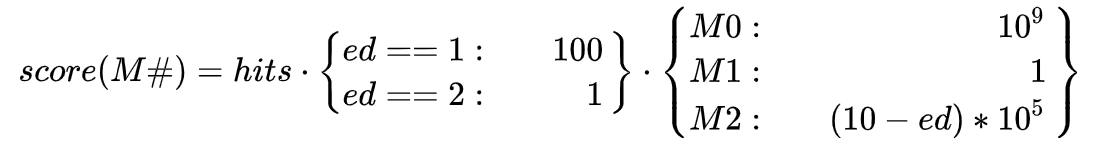As discovered in T232760, Method 1 (M1) suggestions can and should be improved before deployment or A/B testing. Tasks include:
- Improving the edit distance computation:
- special case costs
- discount cost for swaps (ab vs ba)
- discount cost for duplicate letters (ab vs abb)
- add increased cost for editing digits
- take tokens into account
- add per token edit limits
- add a penalty for differing numbers of tokens
- decreased token delta penalty if strings differ only by spaces
- add a penalty for changing the first letter of a token
- except for letter/space swaps (ab cdef vs abc def)
- Optimizations
- early termination when over the edit distance limit
- early termination when over the token delta limit
- Investigate using Jaccard similarity on characters in the strings to terminate early (can't use just string length because of duplicate letter discount)
- ensure support for 32-bit characters. (Ugh.)
- special case costs
- Add docs to Glent repo
- optimize penalties and discounts for the various cases above (based on M1 training data)
- Incorporate edit distance into M1 suggestion selection
- Investigate weighting of edit distance vs number of results
- Review SuggestionAggregator.java / score() for best way to combine M0, M1, M2
- Improve suggestion intake
- Filter M1 queries with search syntax in them (esp. negated queries)—T247469
- Set up minimal language analysis (standard tokenizer + ICU norm / lowercase) to queryNorm
- Review what ICU normalization covers and doesn't cover
- Deduplicate characters in queries (since duplicate letters are discounted)—dependent on T247898
-
Add filter at output (suggestion aggregator) to normalize chosen query (punct, whitespace, lowercase); re-use minimal language analysis from queryNorm[Dropping this, as there are some small potential pitfalls, and choosing suggestions partly based on frequency solves most of the problem.]