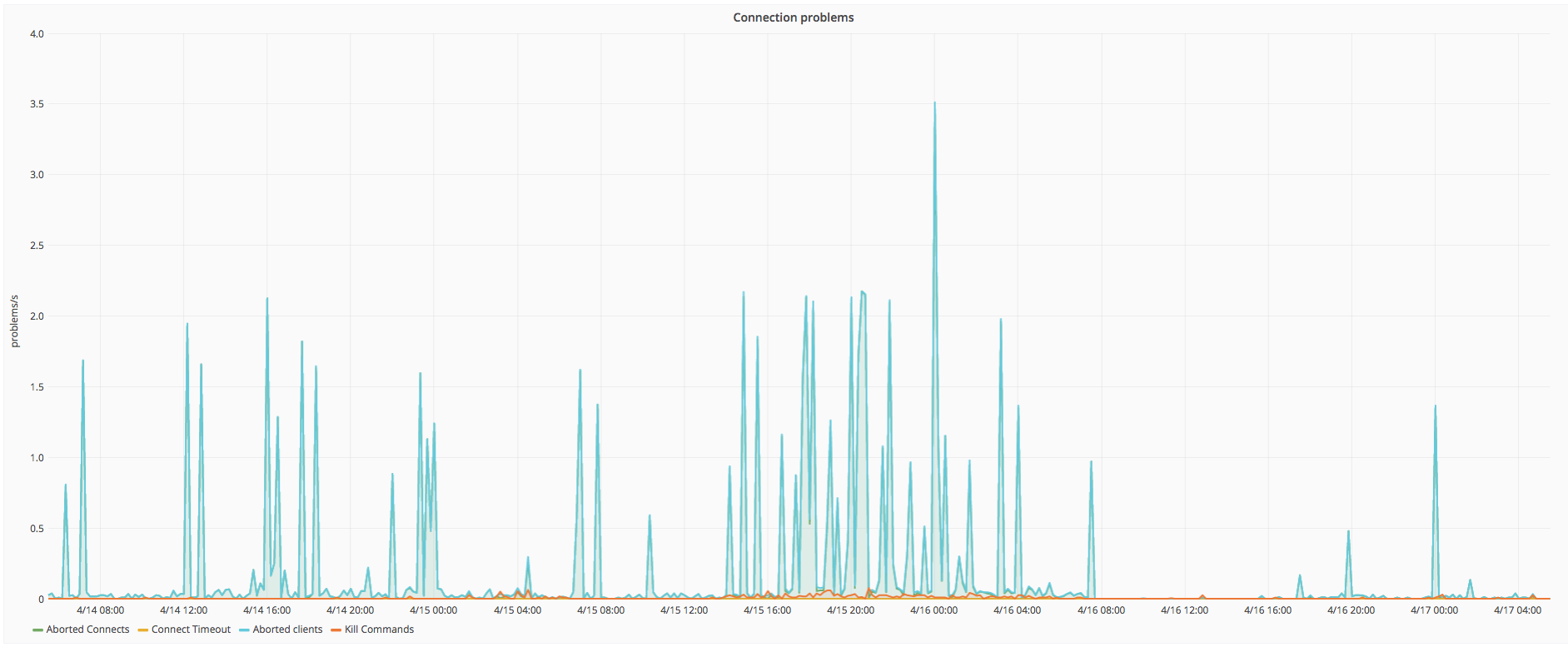
db1114 is having more connection errors than all other servers. https://logstash.wikimedia.org/goto/fe57fdbf7cdd60e3e2114ef27fa255b9
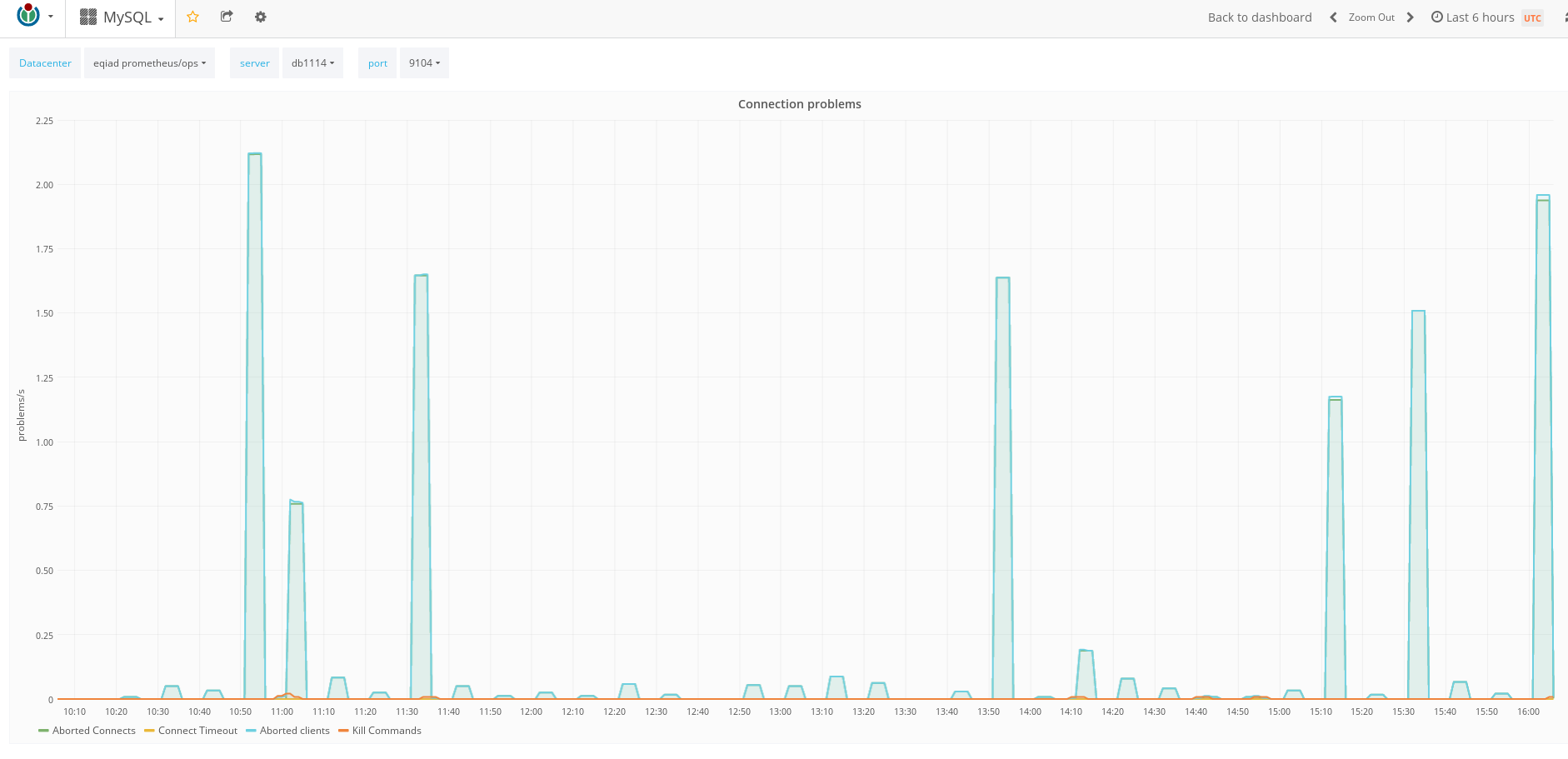
At first I thought it was some missing grants (eg. missing or using old_passwords), so I reloaded the grants. The errors keep happening.
Then I tried increasing the connection pool size, to see if there was too much delay on getting a connection. That also doesn't seem to affect.
Needs research, but I don't want to depool it because connections seem to succeed and execute queries, only a percentage (but a high ones) seems to fail to connect.
UPDATE of what have been seen/debugged
As there are lots of comments, this is a sum up of the fact that we have seen or debugged.
- The traffic spikes happen every 10 minutes, even to the second. These are examples of logged errors
05:20:10 05:30:10 05:40:12
This can been seen at: https://logstash.wikimedia.org/goto/f0353f4fa142a6484867fe3941baa340
And after a reboot they moved to XX:24:11 kind of timing: T191996#4133478
- While those spikes happen, the server drop packets - this has been confirmed by looking at the ifconfig output after every burst. T191996#4129334
- This has been mitigated by increasing the RX buffers and looks like it is not dropping anymore - but we still have connection errors: T191996#4138553
