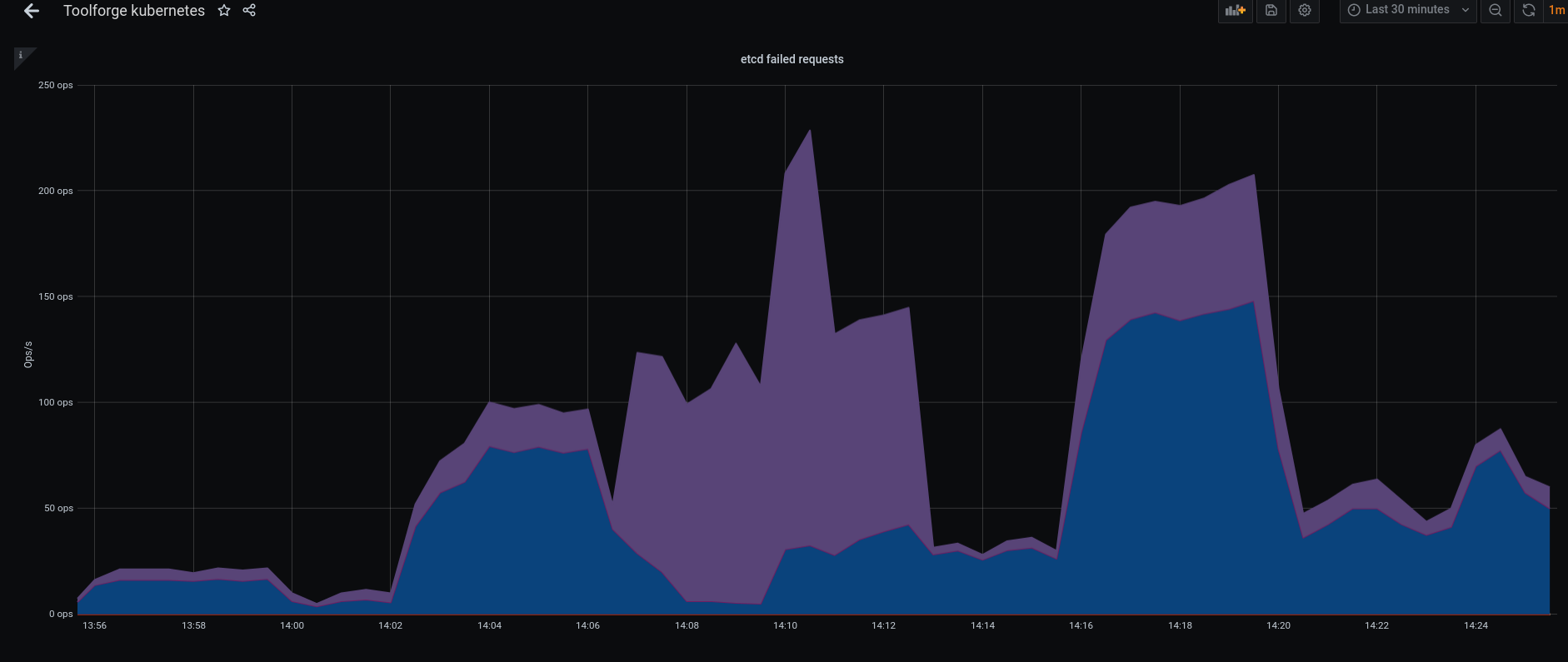
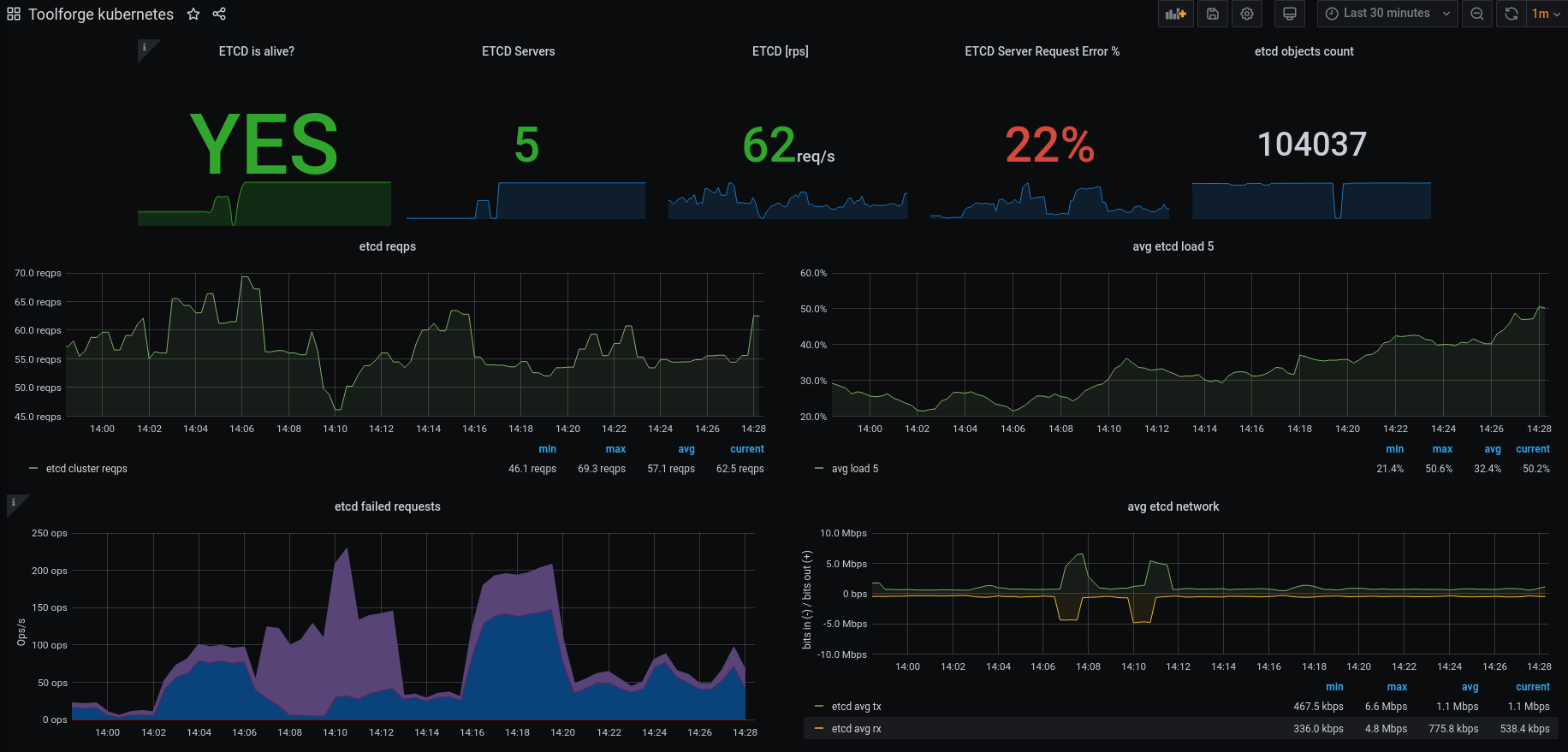
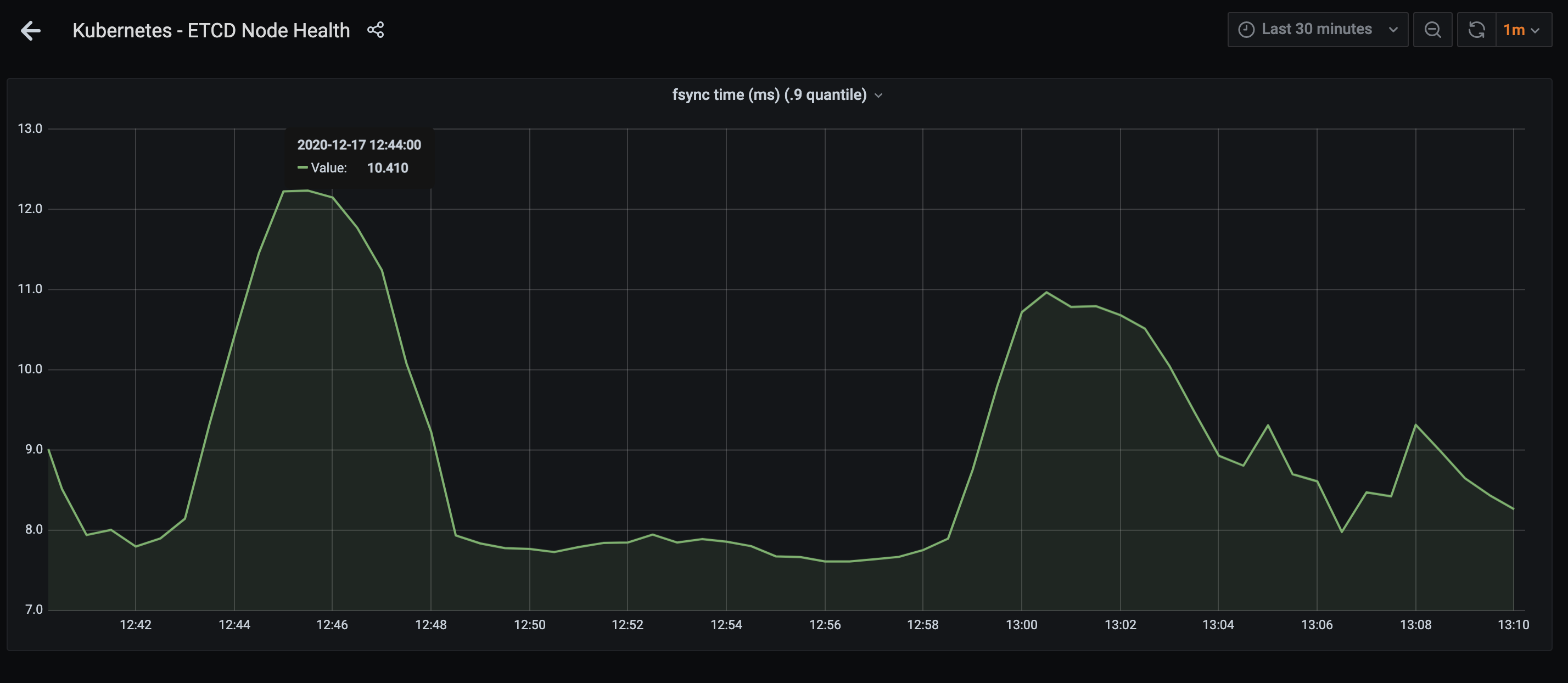
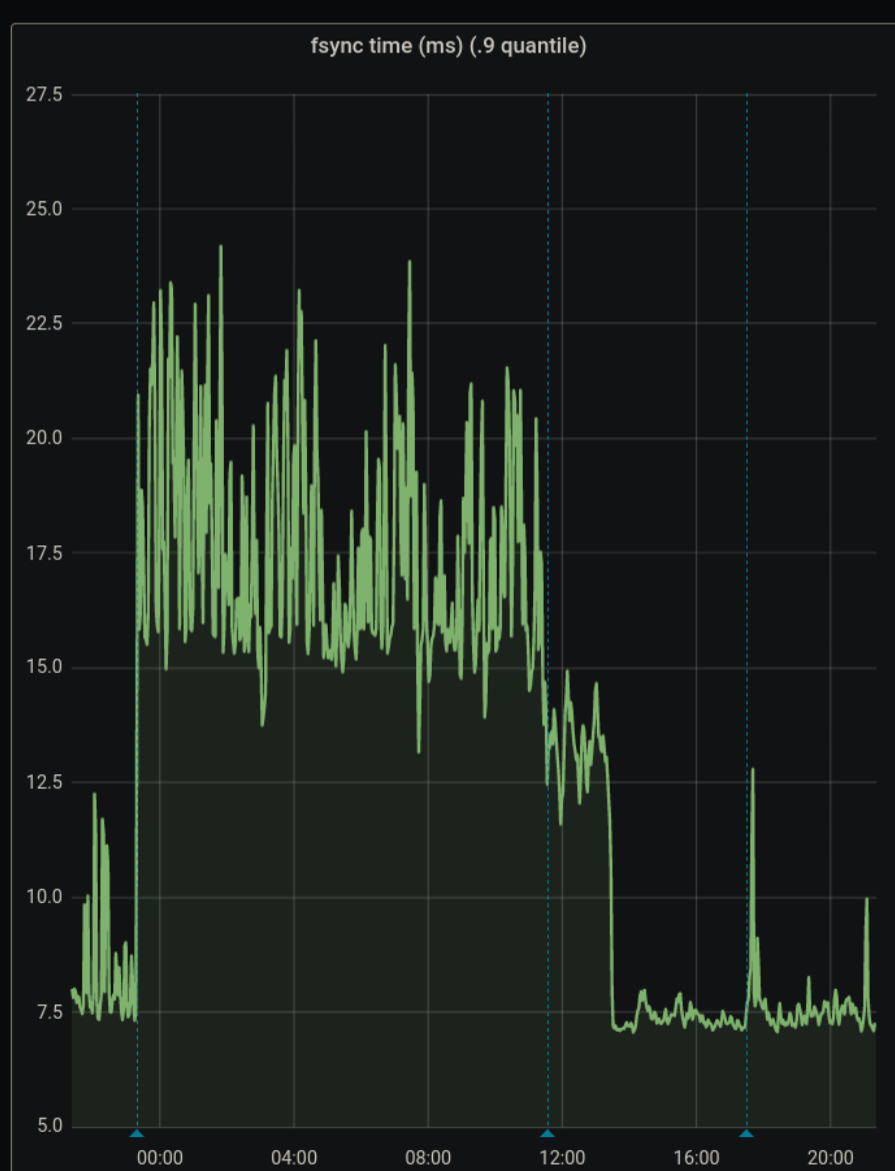
We've seen that improving the IO characteristics helps with the rather high traffic of the etcd cluster. However, it still experiences constant whole-number iowait and the k8s API has nearly full-second response times.
Investigate updating some of the characteristics of the cluster. It uses little storage, appears to have RAM to spare and seems pretty chill as far as CPU is concerned. It just ends up tripping over write requests, ioblocking and may need upgrades and application of server groups.
Since it has been determined that io is a big part of the issues here, this is work in parallel with T270305: Ceph performance tuning