377834]
]And here's a bad one (with three transactions):
>>> data['task']['187512']['transactions']['core:edge']
[
[3977357, 'PHID-XACT-TASK-go7dmtg6a57b443', 'PHID-USER-3jrdwh7dywughlcnir2i', 'PHID-TASK-t7ocrk2ed6n3bucbttkw', None, 0, 'core:edge', '[]', '["PHID-PROJ-z6v7akk2req5sbx6kce2","PHID-PROJ-cw6k77w75kdfiwipwded","PHID-PROJ-j4il3hvghvfwqapen7xd"]', '{"edge:type":41,"core.create":true}', 1518734673, 1518734673],
[3977367, 'PHID-XACT-TASK-zr3a2hm4y6pkb27', 'PHID-USER-idceizaw6elwiwm5xshb', 'PHID-TASK-t7ocrk2ed6n3bucbttkw', None, 0, 'core:edge', '[]', '["PHID-PROJ-onnxucoedheq3jevknyr"]', '{"edge:type":41}', 1518734698, 1518734698],
[3979828, 'PHID-XACT-TASK-aq7i4akrlcmp3xp', 'PHID-USER-d4t4pqg6bbnh6kksz5ox', 'PHID-TASK-t7ocrk2ed6n3bucbttkw', None, 0, 'core:edge', '[]', '["PHID-PROJ-dniq4n7xipcwfbfgrrmb"]', '{"edge:type":41}', 1518814851, 1518814851]
]Phlogiston looks specifically at the 9th field of each transaction to get the actual transaction history. For the good one:
>>> data['task']['185323']['transactions']['core:edge'][0][8]
'{"PHID-PROJ-uu433qnk7xvy6nnpodlh":{"dst":"PHID-PROJ-uu433qnk7xvy6nnpodlh","data":[],"type":41},"PHID-PROJ-254n3hz7qyerb57bprmr":{"dst":"PHID-PROJ-254n3hz7qyerb57bprmr","type":41,"data":[]}}'
>>> data['task']['185323']['transactions']['core:edge'][1][8]
'{"PHID-TASK-zw43n4apkne7jrjhatlk":{"dst":"PHID-TASK-zw43n4apkne7jrjhatlk","type":63,"data":[]}}'In this case, the first transaction's Project PHIDs translate to Technical-Museum and User-AxelPettersson_WMSE, which match what we see when we look directly at the bug in Phabricator. The second transaction is not type 41 and is ignored.
For the bad one:
>>> data['task']['187512']['transactions']['core:edge'][0][8] '["PHID-PROJ-z6v7akk2req5sbx6kce2","PHID-PROJ-cw6k77w75kdfiwipwded","PHID-PROJ-j4il3hvghvfwqapen7xd"]' >>> data['task']['187512']['transactions']['core:edge'][1][8] '["PHID-PROJ-onnxucoedheq3jevknyr"]' >>> data['task']['187512']['transactions']['core:edge'][2][8] '["PHID-PROJ-dniq4n7xipcwfbfgrrmb"]'
This is a completely different format of transaction history. To make that more obvious, here are the first transaction from each, manually formatted:
Good:
"PHID-PROJ-uu433qnk7xvy6nnpodlh":{"dst":"PHID-PROJ-uu433qnk7xvy6nnpodlh",
"data":[],
"type":41},
"PHID-PROJ-254n3hz7qyerb57bprmr":{"dst":"PHID-PROJ-254n3hz7qyerb57bprmr",
"type":41,
"data":[]}}'Bad:
"PHID-PROJ-z6v7akk2req5sbx6kce2", "PHID-PROJ-cw6k77w75kdfiwipwded", "PHID-PROJ-j4il3hvghvfwqapen7xd"
This could mean that data that used to be provided in format "good" is now provided in format "bad" and is unusable. Or it could mean that all of the good data is there and a bunch of "bad" data has been added as part of a new feature or schema change. When Phlogiston on the dev server completes the load, having skipped all "bad" transactions, it then tries to reconstruct the edge history for each task of interest. This runs instantaneously as it cannot reconstruct any edge data for any of the tasks of interest, and then it errors out, possibly as a consequence of that or possibly from a new error. This is why the Phlogiston reports are all empty.
For an experiment, I tweaked the load so that it parsed all of the "bad" transactions, treating the list of PHIDs as a list of projects the task belonged to at that date (which was true for at least the sample task 187512). Phlogiston ran to completion and generated a report on dev; I used Reading-Web as the sample:
http://phlogiston-dev.wmflabs.org/red_report.html
However, the data doesn't look especially accurate. Eyeballing the backlog chart, there seem to be well over 50 open tasks for the first category, Kanban Board (Page Previews). But there are only about 21 tasks on the Page Previews Board. And the Phlog database shows 38 open and 352 resolved, which matches neither reality nor the chart.
