As part of the Wikipedia Image Captioning competition, we want to release image files for training (and, later on, for testing). To do so, we will need to go through the following steps:
- Identify the subset of images we want to release from WIT:
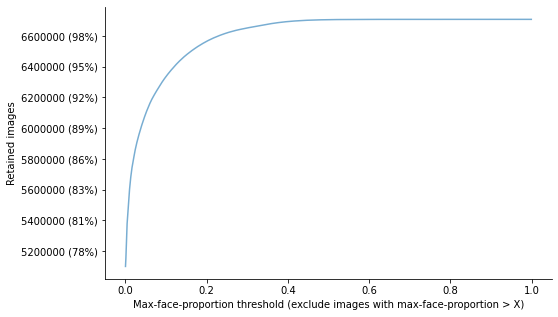
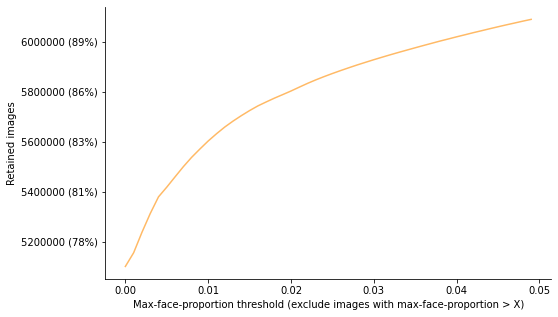
- exclude images with large faces
- exclude images that are candidate for deletion
- potentially harmful images
- Pull data from SWIFT to Hdfs:
- which resolution?
- which metadata?
- Get clearance for data release
- Can we release embedding as well?
- Release it for public usage
- where? analytics dumps?