Steps to Reproduce:
Go to https://ordia.toolforge.org/ or https://scholia.toolforge.org and possibly others.
Actual Results:
Sometimes get "502 Bad Gateway nginx/1.14.2".
Nothing relevant in uwsgi.log
The error seems to come in clusters. Perhaps it is related to load.
Expected Results:
The page should always get a proper response.
You can see that this is an systemic problem (though not a complete blackout when it happens) based on this graph:
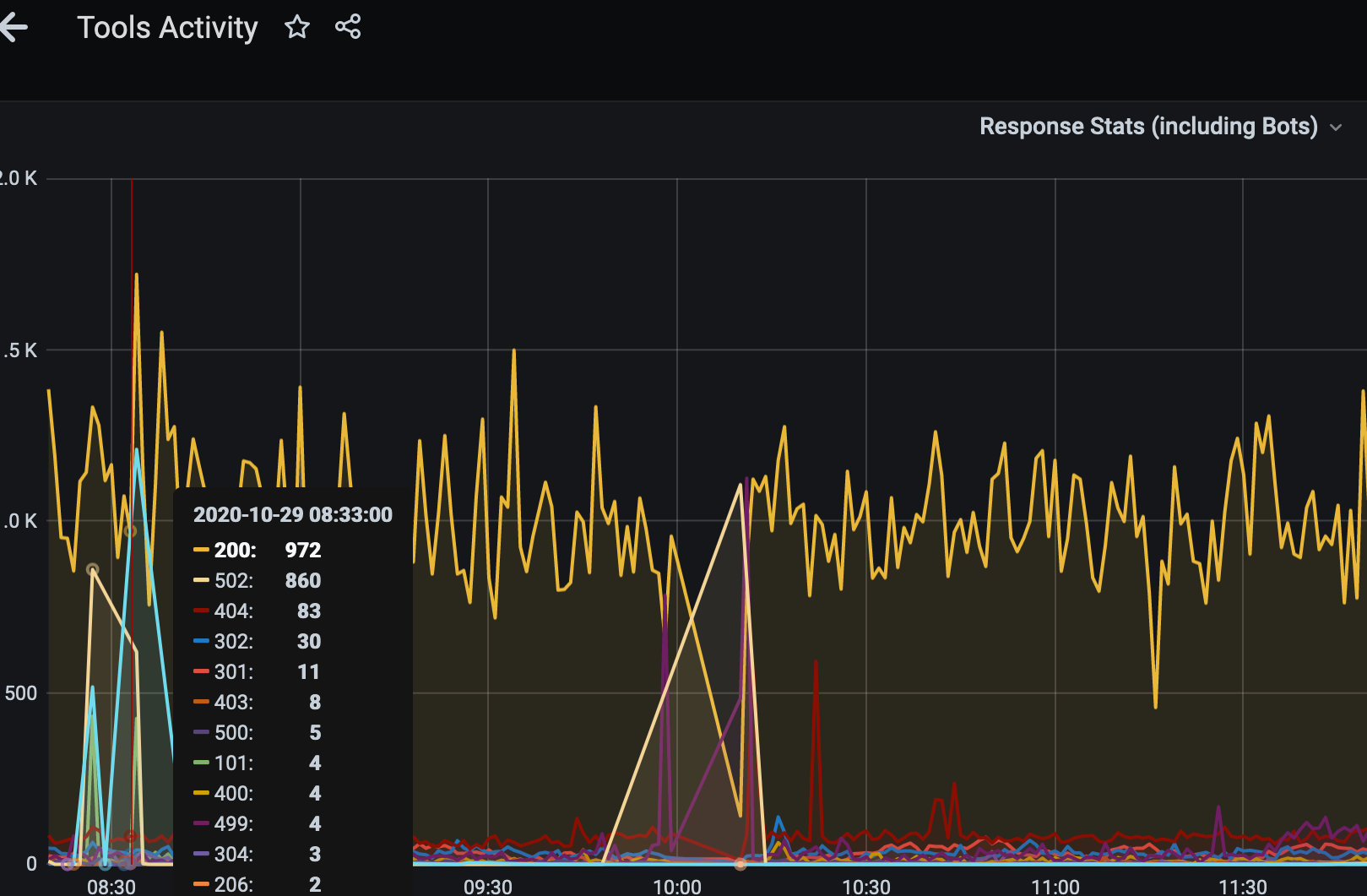
The second peak in that graph was an unrelated problem. The one with the tooltip describes the condition nicely. Lots of requests briefly get a 502 return status in a clump.