- While these errors happen. tcpdump doesn't show any traffic from terbium or tendril. Just traffic coming from mw hosts. Almost double the traffic during those seconds, but "normal" traffic apparently. T191996#4129117
- These errors only happen on db1114 while it servers API traffic. If the server is removed from API traffic and only servers main, this doesn't happen.
- This server is the only one suffering this. Neither db1066 or db1080 (other enwiki api slaves) suffer this. Not even when db1114 is depooled and they assume its traffic.
- db1114 is running stretch and mariadb 10.1. db1066 and db1080 run jessie and mariadb 10.0
- db1114 has the same schema definition in all the tables than db1066 and db1080.
- No HW errors found on the idrac
- Dropping traffic from einsteinium doesn't make errors to stop. So not related to that.
- Changed network cable - no effect T191996#4136190
- Went back to previous kernel+network driver - there was not a big significant change on the number of errors or dropped packets T191996#4133555
- Idle % looks like to drop below 80 during the events. These are two examples: T191996#4138764
- NICs smp affinity is distributed across cores: T191996#4139205
- The culprit was atop: T191996#4139494 T191996#4141772 T191996#4142677
Next tests:
- Use NIC #2 instead of #1 and monitor its behaviour
- Try to force eth speed instead of negotiating it
- Change switch port
- Change the host to a different rack and move it to a different "old" switch
- reimage the host to jessie