@JAufrecht: ah ha! Thanks to your detailed comparison, I figured out what changed: https://phabricator.wikimedia.org/T188149
Example from upstream:
New row:
*************************** 44. row *************************** id: 757 phid: PHID-XACT-PSTE-5gnaaway2vnyen5 authorPHID: PHID-USER-cvfydnwadpdj7vdon36z objectPHID: PHID-PSTE-5uj6oqv4kmhtr6ctwcq7 viewPolicy: public editPolicy: PHID-USER-cvfydnwadpdj7vdon36z commentPHID: NULL commentVersion: 0 transactionType: core:edge oldValue: [] newValue: ["PHID-PROJ-tbowhnwinujwhb346q36","PHID-PROJ-izrto7uflimduo6uw2tp"] contentSource: {"source":"web","params":[]} metadata: {"edge:type":41} dateCreated: 1450197571 dateModified: 1450197571
So the data that's missing from the 'bad' format edges ({"edge:type":41}) has been moved into it's own separate 'metadata' column. There is a tool to convert all remaining data to the 'new' format, meanwhile, newly created data is in the new format already. So the easiest way forward would be for me to migrate the remaining edges to the new format and modify the dump script to include the 'metadata' column in the transactions. Would that provide you with enough info to recreate what you need or do you need me to reconstruct the old format with the edge:type part repeated for each edge record?
If you can throw in the new column, I can modify the script to work with
either kind of data.
Actually I see now that the metadata column is already there, it's the 10th one, specifically.
For reference, the query that builds the transactions['core:edge'][] list is as follows:
SELECT id, phid, authorPHID, objectPHID, commentPHID, commentVersion, transactionType, oldValue, newValue, metadata, dateCreated, dateModified FROM maniphest_transaction WHERE objectPHID = '%s' AND transactionType = 'core:edge'
So the new format only mentions what changed instead of repeating the whole list. That's probably why your attempt to use the new style phid list didn't quite come up with data that matches reality.
With the new format, it's necessary to look at the 'oldValue' column for a list of phids removed, and the 'newValue' column for phids added. So I think the algorithm to compute the final state of a given task would be something like this:
(written in python because the dump file is created in python:)
I don't know if it would be better for to run something like this on the data before dumping it, or change Phlogiston to calculate the running phid list as it's reading the transaction log.
It's much easier to change Phlogiston than the dump, because it runs
outside of any security profile and doesn't require an admin. so I would
vote to do all that in phlogiston.
Program Manager (Technology)
Wikimedia Foundation
I believe I have it correctly importing on the dev server, handling both forms of edge transaction. A total of three transactions don't fit the pattern and I'll follow up on those separately. I am as yet unable to validate through to the end because several of the post-processing steps became 10 to 100x longer for no obvious reason, so I'm working on optimizing again.
I can run a phabricator database migration to convert everything to the new format. That could help with processing time if it makes the data smaller.
I found the missing indexes and put them in and tested over the weekend; processing time is back to what it was before the change. Some of the data looks normal on dev and some doesn't, but this may be due to project-specific norms. Production ran but the data doesn't look right at all. Will be following up with active users to debug.
I've fixed a number of obvious bugs in the new code; still quality-testing the results.
Thanks @JAufrecht. Would it be helpful to convert the data now to the new format? If there are still issues I can try to push them upstream.
It shouldn't make any difference; the code works with both formats. I haven't yet identified anything that can't be done with the new format, but I'm still checking.
I think this fix has passed enough spot testing to be generally considered resolved. Thanks, @mmodell.
The dump hasn't been updated since April 1, 2018. Perhaps it wasn't automated?
HEAD /other/misc/phabricator_public.dump HTTP/1.1 host: dumps.wikimedia.org HTTP/1.1 200 OK Server: nginx/1.13.6 Date: Mon, 23 Apr 2018 19:44:39 GMT Content-Type: application/octet-stream Content-Length: 1055482195 Last-Modified: Sun, 01 Apr 2018 02:39:40 GMT
Strange. When I look on phab1001, the dump file appears to be updated today:
twentyafterfour@phab1001:/srv/dumps$ ls -la total 1036988 drwxr-xr-x 2 root root 4096 Aug 8 2017 . drwxr-xr-x 8 root root 4096 Feb 5 15:22 .. -rw-r--r-- 1 root root 1061861418 Apr 23 02:36 phabricator_public.dump
And the cron job that copies the dump to the dataset server is enabled:
twentyafterfour@phab1001:/srv/dumps$ sudo cat /var/spool/cron/crontabs/root # DO NOT EDIT THIS FILE - edit the master and reinstall. # Puppet Name: phab_dump 10 4 * * * rsync -zpt --bwlimit=40000 -4 /srv/dumps/phabricator_public.dump dataset1001.wikimedia.org::other_misc/ >/dev/null 2>&1
I do see one thing messed up in that crontab though:
# Puppet Name: /srv/phab/tools/public_task_dump.py 0 2 * * * /srv/phab/tools/public_task_dump.py # Puppet Name: /srv/phab/tools/public_task_dump.py 1>/dev/null 0 2 * * * /srv/phab/tools/public_task_dump.py 1>/dev/null
That looks like the task dump is in there twice, at the same time. @Dzahn: What's the appropriate way to fix that crontab? Delete the file and let puppet recreate?
