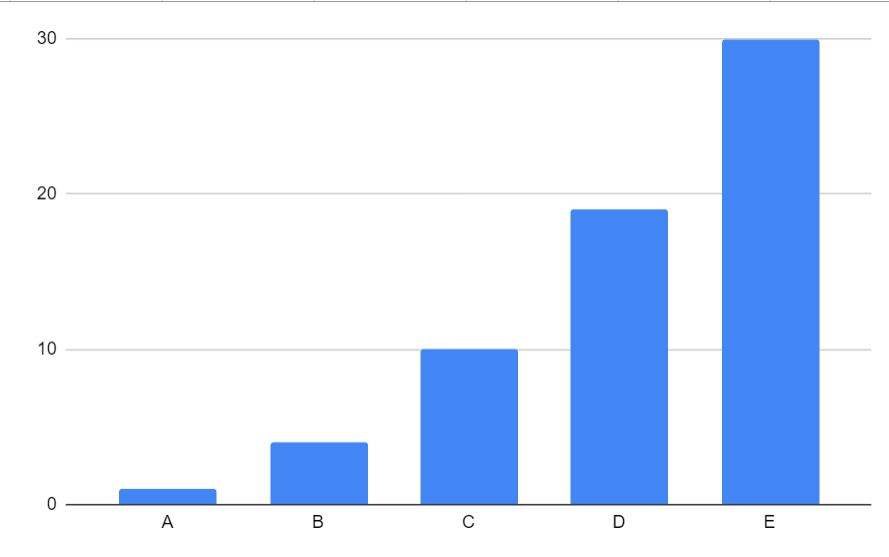
How do Wikipedians label articles by their quality level?
What levels are there and what processes do they follow when labeling articles for quality?
How do InfoBoxes work? Are they used like on English Wikipedia?
Are there "citation needed" templates? How do they work?