@20after4 Yes, deleting it and letting puppet recreate it is what i would do. Then we will see if it recreates, 0, 1 or 2 jobs.
Mentioned in SAL (#wikimedia-operations) [2018-04-23T22:37:50Z] <mutante> phab1001 - deleting duplicate cronjob for public_taskdump.py (the one that did not output to /dev/null) (T188149)
Deleted the one that did not log to /dev/null. Ran puppet; it did not recreate that.
Looks to me like somebody tried to debug by removing the /dev/null part and then puppet sees that as a separate job and recreates the one it is supposed to create and then there is nothing that removes the modified one.
Hopefully this already resolved the ticket.
@phab1001:~# crontab -l | grep public_task # Puppet Name: /srv/phab/tools/public_task_dump.py 1>/dev/null 0 2 * * * /srv/phab/tools/public_task_dump.py 1>/dev/null
According to T188646 they moved dumps.wikimedia.org from dataset1001 to labstore1006/7
Change 428540 had a related patch set uploaded (by Dzahn; owner: Dzahn):
[operations/puppet@production] phabricator: make dumps server configurable
Paladox is right. The location of dumps.wikimedia.org changed in the linked ticket above. But there is a hardcoded host name in the phabricator cron that rsyncs the dump file from phab1001 to dumps.wikimedia.org, which still uses dataset1001.
Uploaded a change to make it configurable and use the existing Hiera value described as:
# Dumps distribution server currently serving web and rsync mirror traffic # Also serves stat* hosts over nfs dumps_dist_active_web: labstore1007.wikimedia.org
@ArielGlenn Does that seem right? As opposed to other server names already in Hiera. (or both of the labstore servers)
I manually ran the rsync command to fix it and upload to the right server.
root@phab1001:~# rsync -v -zpt --bwlimit=40000 -4 /srv/dumps/phabricator_public.dump labstore1007.wikimedia.org::other_misc/ phabricator_public.dump sent 39,229,701 bytes received 227,470 bytes 1,547,340.04 bytes/sec total size is 1,061,861,418 speedup is 26.91
@JAufrecht It should look better now.
@Dzahn I see the fresh date in the file; starting a data run now to test the contents. Thanks.
@Dzahn The automated nightly dump doesn't seem to be working, as the file didn't update Tuesday or Wednesday:
HEAD /other/misc/phabricator_public.dump HTTP/1.1 host: dumps.wikimedia.org HTTP/1.1 200 OK Server: nginx/1.13.6 Date: Wed, 25 Apr 2018 20:05:47 GMT Content-Type: application/octet-stream Content-Length: 1061861418 Last-Modified: Mon, 23 Apr 2018 02:36:34 GMT Connection: keep-alive ETag: "5add46b2-3f4ab82a" Strict-Transport-Security: max-age=106384710; includeSubDomains; preload Accept-Ranges: bytes
There needs to be an rsync added to pull from the phab host to the active dumps.wikipedia.org, like the other rsync pull jobs for the web server. I have noted that on the relevant ticket: T188726 and will get to it shortly, though not today.
Change 429197 had a related patch set uploaded (by ArielGlenn; owner: ArielGlenn):
[operations/puppet@production] pull phabricator dumps from phab server to dumps web server
Change 429197 merged by ArielGlenn:
[operations/puppet@production] pull phabricator dumps from phab server to dumps web server
Going to leave this open til we are sure the dumps are actually picked up and published as expected.
Change 429666 had a related patch set uploaded (by ArielGlenn; owner: ArielGlenn):
[operations/puppet@production] fix up source dir for sync of phab dumps to public webserver
Change 429666 merged by ArielGlenn:
[operations/puppet@production] fix up source dir for sync of phab dumps to public webserver
Change 428540 abandoned by Dzahn:
phabricator: make dumps server configurable, rsync to labstore1007
Reason:
solved by Ariel in other ways - see ticket